VMware High Availability (HA) on apuohjelma, joka poistaa tarpeen valmiustilan laitteistolle ja ohjelmistolle virtualisoidussa ympäristössä. VMware HA: ta käytetään usein parantamaan luotettavuutta, vähentämään seisokkeja virtuaaliympäristöissä ja parantamaan katastrofien palautumista/liiketoiminnan jatkuvuutta.
tämä luku ote vcp4 Tentti Cram: VMware Certified Professional, 2nd Edition Elias Khnaser tutkii VMware HA parhaita käytäntöjä.
VMware High Availability käsittelee ensisijaisesti ESX / ESXi-isäntävikaa ja sitä, mitä tapahtuu virtuaalikoneille (VMS), jotka ovat käynnissä tässä isännässä. HA voi myös seurata ja käynnistää VM: n uudelleen tarkistamalla, ovatko VMware-työkalut vielä käynnissä. Kun ESX/ESXi-isäntä jostain syystä epäonnistuu, myös kaikki käynnissä olevat VMs: t epäonnistuvat. VMware HA varmistaa, että epäonnistuneen palvelimen VMs voidaan käynnistää uudelleen muissa ESX/ESXi-isännissä.
monet sekoittavat VMware HA: n virheensietokykyyn. VMware HA ei ole vikasietoinen siinä mielessä, että jos isäntä epäonnistuu, myös sen VMs epäonnistuu. HA käsittelee vain näiden VMs: ien uudelleenkäynnistämistä muissa ESX/ESXi-isännissä, joilla on tarpeeksi resursseja. Vikasietoisuus taas tarjoaa keskeytymättömän pääsyn resursseihin isäntävian sattuessa.
 Klikkaa kirjan kansikuvaa yllä
Klikkaa kirjan kansikuvaa yllä ladataksesi Elias Khnaserin koko kappaleen
varmuuskopiosta ja korkeasta saatavuudesta.
VMware HA ylläpitää viestintäkanavaa kaikkien muiden samaan klusteriin kuuluvien ESX / ESXi-isäntien kanssa käyttämällä oletuksena sykettä, jonka se lähettää 1 sekunnin välein vSphere 4.0: ssa tai 10 sekunnin välein vSphere 4.1: ssä. Kun ESX-palvelin menettää sykkeensä, muut isännät odottavat 15 sekuntia, että toinen isäntä vastaa uudelleen. 15 sekunnin kuluttua klusteri aloittaa VMS: n uudelleenkäynnistyksen epäonnistuneessa ESX/ESXi-isännässä klusterin jäljellä olevissa ESX/ESXi-isännissä. VMware HA seuraa myös jatkuvasti klusterin jäseniä ESX / ESXi-isäntiä ja varmistaa, että resurssit ovat aina käytettävissä palvelinvian sattuessa.
Virtual Machine Failure Monitoring
Virtual Machine Failure Monitoring on tekniikka, joka on oletusarvoisesti pois käytöstä. Sen tehtävänä on valvoa virtuaalikoneita, joita se tiedustelee 20 sekunnin välein sydämen sykkeellä. Se tekee tämän käyttämällä VMware työkaluja, jotka on asennettu VM. Kun VM menettää sydämen lyöntitiheyden, VMware HA katsoo tämän VM: n epäonnistuneen ja yrittää nollata sen. Ajattele virtuaalikoneiden vikojen seurantaa eräänlaisena VMS: n korkeana Saatavuutena.
Virtuaalikonevian seurannalla voidaan havaita, onko virtuaalikone kytketty manuaalisesti pois päältä, keskeytetty vai siirretty, eikä sitä siten yritetä käynnistää uudelleen.
VMware HA konfiguraatioedellytykset
HA vaatii seuraavat konfiguraatioedellytykset ennen kuin se voi toimia kunnolla:
- vCenter: koska VMware HA on enterprise-luokan ominaisuus, se vaatii vCenterin ennen kuin se voidaan ottaa käyttöön.
- DNS-resoluutio: kaikkien HA-klusterin jäsenten ESX / ESXi-isäntien on kyettävä ratkaisemaan toisensa DNS: n avulla.
