por William W Wold
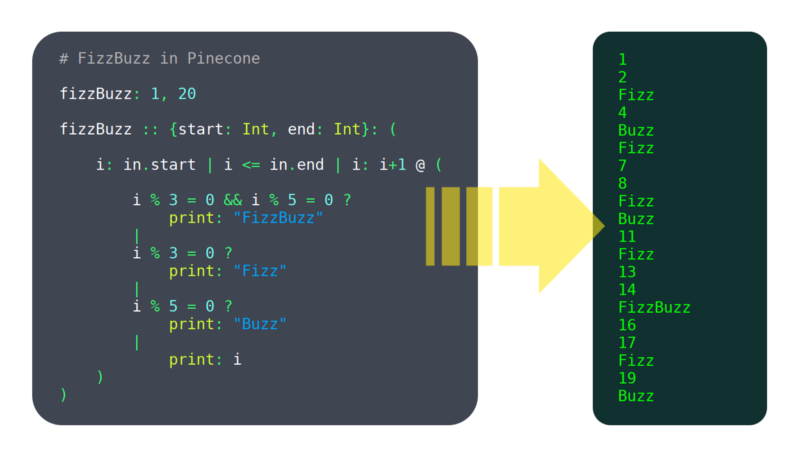
en los últimos 6 meses, he estado trabajando en un lenguaje de programación llamado Pino. No lo llamaría maduro todavía, pero ya tiene suficientes funciones que funcionan para ser utilizable, como:
- variables
- funciones
- estructuras definidas por el usuario
Si estás interesado en él, echa un vistazo a la página de destino de Pinecone o a su repositorio de GitHub.
No soy un experto. Cuando comencé este proyecto, no tenía ni idea de lo que estaba haciendo, y todavía no lo hago. He tomado cero clases de creación de idiomas, solo he leído un poco sobre él en línea y no he seguido muchos de los consejos que me han dado.
Y aún así, hice un lenguaje completamente nuevo. Y funciona. Así que debo estar haciendo algo bien.
En este post, me sumergiré bajo el capó y te mostraré el pipeline que utiliza Pinecone (y otros lenguajes de programación) para convertir el código fuente en magia.
También mencionaré algunas de las compensaciones que he tenido que hacer y por qué tomé las decisiones que tomé.
Este no es de ninguna manera un tutorial completo sobre cómo escribir un lenguaje de programación, pero es un buen punto de partida si tienes curiosidad por el desarrollo del lenguaje.
Primeros pasos
«No tengo absolutamente ni idea de dónde empezaría» es algo que escucho mucho cuando le digo a otros desarrolladores que estoy escribiendo un idioma. En caso de que esa sea tu reacción, ahora revisaré algunas decisiones iniciales que se toman y los pasos que se toman al comenzar cualquier nuevo idioma.
Compilado vs Interpretado
Hay dos tipos principales de lenguajes: compilado e interpretado:
- Un compilador calcula todo lo que hará un programa, lo convierte en» código máquina » (un formato que la computadora puede ejecutar muy rápido), y luego lo guarda para ejecutarlo más tarde.
- Un intérprete recorre el código fuente línea por línea, descubriendo lo que está haciendo a medida que avanza.
Técnicamente cualquier lenguaje puede ser compilado o interpretado, pero uno u otro generalmente tiene más sentido para un lenguaje específico. En general, la interpretación tiende a ser más flexible, mientras que la compilación tiende a tener un mayor rendimiento. Pero esto es solo arañar la superficie de un tema muy complejo.
Valoro mucho el rendimiento, y vi una falta de lenguajes de programación que sean a la vez de alto rendimiento y orientados a la simplicidad, así que opté por compilado para Pinecone.
Esta fue una decisión importante a tomar desde el principio, porque muchas decisiones de diseño de lenguaje se ven afectadas por ella (por ejemplo, la escritura estática es un gran beneficio para los lenguajes compilados, pero no tanto para los interpretados).
A pesar de que Pinecone fue diseñado con la compilación en mente, tiene un intérprete completamente funcional que fue la única manera de ejecutarlo por un tiempo. Hay varias razones para ello, que explicaré más adelante.
