kategorisia muuttujia ei voi helposti käyttää ennustajina lineaarisessa regressiossa: ne on jaettava dikotomisiin muuttujiin, joita kutsutaan valemuuttujiksi.
ihanteellinen tapa luoda nämä on meidän dummy muuttujia työkalu. Jos et halua käyttää tätä työkalua, tämä opetusohjelma näyttää oikean tavan tehdä se manuaalisesti.
- esimerkki I – Mikä tahansa numeerinen muuttuja
- esimerkki II – numeerinen muuttuja vierekkäisillä kokonaisluvuilla
- esimerkki III – kielinen muuttuja konversiolla
- esimerkki IV – kielinen muuttuja ilman konversiota
esimerkki datatiedosto
Tämä opetusohjelma käyttää henkilökuntaa.sav kaikkialla. Osa tästä tiedostosta on esitetty alla.
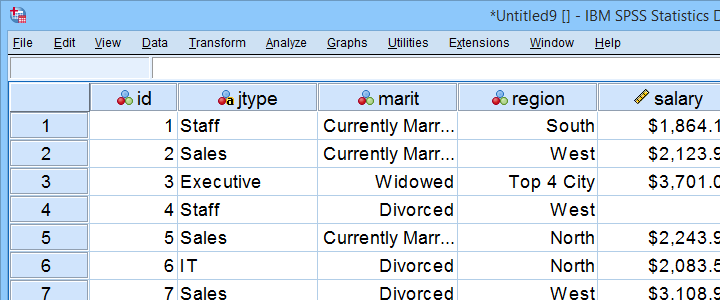
esimerkki I – Mikä tahansa numeerinen muuttuja
luodaan ensin Maritille valemuuttujat, lyhenne siviilisäädystä. Meidän ensimmäinen askel on ajaa perustaajuudet taulukko withfrequencies marit.Alla olevassa taulukossa on esitetty tuloksena oleva taulukko.
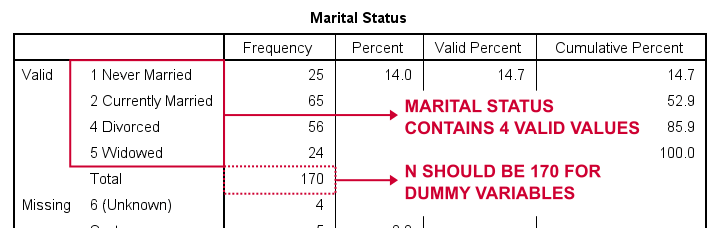
so how to break and siviilisääty into dummy variabilities? Ensinnäkin jätämme aina pois yhden kategorian, viiteluokan. Viiteluokaksi voi valita minkä tahansa kategorian.
joten tähän esimerkkiin valitaan 5 (Leski). Tämä tarkoittaa, että luomme 3 dummy-muuttujaa, jotka edustavat luokkia 1, 2 ja 4 (Huomaa, että 3 ei esiinny tässä muuttujassa).
alla oleva syntaksi näyttää, miten luodaan ja merkitään 3 dummy-muuttujaa. Tehdään se.
lasketaan marit_1 = (marit = 1).
lasketaan marit_2 = (marit = 2).
lasketaan marit_4 = (marit = 4).
*Käytä muuttujan nimikkeitä nuken muuttujiin.
muuttujat
marit_1 ”Siviilisääty = ei koskaan naimisissa”
marit_2 ”Siviilisääty = tällä hetkellä naimisissa”
marit_4 ”Siviilisääty = Eronnut”.
* Quick check first dummy variable
frequencies marit_1.
tulokset
ensinnäkin, huomaamme, että loimme 3 hienosti merkittyä dummy-muuttujaa aktiiviseen aineistoomme.
