Lineaarinen Diskriminanttianalyysi tai normaali Diskriminanttianalyysi tai Diskriminanttifunktioanalyysi on dimensionaalisuuden vähentämistekniikka, jota käytetään yleisesti valvotuissa luokitteluongelmissa. Sitä käytetään ryhmien erojen mallintamiseen eli kahden tai useamman luokan erottamiseen toisistaan. Sitä käytetään projisoimaan korkeamman ulottuvuuden avaruuden ominaisuudet alemman ulottuvuuden avaruuteen.
esimerkiksi meillä on kaksi luokkaa ja ne on erotettava tehokkaasti toisistaan. Luokilla voi olla useita ominaisuuksia. Käyttämällä vain yksi ominaisuus luokitella niitä voi johtaa joitakin päällekkäisyyksiä, kuten alla olevassa kuvassa. Niin, me pitää lisätä useita ominaisuuksia asianmukaisen luokituksen.

esimerkki:
Oletetaan, että meillä on kaksi datapisteiden joukkoa, jotka kuuluvat kahteen eri luokkaan, jotka haluamme luokitella. Kuten annetussa 2D-kaaviossa on esitetty, kun datapisteet piirretään 2D-tasolle, ei ole suoraa viivaa, joka voi erottaa datapisteiden kaksi luokkaa kokonaan. Näin ollen tässä tapauksessa käytetään Lda: ta (Lineaarinen Diskriminanttianalyysi), joka pelkistää 2D-kuvaajan 1D-kuvaajaksi maksimoidakseen näiden kahden luokan erotettavuuden.
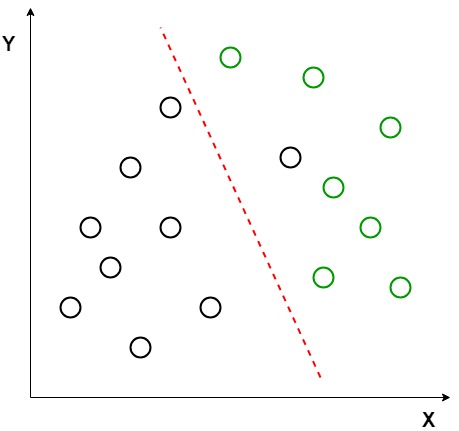
tässä lineaarisessa Diskriminanttianalyysissä käytetään sekä akseleita (X ja Y) uuden akselin luomiseen ja projisoidaan dataa uudelle akselille siten, että voidaan maksimoida kahden kategorian erottelu ja siten vähentää 2D-kuvaaja 1D-kuvaajaksi.
LDA käyttää kahta kriteeriä luodakseen uuden akselin:
- maksimoi kahden luokan keskiarvojen välinen etäisyys.
- minimoi vaihtelu kunkin luokan sisällä.
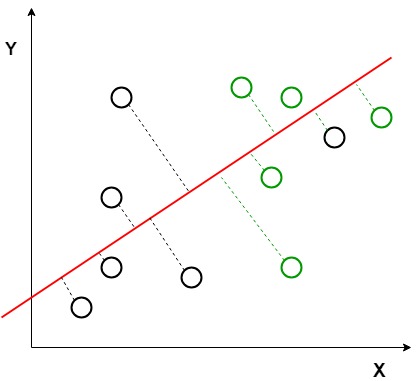
yllä olevasta kuvaajasta voidaan nähdä, että 2D-kuvaajaan syntyy ja piirretään Uusi akseli (punaisella) siten, että se maksimoi kahden luokan keskiarvojen välisen etäisyyden ja minimoi vaihtelun kunkin luokan sisällä. Yksinkertaisesti sanottuna tämä uusi akseli lisää näiden kahden luokan DTLA-pisteiden välistä eroa. Kun tämä uusi akseli on muodostettu edellä mainittuja kriteerejä käyttäen, kaikki luokkien tietopisteet piirretään tälle uudelle akselille, ja ne esitetään seuraavassa kuvassa.

mutta Lineaarinen Diskriminanttianalyysi epäonnistuu, kun jakaumien keskiarvo jaetaan, koska LDA: n on mahdotonta löytää uutta akselia, joka tekee molemmat luokat lineaarisesti erotettavissa oleviksi. Tällaisissa tapauksissa käytämme epälineaarista diskriminanttianalyysiä.
Extensions to LDA:
- Quadratic Discriminant Analysis (QDA): Jokainen luokka käyttää omaa estimaattiaan varianssille (tai kovarianssille, kun tulomuuttujia on useita).
- joustava Discriminant Analysis (FDA): jossa käytetään ei-lineaarisia tuloyhdistelmiä, kuten splines.
- Regularisoitu Diskriminanttianalyysi (RDA): tuo regularisaation varianssin estimaattiin (itse asiassa kovarianssiin), moderoiden eri muuttujien vaikutusta LDA: han.
hakemukset:
- kasvojentunnistus: Tietokonenäön alalla kasvojentunnistus on erittäin suosittu sovellus, jossa jokaista kasvoja edustaa hyvin suuri määrä pikseliarvoja. Lineaarinen discriminant analysis (Lda) käytetään tässä vähentää useita ominaisuuksia helpommin hallittavissa numero ennen luokitteluprosessia. Jokainen luotu uusi ulottuvuus on lineaarinen yhdistelmä pikselin arvoja, jotka muodostavat mallin. Fisherin lineaarisella diskriminantilla saatuja lineaarikombinaatioita kutsutaan Fisherin tahoiksi.
- lääketieteellinen: Tällä alalla Lineaarinen discriminant analysis (Lda) käytetään luokitella potilaan sairaustila lievänä, keskivaikeana tai vaikeana perustuen potilaan eri parametreihin ja lääketieteelliseen hoitoon, jota hän käy läpi. Tämä auttaa lääkäreitä tehostamaan tai hidastamaan hoitoaan.
- Asiakkaan tunnistus: Oletetaan, että haluamme tunnistaa, millaiset asiakkaat todennäköisimmin ostavat tietyn tuotteen ostoskeskuksesta. Tekemällä yksinkertaisen kysymys-ja vastauskyselyn voimme koota yhteen asiakkaiden kaikki ominaisuudet. Tässä Lineaarinen discriminant-analyysi auttaa meitä tunnistamaan ja valitsemaan ominaisuuksia, jotka voivat kuvata sen asiakasryhmän ominaisuuksia, jotka todennäköisimmin ostavat kyseisen tuotteen ostoskeskuksessa.