Elegir un lenguaje
Sé que es un poco meta, pero un lenguaje de programación es en sí mismo un programa, y por lo tanto necesita escribirlo en un lenguaje. Elegí C++ por su rendimiento y su gran conjunto de características. Además, realmente disfruto trabajando en C++.
Si está escribiendo un lenguaje interpretado, tiene mucho sentido escribirlo en uno compilado (como C, C++ o Swift) porque la interpretación perdida en el lenguaje de su intérprete y del intérprete que está interpretando a su intérprete se compondrá.
Si planea compilar, un lenguaje más lento (como Python o JavaScript) es más aceptable. El tiempo de compilación puede ser malo, pero en mi opinión no es tan importante como el tiempo de ejecución malo.
Diseño de alto nivel
Un lenguaje de programación generalmente está estructurado como una canalización. Es decir, tiene varias etapas. Cada etapa tiene datos formateados de una manera específica y bien definida. También tiene funciones para transformar datos de cada etapa a la siguiente.
La primera etapa es una cadena que contiene todo el archivo de origen de entrada. La etapa final es algo que se puede correr. Todo esto se aclarará a medida que avanzamos por la tubería de piña paso a paso.
Gramatical

El primer paso en la mayoría de los lenguajes de programación es gramatical, o encadenamiento. ‘Lex’ es la abreviatura de análisis léxico, una palabra muy elegante para dividir un montón de texto en fichas. La palabra ‘tokenizador’ tiene mucho más sentido, pero ‘lexer’ es tan divertido de decir que la uso de todos modos.
Tokens
Un token es una pequeña unidad de un idioma. Un token puede ser un nombre de variable o función (también conocido como identificador), un operador o un número.
Tarea del Lexer
Se supone que el lexer toma una cadena que contiene un archivo completo de código fuente y escupe una lista que contiene cada token.
Las etapas futuras de la canalización no se referirán al código fuente original, por lo que el lexer debe producir toda la información que necesitan. La razón de este formato de canalización relativamente estricto es que el lexer puede realizar tareas como eliminar comentarios o detectar si algo es un número o identificador. Desea mantener esa lógica encerrada dentro del léxico, para que no tenga que pensar en estas reglas al escribir el resto del lenguaje, y para que pueda cambiar este tipo de sintaxis en un solo lugar.
Flex
El día que empecé el idioma, lo primero que escribí fue un léxico simple. Poco después, comencé a aprender sobre herramientas que supuestamente harían que lexing fuera más simple y menos defectuoso.
La herramienta predominante es Flex, un programa que genera lexers. Le das un archivo que tiene una sintaxis especial para describir la gramática del idioma. A partir de eso, genera un programa en C que mezcla una cadena y produce la salida deseada.
Mi decisión
Opté por conservar el lexer que escribí por el momento. Al final, no vi beneficios significativos de usar Flex, al menos no lo suficiente como para justificar agregar una dependencia y complicar el proceso de compilación.
Mi lexer tiene solo unos cientos de líneas y rara vez me da problemas. Rodar mi propio lexer también me da más flexibilidad, como la capacidad de agregar un operador al idioma sin editar varios archivos.
Análisis

La segunda etapa de la tubería es el analizador. El analizador convierte una lista de tokens en un árbol de nodos. Un árbol utilizado para almacenar este tipo de datos se conoce como Árbol de Sintaxis Abstracta, o AST. Al menos en Piña, el AST no tiene información sobre los tipos o qué identificadores son cuáles. Es simplemente fichas estructuradas.
Funciones del analizador
El analizador añade estructura a la lista ordenada de tokens que produce el analizador léxico. Para evitar ambigüedades, el analizador debe tener en cuenta los paréntesis y el orden de las operaciones. Simplemente analizar operadores no es terriblemente difícil, pero a medida que se agregan más construcciones de lenguaje, el análisis puede volverse muy complejo.