- pääsy jaettuun tallennustilaan: HA-klusterin kaikilla isännillä on oltava pääsy ja näkyvyys samaan jaettuun tallennustilaan; muuten niillä ei olisi pääsyä VMs: ään.
- pääsy samaan verkkoon: Kaikilla ESX/ESXi-isännillä on oltava samat verkot, jotka on määritetty kaikille isännille siten, että kun VM käynnistetään uudelleen missä tahansa isännässä, sillä on jälleen pääsy oikeaan verkkoon.
palvelukonsolin redundanssi
suositeltava käytäntö määrää, että Palvelukonsolilla (SC) on redundanssi. VMware HA valittaa ja antaa varoituksen, jos se havaitsee, että Palvelukonsoli on määritetty vSwitch-kytkimellä, jossa on vain yksi vmnic. Kuten kuva 1 osoittaa, voit määrittää palvelukonsolin redundanssin kahdella tavalla:
- luo kaksi palvelukonsolin porttiryhmää, joista jokainen on eri vSwitch.
- Määritä kaksi fyysistä verkkoliitäntäkorttia (Nic) NIC-tiimin muodossa Palvelukonsoli vswitchille.
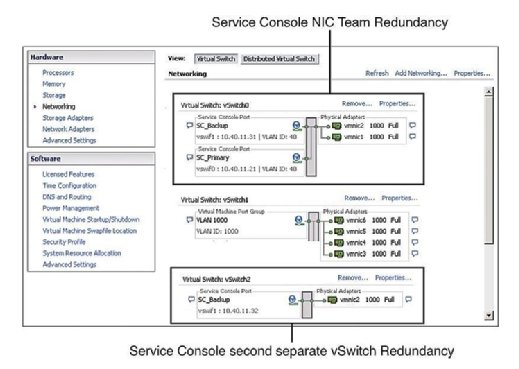
molemmissa tapauksissa on määritettävä koko IP-pino IP-osoitteineen, aliverkoineen ja yhdyskäytävineen. Huoltokonsolin vswitchejä käytetään sydämenlyönteihin ja valtion synkronointiin ja käyttää seuraavia portteja:
- saapuva TCP-portti 8042
- saapuva UDP-portti 8045
- lähtevä TCP-portti 2050
- lähtevä UDP-portti 2250
- saapuva TCP-portti 8042-8045
- lähtevä TCP-portti 8042-8045
- lähtevä TCP-portti 2050-2250
- lähtevä UDP-portti 2050-2250
SC-redundanssin määrittelyn epäonnistuminen johtaa varoitusviestiin, kun otat ha: n käyttöön. Joten, välttää näkemästä tämän virheilmoituksen ja noudattaa parhaita käytäntöjä, määritä SC on tarpeeton.
isännän vikaantumiskapasiteetin suunnittelu
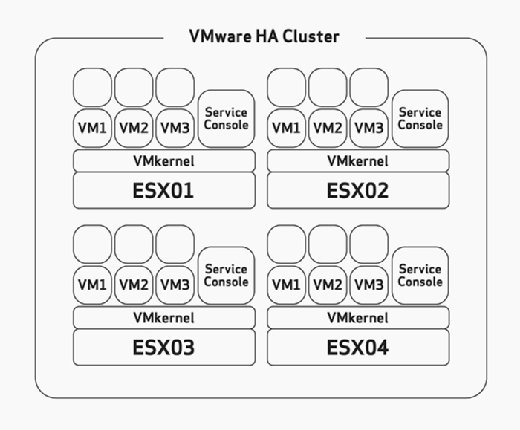
HA: ta määritettäessä on määritettävä manuaalisesti palvelimen suurin vikatoleranssi. Tämä on tehtävä, joka sinun tulisi harkita huolellisesti käyttöönottosi laitteiston mitoitus-ja suunnitteluvaiheessa. Tämä olettaisi, että olet rakentanut ESX/ESXi hosts tarpeeksi resursseja ajaa enemmän VMs kuin suunniteltu mahtuu HA. Esimerkiksi kuvassa 2 huomaa, että HA-klusterissa on neljä ESX-isäntää ja että kaikilla neljällä näistä isännistä on tarpeeksi kapasiteettia vähintään kolmen VMs: n ajamiseen. Koska ne kaikki ovat jo käynnissä kolme VMs, tämä tarkoittaa, että tällä klusterilla on varaa menettää kaksi ESX / ESXi-isäntää, koska loput kaksi ESX / ESXi-isäntää voivat virrata kuuteen epäonnistuneeseen VMs: ään ilman ongelmia, jos vika tapahtuu.
