Información de la versión: El código de esta página se probó en Stata 12.
La regresión de Poisson se utiliza para modelar variables de recuento.
Nota: El propósito de esta página es mostrar cómo usar varios comandos de análisis de datos. No cubre todos los aspectos del proceso de investigación que se espera que hagan los investigadores. En particular, no cubre la limpieza y verificación de datos, la verificación de supuestos, el diagnóstico de modelos o los posibles análisis de seguimiento.
Ejemplos de regresión de Poisson
Ejemplo 1. El número de personas muertas por patadas de mula o caballo en el ejército prusiano por año.Ladislaus Bortkiewicz recopiló datos de 20 volúmenes de Preussischen Statistik. Estos datos se recopilaron en 10 cuerpos del ejército prusiano a finales de 1800 en el transcurso de 20 años.
Ejemplo 2. El número de personas en fila frente a ti en la tienda de comestibles. Los predictores pueden incluir la cantidad de artículos que se ofrecen actualmente a un precio con descuento especial y si un evento especial (por ejemplo, un día festivo, un gran evento deportivo) está a tres o menos días de distancia.
Ejemplo 3. El número de premios ganados por estudiantes en una escuela secundaria. Los predictores del número de premios obtenidos incluyen el tipo de programa en el que el estudiante se matriculó (por ejemplo, vocacional, general o académico) y la puntuación en su examen final de matemáticas.
Descripción de los datos
Para fines ilustrativos, hemos simulado un conjunto de datos, por ejemplo, el 3 de arriba. En este ejemplo, num_awards es la variable de resultado e indica el número de premios ganados por los estudiantes en una escuela secundaria en un año, matemáticas es una variable predictora continua y representa los puntajes de los estudiantes en su examen final de matemáticas, y prog es una variable predictora categórica con tres niveles que indican el tipo de programa en el que se matricularon los estudiantes.
Comencemos cargando los datos y mirando algunas estadísticas descriptivas.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
Cada variable tiene 200 observaciones válidas y sus distribuciones parecen bastante razonables. En este particular, la media incondicional y la varianza de nuestra variable de resultado no son extremadamente diferentes.
Continuemos con nuestra descripción de las variables en este conjunto de datos. La tabla siguiente muestra el número promedio de premios por tipo de programa y parece sugerir que el tipo de programa es un buen candidato para predecir el número de premios, nuestra variable de resultado, porque el valor medio del resultado parece variar según el prog.
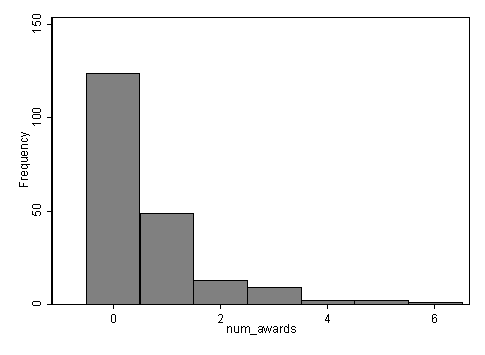
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
Métodos de análisis que puede considerar
A continuación se muestra una lista de algunos métodos de análisis que puede haber encontrado. Algunos de los métodos enumerados son bastante razonables, mientras que otros han caído en desgracia o tienen limitaciones.
- Regresión de Poisson-La regresión de Poisson se utiliza a menudo para modelar datos de recuento. La regresión de Poisson tiene varias extensiones útiles para modelos de conteo.
- Regresión binomial negativa: La regresión binomial negativa se puede utilizar para datos de recuento sobre dispersos, es decir, cuando la varianza condicional excede la media condicional. Se puede considerar como una generalización de la regresión de Poisson, ya que tiene la misma estructura media que la regresión de Poisson y tiene un parámetro adicional para modelar la dispersión excesiva. Si la distribución condicional de la variable de resultado está sobre dispersa, es probable que los intervalos de confianza para la regresión binomial negativa sean más estrechos en comparación con los de una regresión de Poisson.
- Modelo de regresión inflado cero: los modelos inflados cero intentan tener en cuenta el exceso de ceros. En otras palabras, se cree que existen dos tipos de ceros en los datos, «ceros verdaderos» y «ceros en exceso». Los modelos inflados a cero estiman dos ecuaciones simultáneamente, una para el modelo de conteo y otra para el exceso de ceros.