Bison
Nuevamente, hubo una decisión que involucró a una biblioteca de terceros. La biblioteca de análisis predominante es Bison. El bisonte funciona muy parecido a Flex. Escribes un archivo en un formato personalizado que almacena la información gramatical, luego Bison lo usa para generar un programa en C que hará tu análisis. No elegí usar bisontes.
Por qué la personalización es mejor
Con el lexer, la decisión de usar mi propio código fue bastante obvia. Un lexer es un programa tan trivial que no escribir el mío se sentía casi tan tonto como no escribir mi propio ‘teclado izquierdo’.
Con el analizador, es un asunto diferente. Mi analizador de piña tiene actualmente 750 líneas de largo, y he escrito tres de ellas porque las dos primeras eran basura.
Originalmente tomé mi decisión por varias razones, y aunque no ha ido completamente sin problemas, la mayoría de ellas son ciertas. Los principales son los siguientes:
- Minimizar el cambio de contexto en el flujo de trabajo: el cambio de contexto entre C++ y Piña es suficientemente malo sin incluir la gramática de Bison gramática
- Mantener la compilación simple: cada vez que cambia la gramática, Bison debe ejecutarse antes de la compilación. Esto se puede automatizar, pero se convierte en un dolor al cambiar entre sistemas de construcción.
- Me gusta construir cosas geniales: No hice piña porque pensé que sería fácil, así que ¿por qué delegaría un papel central cuando podría hacerlo yo mismo? Un analizador sintáctico personalizado puede no ser trivial, pero es completamente factible.
Al principio no estaba completamente seguro de si iba por un camino viable, pero me dio confianza lo que Walter Bright (un desarrollador de una versión temprana de C++ y el creador del lenguaje D) tenía que decir sobre el tema:
«Algo más controvertido, no me molestaría en perder el tiempo con generadores lexer o parser y otros compiladores llamados «compiladores».»Son una pérdida de tiempo. Escribir un lexer y un analizador sintáctico es un pequeño porcentaje del trabajo de escribir un compilador. Usar un generador llevará casi tanto tiempo como escribir uno a mano, y te casará con el generador (lo que importa cuando portes el compilador a una nueva plataforma). Y los generadores también tienen la desafortunada reputación de emitir pésimos mensajes de error.»
Árbol de Acción
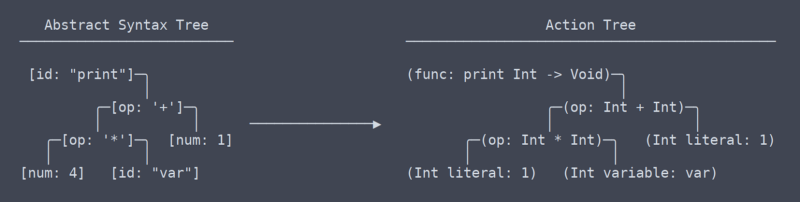
ahora Hemos dejado el área común, universal de términos, o al menos yo no sé cuáles son los términos más. Desde mi punto de vista, lo que llamo el ‘árbol de acción’ es más parecido a la IR (representación intermedia) de LLVM.
Hay una diferencia sutil pero muy significativa entre el árbol de acciones y el árbol de sintaxis abstracta. Me tomó bastante tiempo descubrir que incluso debería haber una diferencia entre ellos (lo que contribuyó a la necesidad de reescribir el analizador).
Árbol de acciones vs AST
En pocas palabras, el árbol de acciones es el AST con contexto. Ese contexto es información como qué tipo devuelve una función, o que dos lugares en los que se usa una variable están de hecho usando la misma variable. Debido a que necesita averiguar y recordar todo este contexto, el código que genera el árbol de acciones necesita muchas tablas de búsqueda de espacios de nombres y otros objetos.
Ejecutar el Árbol de acciones
Una vez que tenemos el árbol de acciones, ejecutar el código es fácil. Cada nodo de acción tiene una función ‘execute’ que toma alguna entrada, hace lo que la acción debe (incluyendo posiblemente llamar a la sub acción) y devuelve la salida de la acción. Este es el intérprete en acción.
Opciones de Compilación
«Pero espera!»Te oigo decir», ¿no se supone que la piña es compilada?»Sí, lo es. Pero compilar es más difícil que interpretar. Hay algunos enfoques posibles.