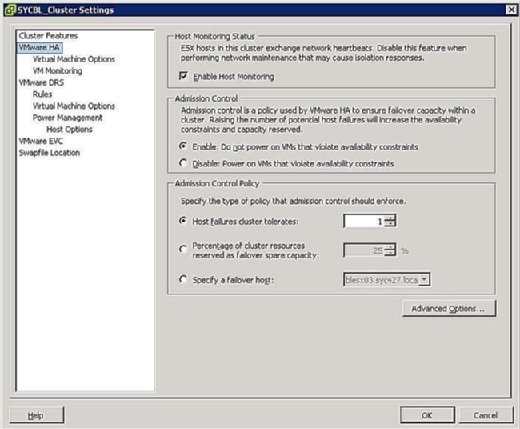
HA-klusterin konfigurointivaiheessa sinulle esitetään samanlainen näyttö kuin kuvassa 3, joka kehottaa sinua määrittelemään kaksi klusterinlaajuista konfiguraatiota seuraavasti:
- Isäntäseurannan tila:
- ota Isäntäseuranta käyttöön: tällä asetuksella voit kontrolloida, pitäisikö HA-klusterin seurata isäntiä sydämen sykkeen varalta. Tämä on klusterin tapa määrittää, onko isäntä vielä aktiivinen. Joissakin tapauksissa, kun suoritat huoltotehtäviä ESX/ESXi hosts-palvelimissa, saattaa olla toivottavaa poistaa tämä asetus käytöstä, jotta vältetään palvelimen eristäminen.
- pääsyvalvonta:
- Ota käyttöön: Älä käytä VMS: ää, joka rikkoo saatavuusrajoituksia: Tämän vaihtoehdon valitseminen osoittaa, että jos VM: n täyttämiseen ei ole käytettävissä resursseja, sitä ei pitäisi kytkeä päälle.
- Poista käytöstä: Virta VMS: ään, joka rikkoo saatavuusrajoituksia: tämän valinnan valitseminen osoittaa, että VM: ään tulee ottaa virta, vaikka resursseja täytyisi sitoa liikaa.
- Pääsyvalvontapolitiikka:
- Isäntävikojen klusteri sietää: tämän asetuksen avulla voit määrittää, kuinka monta isäntävikoja haluat sietää. Sallitut asetukset ovat 1-4.
- sellaisten klusteriresurssien prosenttiosuus, jotka on varattu varaamattomana kapasiteettina: Tämän vaihtoehdon valitseminen osoittaa, että varaat tietyn prosenttiosuuden klusterin kokonaisresursseista varalle vikaantumista varten. Neljän isännän klusterissa 25 prosentin varaus osoittaa, että varaat täyden isännän vikaantumista varten. Jos haluat varata vähemmän, voit valita 10% klusterin resursseista.
- Määritä vara-isäntä: tämän valinnan valitseminen osoittaa, että olet valitsemassa tietyn vara-isännän klusterin vara-isännäksi. Näin voi olla, jos sinulla on vara-isäntä tai tietty isäntä, jolla on huomattavasti enemmän laskenta-ja muistiresursseja käytettävissä.