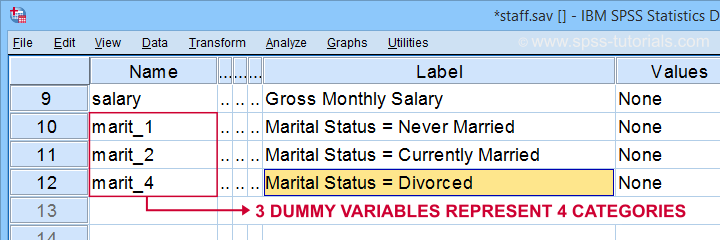
alla oleva taulukko näyttää ensimmäisen dummy-muuttujamme taajuusjakauman.

huomaa, että dummy-muuttujalla on 3 eri arvoa:
- vastaajat, joiden siviilisääty ei ole ”never married” Pisteet 0;
- vastaajat, joiden siviilisääty on ”never married” pisteet 1;
- vastaajat, joiden siviilisääty on ”never married”, ovat järjestelmän puuttuva arvo.
voimme nyt tarkistaa tulokset perusteellisemmin runningcrosstabs marit by marit_1 to marit_4.Näin luo 3 valmiustaulukot, joista ensimmäinen on esitetty alla.
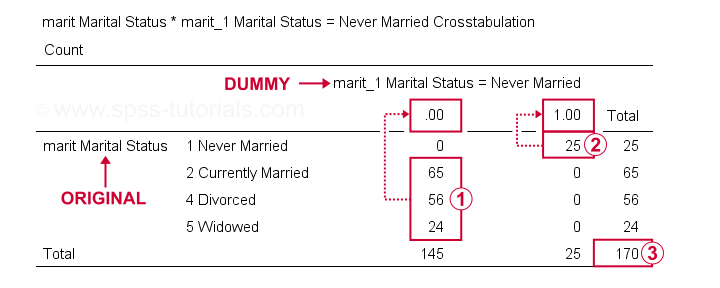
on our dummy variable, vastaajat, joilla on muu siviilisääty kuin” never married”kaikki pisteet 0;
vastaajat, joilla on muu siviilisääty kuin” never married”kaikki pisteet 0; vastaajat, jotka” eivät koskaan avioituneet ” kaikki pisteet 1;
vastaajat, jotka” eivät koskaan avioituneet ” kaikki pisteet 1; otoskoko on n = 170 (tässä taulukossa on mukana vain vastaajia ilman kummankaan muuttujan puuttuvia arvoja).
otoskoko on n = 170 (tässä taulukossa on mukana vain vastaajia ilman kummankaan muuttujan puuttuvia arvoja).
valinnaisesti, lopullinen-erittäin perusteellinen – tarkistus on verrata alkuperäisen muuttujan ANOVA-tuloksia regressiotuloksiin käyttäen nukemuuttujiamme. Syntaksi alla tekee juuri niin, käyttäen kuukausipalkka kuin riippuvainen muuttuja.
regressio
/ riippuva palkka
/ menetelmä merkitään marit_1 – marit_4.
* minimaalinen ANOVA käyttäen alkuperäistä muuttujaa.
oneway salary by marit.
huomaa, että molemmat analyysit johtavat identtisiin ANOVA-taulukoihin. Keskustelemme ANOVA vs. dummy muuttuja regressio perusteellisemmin tulevaisuudessa opetusohjelma.
esimerkki II – numeerinen muuttuja vierekkäisillä kokonaisluvuilla
luodaan nyt dummy-muuttujat alueelle. Jälleen, aloitamme tarkastamalla minimaalinen taajuus taulukko, jonka luomme runningfrequencies alue.Tämä johtaa alla olevaan taulukkoon.