Construir mi propio compilador
Esto me pareció una buena idea al principio. Me encanta hacer cosas yo mismo, y he estado ansioso por una excusa para ser bueno en el montaje.
Desafortunadamente, escribir un compilador portátil no es tan fácil como escribir código máquina para cada elemento del lenguaje. Debido a la cantidad de arquitecturas y sistemas operativos, es poco práctico para cualquier individuo escribir un backend de compilador multiplataforma.
Incluso los equipos detrás de Swift, Rust y Clang no quieren molestarse con todo por su cuenta, por lo que en su lugar todos usan
LLVM
LLVM es una colección de herramientas de compilación. Es básicamente una biblioteca que convertirá tu lenguaje en un binario ejecutable compilado. Parecía la elección perfecta, así que me metí de lleno. Lamentablemente, no comprobé la profundidad del agua e inmediatamente me ahogé.
LLVM, aunque no es un lenguaje ensamblador duro, es una biblioteca gigantesca y compleja. No es imposible de usar, y tienen buenos tutoriales, pero me di cuenta de que tendría que practicar un poco antes de estar listo para implementar completamente un compilador de Piña con él.
Transpilar
Quería una especie de Piña compilada y la quería rápida, así que recurrí a un método que sabía que podía hacer que funcionara: transpilar.
Escribí un Pinecone para el transpiler de C++, y agregué la capacidad de compilar automáticamente la fuente de salida con GCC. Esto funciona actualmente para casi todos los programas de piña (aunque hay algunos casos extremos que lo rompen). No es una solución particularmente portátil o escalable, pero funciona por el momento.
Futuro
Asumiendo que continúo desarrollando Pinecone, Obtendrá soporte para compilación de LLVM tarde o temprano. Sospecho que no importa cuánto trabajo en él, el transpilador nunca será completamente estable y los beneficios de LLVM son numerosos. Es solo cuestión de cuándo tengo tiempo para hacer algunos proyectos de muestra en LLVM y acostumbrarme.
Hasta entonces, el intérprete es ideal para programas triviales y el transpilado en C++ funciona para la mayoría de las cosas que necesitan más rendimiento.
Conclusión
Espero haber hecho los lenguajes de programación un poco menos misteriosos para ti. Si quieres hacer uno tú mismo, lo recomiendo encarecidamente. Hay un montón de detalles de implementación que resolver, pero el esquema aquí debería ser suficiente para que te pongas en marcha.
Aquí está mi consejo de alto nivel para comenzar (recuerde, realmente no sé lo que estoy haciendo, así que tómelo con un grano de sal):
- Si tiene dudas, interprete. Los lenguajes interpretados son generalmente más fáciles de diseñar, construir y aprender. No te estoy desalentando de escribir una compilada si sabes que eso es lo que quieres hacer, pero si estás en la valla, yo iría interpretado.
- Cuando se trata de lexers y analizadores, haz lo que quieras. Hay argumentos válidos a favor y en contra de escribir el suyo propio. Al final, si piensas en tu diseño e implementas todo de una manera sensata, realmente no importa.
- Aprender de la canalización con la que terminé. Mucho ensayo y error se invirtió en el diseño de la tubería que tengo ahora. He intentado eliminar ASTs, ASTs que se convierten en árboles de acciones en su lugar, y otras ideas terribles. Esta tubería funciona, así que no la cambies a menos que tengas una buena idea.
- Si no tienes el tiempo o la motivación para implementar un lenguaje complejo de propósito general, intenta implementar un lenguaje esotérico como Brainfuck. Estos intérpretes pueden ser tan cortos como unos pocos cientos de líneas.
Tengo muy pocos remordimientos cuando se trata del desarrollo de piña. Tomé una serie de malas decisiones en el camino, pero he reescrito la mayor parte del código afectado por tales errores.
En este momento, la piña está en un estado lo suficientemente bueno como para funcionar bien y poder mejorarse fácilmente. Escribir piña ha sido una experiencia enormemente educativa y agradable para mí, y apenas está empezando.