isännän eristäminen
jakautuneina aivoina tunnettu verkkoilmiö syntyy, kun ESX/ESXi-isäntä on lakannut vastaanottamasta sykettä muusta klusterista. Sydämenlyönnit kysytään joka sekunti vSphere 4.0: ssa tai 10 Sekuntia vSphere 4.1: ssä. Jos vastausta ei saada, klusterin mielestä ESX/ESXi-isäntä on epäonnistunut. Kun näin tapahtuu, ESX/ESXi-isäntä on menettänyt verkkoyhteytensä hallintaliittymässään. Isäntä voi edelleen olla toiminnassa ja VMs ehkä edes vaikuttaa ottaen huomioon ne saattavat käyttää eri verkkoliitäntä, joka ei ole vaikuttanut. Vspheren on kuitenkin ryhdyttävä toimiin, kun näin tapahtuu, koska se uskoo isännän epäonnistuneen. Itse asiassa, isännän eristysvaste luotiin. Host isolation response on HA: n tapa käsitellä verkkoyhteytensä menettänyttä ESX/ESXi-isäntää.
voit kontrolloida, mitä VMs: lle tapahtuu isännän eristyksessä. Jos haluat päästä VM: n Eristysvastausruutuun, napsauta kyseistä klusteria hiiren kakkospainikkeella ja napsauta Muokkaa asetuksia. Voit sitten napsauttaa Virtual Machine Options alla VMware HA banneri vasemmassa ruudussa. Voit control vaihtoehtoja clusterwide asettamalla isäntä eristäminen vastaus vaihtoehto vastaavasti. Tätä sovelletaan kaikkiin VMS vaikuttaa isäntä. Tästä huolimatta voit aina ohittaa klusteriasetukset määrittelemällä eri vastauksen VM-tasolla.
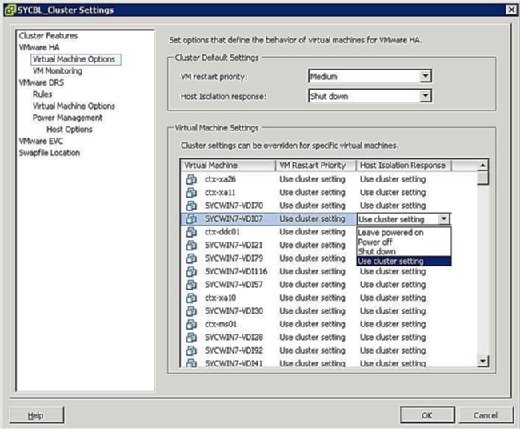
kuten kuvassa 4 on esitetty, Eristysvastevalintasi ovat seuraavat:
- jätä virta päälle: kuten merkinnästä käy ilmi, tämä asetus tarkoittaa, että isäntäkoneen eristyksessä VM pysyy päällä.
- virta pois: tämä asetus määrittelee, että eristyksen sattuessa VM on sammutettu. Tämä on kova sähkökatko.
- Shut down: tämä asetus määrittelee, että eristyksen sattuessa VM suljetaan sulavasti VMware-työkalujen avulla. Jos tehtävää ei suoriteta viiden minuutin kuluessa, virta katkaistaan välittömästi. Jos VMware-työkaluja ei ole asennettu, sen sijaan suoritetaan virrankatkaisu.
- käytä Klusteriasetusta: tämä asetus siirtää tehtävän ryhmälaajuiselle asetukselle, joka on määritelty aiemmin Kuvassa 4 esitetyssä ikkunassa.
eristystilanteessa tämä ei välttämättä tarkoita, että isäntä olisi alhaalla. Koska VMs voidaan konfiguroida erilaisilla fyysisillä Nic-laitteilla ja liittää eri verkkoihin, ne saattavat toimia edelleen asianmukaisesti; sinun on siksi otettava tämä huomioon, kun asetat eristämisen prioriteetin. Kun isäntä on eristetty, tämä tarkoittaa yksinkertaisesti sitä, että sen Palvelukonsoli ei pysty kommunikoimaan klusterin muiden ESX/ESXi-isäntien kanssa.
