Hi and welcome to an Illustrated Guide to Long Short-Term Memory (lstm) ja aidatuilla toistuvilla yksiköillä (Gru). Olen Michael ja olen koneoppimisen insinööri tekoälyn ääniassistenttiavaruudessa.
tässä viestissä aloitetaan intuitiosta lstm: n ja GRU: n takana. sitten selitän sisäiset mekanismit, joiden avulla lstm: n ja GRU: n suorituskyky on niin hyvä. Jos haluat ymmärtää, mitä konepellin alla tapahtuu näille kahdelle verkolle, niin tämä viesti on sinua varten.
voit halutessasi katsoa tämän postauksen Videoversion myös YouTubesta.
toistuvat hermoverkot kärsivät lyhytkestoisesta muistista. Jos sekvenssi on tarpeeksi pitkä, heidän on vaikea kuljettaa tietoa aikaisemmista vaiheista myöhempiin. Joten jos yrität käsitellä tekstin kohdan tehdä ennusteita, RNN: n voi jättää pois tärkeitä tietoja alusta.
selän etenemisen aikana toistuvat hermoverkot kärsivät katoavan gradientin ongelmasta. Gradientit ovat arvoja, joita käytetään neuroverkkojen painojen päivittämiseen. Katoava gradienttiongelma on, kun gradientti kutistuu, kun se etenee ajassa taaksepäin. Jos gradienttiarvosta tulee äärimmäisen pieni, se ei edistä liikaa oppimista.

joten toistuvissa neuroverkoissa pienen gradienttipäivityksen saavat kerrokset pysäyttävät oppimisen. Ne ovat yleensä varhaisempia kerroksia. Joten koska nämä kerrokset eivät opi, RNN: t voivat unohtaa, mitä se näki pidemmissä sekvensseissä, jolloin niillä on lyhytkestoinen muisti. Jos haluat tietää enemmän toistuvien neuroverkkojen mekaniikasta ylipäätään, voit lukea aiemman postaukseni täältä.
lstm: n ja GRU: n ratkaisuna
lstm: n ja GRU: n ratkaisuna luotiin lyhytkestoisen muistin ratkaisuksi. Niillä on sisäisiä porteiksi kutsuttuja mekanismeja, joilla voidaan säädellä tiedonkulkua.

nämä portit voivat oppia, mitkä tiedot jonossa on tärkeää säilyttää tai heittää pois. Tekemällä näin se voi välittää asiaankuuluvaa tietoa pitkää sekvenssiketjua pitkin ennustusten tekemiseksi. Lähes kaikki uusimpiin neuroverkkoihin perustuvat huipputulokset saavutetaan näillä kahdella verkolla. LSTM: t ja GRU: t löytyvät puheentunnistuksessa, puhesynteesissä ja tekstin generoinnissa. Voit jopa käyttää niitä luoda kuvatekstejä videoita.
Ok, joten tämän postauksen loppuun mennessä sinulla pitäisi olla vankka käsitys siitä, miksi LSTM: n ja GRU: n ovat hyviä käsittelemään pitkiä sekvenssejä. Aion lähestyä tätä intuitiivisin selityksin ja kuvin ja välttää mahdollisimman paljon matematiikkaa.
intuitio
Ok, aloitetaan ajatuskokeella. Oletetaan, että etsit arvosteluja verkossa, Jos haluat ostaa Life cereal (älä kysy minulta miksi). Voit ensin lukea arvostelun sitten määrittää, jos joku mielestä se oli hyvä tai jos se oli huono.

kun arvostelun lukee, aivot muistavat alitajuisesti vain tärkeät avainsanat. Opit sanoja kuten ”hämmästyttävä”ja” täysin tasapainoinen aamiainen”. Et välitä paljon sanoja kuten ”tämä”, ”antoi”, ”kaikki”, ”pitäisi”, jne. Jos ystävä kysyy sinulta seuraavana päivänä, mitä arvostelussa sanottiin, et luultavasti muistaisi sitä sanasta sanaan. Saatat muistaa pääkohdat, vaikka kuten ”varmasti ostaa uudelleen”. Jos muistutat minua, muut sanat katoavat muistista.

ja niin lstm tai GRU tekee. Se voi oppia pitämään vain relevanttia tietoa ennusteiden tekemiseksi ja unohtaa ei-relevantit tiedot. Tässä tapauksessa muistamasi sanat saivat sinut arvioimaan, että se oli hyvä.
Review of Recurrent Neural Networks
to understand how lstm ’s or GRU’ s perform this, let ’ s review the recurrent neural network. RNN toimii näin; ensimmäiset sanat muuttuvat koneellisesti luettaviksi vektoreiksi. Sitten RNN käsittelee vektorien sekvenssin yksitellen.