- Las variables de resultado de recuento de regresión OLS a veces se transforman en registros y se analizan mediante regresión OLS. Surgen muchos problemas con este enfoque, incluida la pérdida de datos debido a valores indefinidos generados al tomar el registro de cero (que es indefinido) y estimaciones sesgadas.
Regresión de Poisson
A continuación utilizamos el comando de poisson para estimar un modelo de regresión de Poisson. El prog i. before indica que es una variable de factor (i. e., variable categórica), y que debe incluirse en el modelo como una serie de variables indicadoras.
Utilizamos la opción vce(robusta) para obtener errores estándar robustos para las estimaciones de parámetros, según lo recomendado por Cameron y Trivedi (2009) para controlar la violación leve de los supuestos subyacentes.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
La prueba de chi-cuadrado de dos grados de libertad indica que el prog, tomado en conjunto, es un predictor estadísticamente significativo de num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
Para ayudar a evaluar el ajuste del modelo, el comando estat gof se puede usar para obtener la prueba de chi cuadrado de bondad de ajuste. Esto no es una prueba de los coeficientes del modelo (que vimos en la información del encabezado), sino una prueba del formulario del modelo: ¿El formulario del modelo de Poisson se ajusta a nuestros datos?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
Concluimos que el modelo se ajusta razonablemente bien porque la prueba de chi cuadrado de bondad de ajuste no es estadísticamente significativa. Si la prueba hubiera sido estadísticamente significativa, indicaría que los datos no se ajustan bien al modelo. En esa situación, podemos tratar de determinar si hay variables predictoras omitidas, si nuestra suposición de linealidad se mantiene y/o si hay un problema de dispersión excesiva.
A veces, es posible que queramos presentar los resultados de regresión como ratios de tasa de incidentes, podemos usar la opción irr. Estos valores de TIR son iguales a nuestros coeficientes de la salida anterior exponenciada.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
El resultado anterior indica que la tasa de incidentes de 2.prog es 2,96 veces la tasa de incidentes para el grupo de referencia (1.prog). Del mismo modo, la tasa de incidentes de 3.prog es 1,45 veces la tasa de incidentes para el grupo de referencia que mantiene constantes las otras variables. El cambio porcentual en la tasa de incidentes de num_awards es un aumento del 7% por cada aumento de unidad en matemáticas.
Recordar la forma de nuestra ecuación de modelo:
log (num_awards)=Intercept + b1(prog=2) + b2(prog = 3) + b3math.
Esto implica:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
Los coeficientes tienen un efecto aditivo en el registro de la(s) escala y la TIR tiene un efecto multiplicativo en la escala y.
Para obtener información adicional sobre las diversas métricas en las que se pueden presentar los resultados, y la interpretación de las mismas, consulte Modelos de Regresión para Variables Dependientes Categóricas Utilizando Stata, Segunda Edición de J. Scott Long y Jeremy Freese (2006).
Para entender mejor el modelo, podemos usar el comando margins. A continuación, utilizamos el comando margins para calcular los recuentos previstos en cada nivel deprog, manteniendo todas las demás variables (en este ejemplo, matemáticas) en el modelo en sus valores medios.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
En la salida anterior, vemos que el número previsto de eventos para el nivel 1 de prog es de aproximadamente .21, manteniendo las matemáticas en su media. El número previsto de eventos para el nivel 2 de prog es mayor en.62, y el número previsto de eventos para el nivel 3 de prog es de aproximadamente .31. Tenga en cuenta que el recuento predicho del nivel 2 de prog es (.6249446/.211411) = 2,96 veces más alto que el recuento predicho para el nivel 1 de prog. Esto coincide con lo que vimos en la tabla de salida de la TIR.
A continuación obtendremos los recuentos predichos para valores matemáticos que van de 35 a 75 en incrementos de 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
La tabla anterior muestra que con el prog en sus valores observados y la matemática en 35 para todas las observaciones, el recuento promedio predicho (o el número promedio de premios) es de aproximadamente .13; cuando matemáticas = 75, el conteo promedio predicho es de aproximadamente 2.17. Si comparamos los conteos predichos en matemáticas = 35 y matemáticas = 45, podemos ver que la proporción es (.2644714/.1311326) = 2.017. Esto coincide con la TIR de 1.0727 para un cambio de 10 unidades: 1.0727^10 = 2.017.