Virtual machine recovery priority
Jos HA-klusterisi ei voi sijoittaa kaikkia VMs: ää vikatilanteessa, sinulla on kyky priorisoida VMs. Ensisijaiset tavoitteet määräävät, mitkä VMs-järjestelmät käynnistetään uudelleen ensin ja mitkä VMs-järjestelmät eivät ole niin tärkeitä hätätilanteessa. Nämä asetukset on määritetty samalle näytölle kuin edellisessä osassa kuvattu Eristysvaste. Voit määrittää clusterwide-asetukset, joita sovelletaan kaikkiin VMS-järjestelmiin kyseisellä palvelimella, tai voit ohittaa klusteriasetukset määrittämällä ohituksen VM-tasolla.
voit asettaa VM: n uudelleenkäynnistysprioriteetin johonkin seuraavista:
- Korkea: VMS, joilla on korkea prioriteetti, käynnistetään ensin uudelleen.
- Medium: tämä on oletusasetus.
- Low: VMS, jolla on alhainen prioriteetti, käynnistetään uudelleen viimeisenä.
- käytä Klusteriasetusta: VMs käynnistetään uudelleen alla olevassa kuvassa näkyvässä ikkunassa määritellyllä klusteritasolla määritellyn asetuksen perusteella.
- pois käytöstä: VM ei kytkeydy päälle.
prioriteetti tulisi asettaa VMs: n merkityksen perusteella. Toisin sanoen haluat ehkä käynnistää toimialueen ohjaimet uudelleen eikä käynnistää tulostuspalvelimia uudelleen. Korkeamman prioriteetin virtuaalikoneet käynnistetään ensin uudelleen. VMs-laitteet, jotka kestävät virran sammumisen hätätilanteessa, olisi suunniteltava siten, että ne pysyvät virrattomina resurssien säästämiseksi.
MSCS clustering
klusterin päätarkoitus on varmistaa, että kriittiset järjestelmät pysyvät verkossa hinnalla millä hyvänsä ja koko ajan. Virtuaalikoneita voidaan ryhmitellä fyysisten koneiden tapaan myös ESX: llä käyttäen kolmea eri skenaariota:
- Cluster-in-a-box: tässä skenaariossa kaikki klusteriin kuuluvat VMs: t sijaitsevat samassa ESX/ESXi-isännässä. Kuten ehkä arvata, tämä luo välittömästi yhden pisteen vika: ESX / ESXi isäntä. Mitä tulee jaettuun tallennustilaan, voit käyttää virtuaalilevyjä jaettuna tallennustilana tässä skenaariossa, tai voit käyttää raw Device Mapping (RDM) virtuaalisessa yhteensopivuustilassa.
- Cluster-Cross-boxes: tässä skenaariossa klusterin solmut (VMS, jotka ovat klusterin jäseniä) sijaitsevat useilla ESX / ESXi-isännillä, jolloin jokainen klusterin muodostavista solmuista voi käyttää samaa tallennustilaa siten, että jos yksi VM epäonnistuu, toinen voi jatkaa toimintaansa ja käyttää samoja tietoja. Tämä skenaario luo ihanteellisen klusteriympäristön poistamalla yhden vikapisteen. Yhteinen varastointi on tässä edellytys, ja sen on sijaittava Kuitukanavalla SAN. Sinun on myös käytettävä RDM: ää fyysisessä tai virtuaalisessa yhteensopivuustilassa, koska virtuaalilevyt eivät ole tuettuja asetuksia jaetulle tallennustilalle. Jolloin jokainen solmuista, jotka muodostavat klusterin, voi käyttää samaa tallennustilaa niin, että jos yksi VM epäonnistuu, toinen voi jatkaa toimintaansa ja käyttää samaa dataa.
- fyysisestä virtuaaliseen klusteriin: Tässä skenaariossa klusterin yksi jäsen on virtuaalikone, kun taas toinen jäsen on fyysinen kone. Jaettu tallennustila on edellytys tässä skenaariossa, ja se on määritettävä RDM: ksi fyysisessä yhteensopivuustilassa.
kun suunnittelet ryhmitysratkaisua, sinun on käsiteltävä jaettua tallennustilaa, joka mahdollistaisi useiden isäntien tai VMs: n pääsyn samoihin tietoihin. vSphere tarjoaa useita menetelmiä, joilla voit tarjota jaettua tallennustilaa seuraavasti:
- Virtuaalilevyt: Voit käyttää virtuaalilevyä jaettuna tallennusalueena vain, jos teet ryhmittelyä laatikossa-toisin sanoen vain, jos molemmat VMs: t sijaitsevat samassa ESX/ESXi-isännässä.