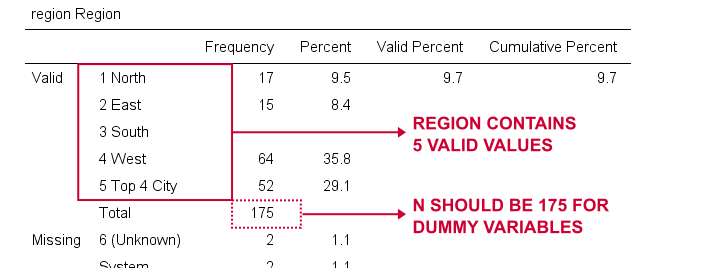
valitsemme viiteluokaksi 1 (”pohjoinen”). Luomme siis valemuuttujia luokille 2 – 5. Koska nämä ovat vierekkäisiä kokonaislukuja, voimme nopeuttaa asioita käyttämällä DO toista kuten alla.
do repeat #vals = 2-5 / #vars = region_2-region_5.
recode region (#vals = 1) (lo thru hi = 0) into #vars.
loppu toistopainatus.
*Käytä muuttujan nimikkeitä uusiin muuttujiin.
muuttujat
region_2 ”Region = East”
region_3 ”Region = South”
region_4 ”Region = West”
region_5 ”Region = Top 4 City”.
* Pikatarkistus.
ristiin rastiin alueittain_2-alue_5.
tuloksena olevien taulukoiden huolellinen tarkastelu vahvistaa, että kaikki tulokset ovat oikeita.
esimerkki III – kielinen muuttuja muunnoksella
valitettavasti ensimmäiset 2-menetelmämme eivät toimi merkkijonomuuttujille, kuten jtype-lyhenne sanoista ”job type”). Helpoin ratkaisu on muuntaa se numeerinen muuttuja kuten SPSS muuntaa merkkijono numeerinen muuttuja. Syntaksi alla käyttää AUTORECODE saada työ.
autorecode jtype
/ into njtype.
* tarkista tulos.
taajuudet njtype.
*Aseta puuttuvat arvot.
puuttuvat arvot njtype (1,2).
*tarkista tulos.
taajuudet njtype.
tulos

koska njtype-lyhenne sanoista ”numeerinen työtyyppi”- on numeerinen muuttuja, voimme nyt käyttää menetelmää I tai menetelmää II sen jakamiseksi dummy-muuttujiksi.
esimerkki IV – merkkijonomuuttuja ilman muuntamista
merkkijonomuuttujien muuntaminen numeerisiksi on helppo luoda niille dummy-muuttujia. Ilman tätä muunnosta prosessi on hankala, koska SPSS ei käsittele merkkijonomuuttujien puuttuvia arvoja oikein. Kuitenkin syntaksi alla saa työn tehtyä oikein.
taajuudet jtype.
* Chance ”(Unknown) ”into ” NA”.
recode jtype (”(Unknown) ” = ”NA”).
*Aseta käyttäjän puuttuvat arvot.
puuttuvat arvot jtype (”, ”NA”).
*Reinspect frekvenssit.
taajuudet jtype.
*luo dummy-muuttujat merkkijonomuuttujalle.
if(not missing (jtype)) jtype_1 = (jtype = ”IT”).
if(not missing (jtype)) jtype_2 = (jtype = ”Management”).
if(not missing (jtype)) jtype_3 = (jtype = ”Sales”).
if(not missing (jtype)) jtype_4 = (jtype = ”Staff”).
*Käytä muuttujan nimikkeitä nuken muuttujiin.
muuttujat
jtype_1 ”Job type = IT”
jtype_2 ”Job type = Management”
jtype_3 ”Job type = Sales”
jtype_4 ”Job type = Staff”.
* Tarkista tulokset.
crosstabs jtype by jtype_1 to jtype_4.
Loppuhuomautukset
valemuuttujien luominen numeerisille muuttujille onnistuu nopeasti ja helposti. Kunnollisten vaihtelevien merkintöjen asettaminen vaatii kuitenkin aina hieman työtä. Merkkijonomuuttujat vaativat jonkin verran lisäaskelia, mutta ovat myös melko toteutettavissa.
helpoin vaihtoehto on kuitenkin SPSS Create Dummy Variables-työkalumme, sillä se hoitaa kaiken täydellisesti.