käsiteltäessä se siirtää edellisen piilotilan sekvenssin seuraavaan vaiheeseen. Piilotila toimii neuroverkkojen muistina. Se sisältää tietoa aiemmista tiedoista, joita verkosto on nähnyt aiemmin.

katsotaanpa RNN: n solua, miten laskisit piilotilan. Ensin Tulo ja edellinen piilotila yhdistetään muodostaen vektorin. Tällä vektorilla on nyt tietoa nykyisestä ja aiemmista panoksista. Vektori kulkee tanhin aktivaation läpi, ja lähtö on uusi piilotila eli verkon muisti.

tanh-aktivaatio
tanh-aktivaatiota käytetään apuna verkon läpi virtaavien arvojen säätelyssä. Tanh-funktio litistää arvot aina välillä -1 ja 1.

Tanh be between -1 and 1
kun vektorit virtaavat neuroverkon läpi, se käy läpi monia muunnoksia erilaisten matematiikkaoperaatioiden takia. Joten kuvittele arvo, joka edelleen kerrotaan sanotaan 3. Voit nähdä, miten jotkin arvot voivat räjähtää ja muuttua tähtitieteellisiksi, mikä saa toiset arvot näyttämään merkityksettömiltä.

tanh-funktio varmistaa, että arvot pysyvät välillä -1 ja 1, mikä säätelee neuroverkon ulostuloa. Voit nähdä, miten samat arvot ylhäältä jäävät tanh-funktion sallimien rajojen väliin.

niin se on RNN. Sillä on hyvin vähän sisäisiä operaatioita, mutta se toimii melko hyvin oikeissa olosuhteissa (kuten lyhyissä jaksoissa). RNN käyttää paljon vähemmän laskennallisia resursseja kuin sen kehittyneet variantit, LSTM: t ja GRU: t.
LSTM
Lstm: llä on samanlainen kontrollivirta kuin toistuvalla neuroverkolla. Se käsittelee tietoa, joka välittää tietoa eteenpäin, kun se etenee. Erot ovat lstm: n solujen sisäiset toiminnot.