- RDM fyysisessä yhteensopivuustilassa: tässä tilassa voit liittää fyysisen LUN: n suoraan VM: ään tai fyysiseen koneeseen. Tämä tila estää sinua käyttämästä toimintoja, kuten tilannekuvia, ja sitä käytetään ihanteellisesti, kun yksi klusterin jäsenistä on fyysinen kone, kun taas toinen on VM.
- RDM virtuaalisessa yhteensopivuustilassa: tässä tilassa voit liittää fyysisen LUN: n suoraan VM: ään tai fyysiseen koneeseen. Tämä tila antaa sinulle kaikki vmfs: ssä toimivien virtuaalilevyjen edut, mukaan lukien tilannekuvat ja kehittynyt tiedostojen lukitus. Levyä käytetään hypervisorin kautta, ja se on ihanteellinen konfiguroitaessa klusteri-Cross-boxes-skenaariota, jossa sinun on annettava molemmille VMS-järjestelmille pääsy jaettuun tallennustilaan.
tätä kirjoitettaessa ainoa VMwaren tukema klusterointipalvelu on Microsoft Clustering Services (MSCS). Voit tutustua VMware white paper ” Setup for Failover Clustering and Microsoft Cluster Service.”
VMwaren Vikatoleranssi
VMwaren Vikatoleranssi (FT) on toinen VMwaren kehittämä VM-ryhmittelyn muoto järjestelmille, jotka vaativat äärimmäistä käytettävyyttä. Yksi pakottavia ominaisuuksia FT on sen asennuksen helppous. FT on yksinkertaisesti valintaruutu, joka voidaan ottaa käyttöön. Verrattuna perinteiseen ryhmittelyyn, joka vaatii erityisiä kokoonpanoja ja joissakin tapauksissa kaapelointi, FT on yksinkertainen mutta tehokas.
miten se vaikuttaa?
suojattaessa VMs: ää FT: llä syntyy suojatun VM: n lockstepissä toissijainen VM, ensimmäinen VM. FT toimii kirjoittamalla samaan aikaan ensimmäiseen VM: ään ja toiseen VM: ään. Jokainen tehtävä kirjoitetaan kahteen kertaan. Jos napsautat Käynnistä-valikkoa ensimmäisessä VM: ssä, myös toisen VM: n käynnistysvalikkoa napsautetaan. Ft: n voima on sen kyky pitää molemmat VMs synkronoituna.
Jos suojattu VM jostain syystä menee nurin, toissijainen VM ottaa heti paikkansa anastaen identiteettinsä ja IP-osoitteensa jatkaen käyttäjien palvelemista keskeytyksettä. Vastikään mainostettu suojattu VM luo toissijaisen itselleen toiseen isäntään ja sykli käynnistyy uudelleen.
selventääkseni, katsotaan esimerkki. Jos haluat suojata Exchange server, voit ottaa ft. Jos suojattua VM: ää kuljettava ESX/ESXi-isäntä jostain syystä epäonnistuu, toissijainen VM käynnistyy ja ottaa tehtävänsä vastaan keskeytyksettä käytössä.
alla olevassa taulukossa esitellään erilaisia korkean käytettävyyden ja ryhmittelytekniikoita, joihin voit käyttää vsphereä, ja korostetaan kunkin rajoituksia.

Vikatoleranssivaatimukset
Vikatoleranssi ei poikkea muista yrityksen ominaisuuksista siinä, että se edellyttää tiettyjen edellytysten täyttymistä ennen kuin teknologia voi toimia kunnolla ja tehokkaasti. Nämä vaatimukset on esitetty seuraavassa luettelossa ja jaoteltu eri luokkiin, jotka edellyttävät erityisiä vähimmäisvaatimuksia:
- Isäntävaatimukset:
- FT-yhteensopiva suoritin. Katso lisätietoja tästä VMware KB-artikkelista.