El comando fitstat escrito por el usuario (así como los comandos estat de Stata) se pueden usar para obtener información adicional que puede ser útil si desea comparar modelos. Puede escribir search fitstat para descargar este programa (consulte ¿Cómo puedo usar el comando search para buscar programas y obtener ayuda adicional? para obtener más información sobre el uso de la búsqueda).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
Puede graficar el número previsto de eventos con los comandos a continuación. El gráfico indica que la mayoría de los premios se predicen para aquellos en el programa académico (prog = 2), especialmente si el estudiante tiene una puntuación alta en matemáticas. El número más bajo de premios previstos es para aquellos estudiantes en el programa general ( prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
Cosas a tener en cuenta
- Si la sobredispersión parece ser un problema, deberíamos primero verifique si nuestro modelo está especificado adecuadamente, como variables omitidas y formas funcionales. Por ejemplo, si omitimos la variable predictora progin en el ejemplo anterior, nuestro modelo parecería tener un problema con la dispersión excesiva. En otras palabras, un modelo mal especificado podría presentar un síntoma como un problema de dispersión excesiva.
- Asumiendo que el modelo está especificado correctamente, es posible que desee comprobar si existe una dispersión excesiva. Hay varias formas de hacer esto, incluida la prueba de razón de verosimilitud del parámetro alfa de dispersión excesiva, ejecutando el mismo modelo de regresión utilizando la distribución binomial negativa (nbreg).
- Una causa común de dispersión excesiva es el exceso de ceros, que a su vez son generados por un proceso de generación de datos adicional. En esta situación, se debe considerar el modelo de inflación cero.
- Si el proceso de generación de datos no permite ningún 0 (como el número de días pasados en el hospital), entonces un modelo truncado cero puede ser más apropiado.
- Los datos de conteo a menudo tienen una variable de exposición, que indica el número de veces que podría haber ocurrido el evento. Esta variable debe ser incorporada en un modelo de Poisson con el uso de la opción exp ().
- La variable de resultado en una regresión de Poisson no puede tener números negativos, y la exposición no puede tener 0s.
- En Stata, un modelo de Poisson se puede estimar mediante el comando glm con el enlace de registro y la familia de Poisson.
- Necesitará usar el comando glm para obtener los residuos y verificar otras suposiciones del modelo de Poisson (vea Cameron y Trivedi (1998) y Dupont (2002) para más información).
- Existen muchas medidas diferentes de pseudo-R-cuadrado. Todos ellos intentan proporcionar información similar a la proporcionada por R-cuadrado en la regresión OLS, aunque ninguno de ellos puede interpretarse exactamente como se interpreta R-cuadrado en la regresión OLS. Para una discusión de varios pseudo-R-cuadrados, vea Long and Freese (2006) o nuestra página de preguntas frecuentes ¿Qué son pseudo-R-cuadrados?.
- La regresión de Poisson se estima mediante la estimación de máxima verosimilitud. Por lo general, requiere un gran tamaño de muestra.
Véase también
- Salida anotada para el comando poisson
- Preguntas frecuentes de Stata: ¿Cómo puedo usar countfit al elegir un modelo de conteo?
- Manual en línea de Stata
- poisson
- Preguntas frecuentes de Stata
- ¿Cómo se calculan los errores estándar y los intervalos de confianza para los ratios de tasa de incidencia (RRP) de poisson y nbreg?
- Cameron, A. C. y Trivedi, P. K. (2009). Microeconometría Utilizando Stata. College Station, TX: Stata Press.Cameron, A.C. y Trivedi, P. K. (1998). Análisis de Regresión de Datos de Conteo. Nueva York: Cambridge Press.
- Cameron, A.C. Charla sobre Avances en Regresión de Datos de Recuento para el Taller de Estadísticas Aplicadas, 28 de marzo de 2009.http://cameron.econ.ucdavis.edu/racd/count.html.Dupont, W. D. (2002). Modelado Estadístico para Investigadores Biomédicos: Una Introducción Sencilla al Análisis de Datos Complejos. Nueva York: Cambridge Press.long, J. S. (1997). Modelos de Regresión para Variables Dependientes Categóricas y Limitadas.Thousand Oaks, CA: Sage Publications.
- Long, J. S. y Freese, J. (2006). Modelos de Regresión para Variables Dependientes Categóricas Utilizando Stata, Segunda Edición. College Station, TX: Stata Press.