- laitteiston virtualisoinnin on oltava käytössä BIOSissa.
- isännän suorittimen kellotaajuuksien tulee olla 400 MHz: n sisällä toisistaan.
- VM-vaatimukset:
- VMs: n on sijaittava tuetussa jaetussa tallennustilassa (FC, iSCSI ja NFS).
- VMs: n on ajettava tuettu käyttöjärjestelmä.
- VMs on säilytettävä joko VMDK: ssa tai virtuaalisessa RDM: ssä.
- VMs: llä ei voi olla ohuesti varusteltua VMDK: ta, vaan sen on käytettävä Eagerzeroedthick-virtuaalilevyä.
- VMs-järjestelmälle ei voi olla määritetty useampaa kuin yhtä vCPU: ta.
- Klusterivaatimukset:
- kaikkien ESX / ESXi-isäntien on oltava saman version ja saman korjaustason mukaisia.
- kaikilla ESX / ESXi-isännillä on oltava pääsy VM-tietovarastoihin ja-verkkoihin.
- VMware HA on oltava käytössä klusterissa.
- jokaisella isännällä on oltava VMotion-ja FT-Kirjausnumero.
- isännän varmenteen tarkistus on myös otettava käyttöön.
on erittäin suositeltavaa, että sen lisäksi, että tarkistat prosessorin yhteensopivuuden FT: n kanssa, tarkistat palvelimesi merkin ja mallin yhteensopivuuden FT: n kanssa VMware Hardware Compatibility List (HCL) – luettelosta.
vaikka FT on suuri ryhmitysratkaisu, on tärkeää huomata, että sillä on myös tiettyjä rajoituksia. Esimerkiksi FT VMs: ää ei voi snapshottata, eikä niitä voi tallentaa vmoioned-muotoon. Itse asiassa nämä VMs-laitteet merkitään automaattisesti DRS-käytöstä poistettuina, eivätkä ne osallistu dynaamiseen resurssikuorman tasapainotukseen.
ft: n ottaminen käyttöön
FT: n ottaminen käyttöön ei ole vaikeaa, mutta siihen liittyy muutaman eri asetuksen määrittäminen. Seuraavat asetukset on määritettävä oikein, jotta FT toimii:
- Ota käyttöön Isäntävarmenteen tarkistus: Jos haluat ottaa tämän asetuksen käyttöön, kirjaudu vCenter-palvelimeesi ja napsauta Tiedosto-valikosta Hallinta ja napsauta vCenter Server Settings. Valitse vasemmasta ruudusta SSL-Asetukset ja valitse vCenter Requires Verified Host SSL-varmenteet-ruutu.
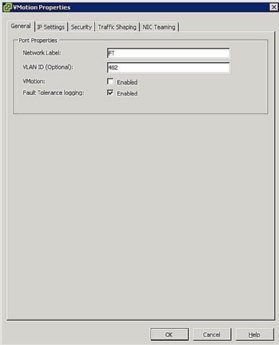
kuva 5. FT port group settings - Configure Host Networking: Ft: n verkkokokoonpano on helppo ja noudattaa samoja vaiheita ja menettelyjä kuin vMotion, paitsi sen sijaan, että tarkistaisit VMotion-ruudun, tarkista Viansietokirjausruutu kuten kuvassa 5.
- ft: n kytkeminen päälle ja pois päältä: kun olet täyttänyt edelliset vaatimukset, voit nyt kytkeä FT: n päälle ja pois päältä VMs: ää varten. Tämä prosessi on myös yksinkertainen: Etsi suojattava VM, napsauta sitä hiiren kakkospainikkeella ja valitse Vikatoleranssi>ota Vikatoleranssi käyttöön.
vaikka FT on ensimmäisen sukupolven klusterointitekniikka, se toimii vaikuttavan hyvin ja yksinkertaistaa liian monimutkaisia perinteisiä klustereiden rakennus -, konfigurointi-ja ylläpitomenetelmiä. FT on vaikuttava teknologia käytettävyyden kannalta ja saumattoman vikaantumisen kannalta.