näiden operaatioiden avulla lstm voi säilyttää tai unohtaa tietoja. Nyt näiden operaatioiden katsominen voi mennä vähän ylivoimaiseksi, joten käymme tämän läpi vaihe vaiheelta.
ydinkäsite
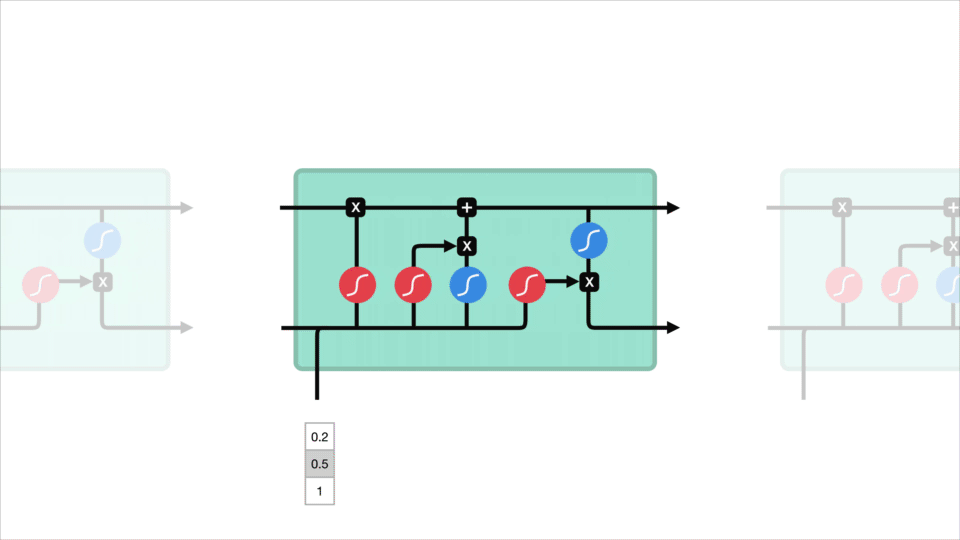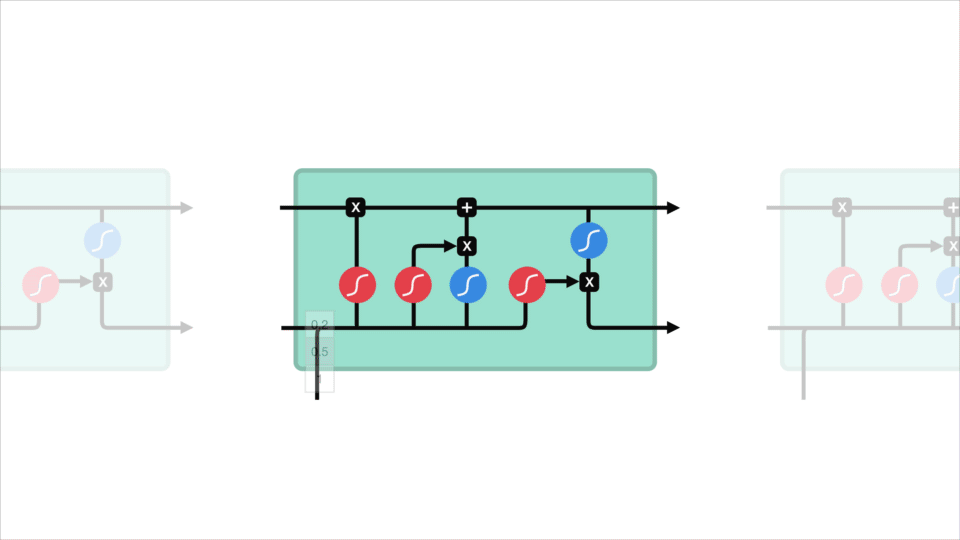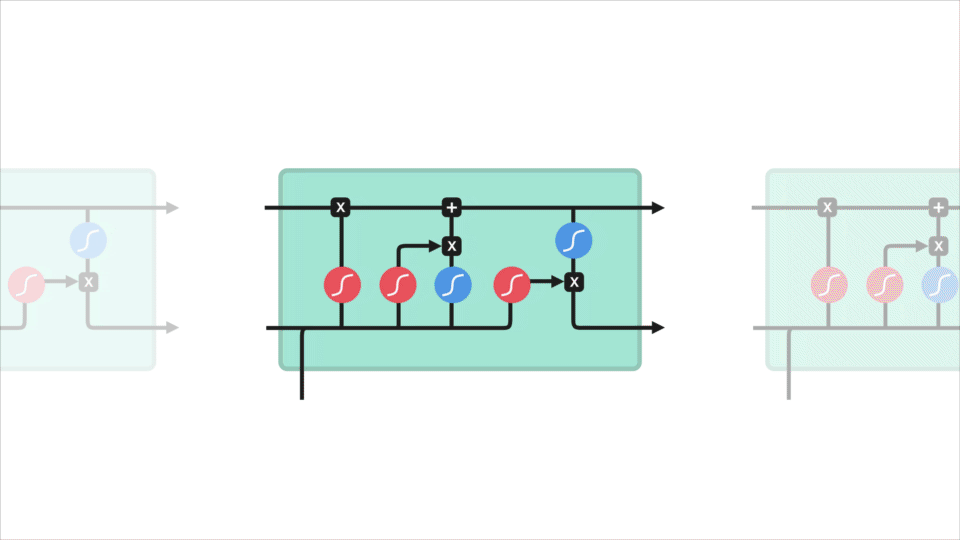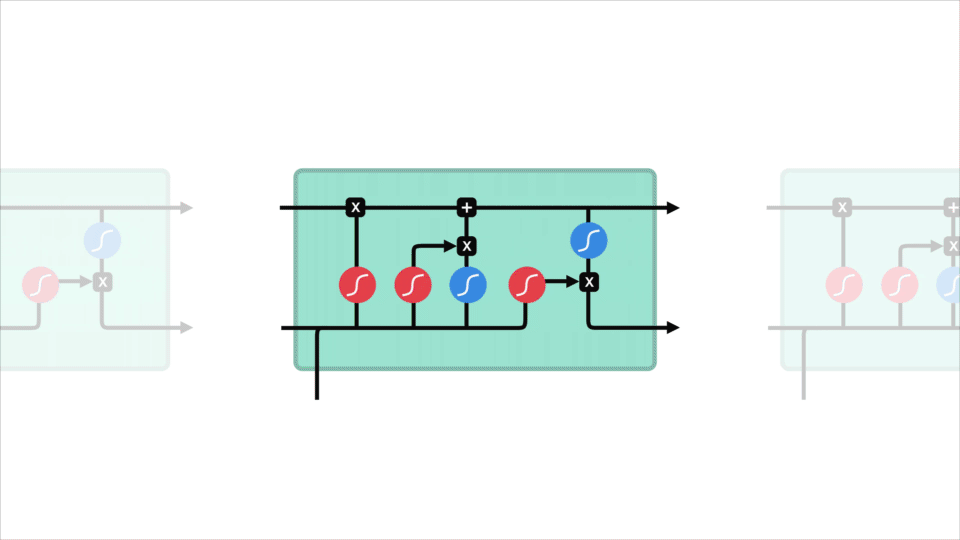
lstm: n ydinkäsite on solutila, ja sen eri portit. Soluvaltio toimii kuljetusväylänä, joka siirtää suhteellista tietoa sekvenssiketjuun asti. Sitä voi pitää verkon ”muistona”. Solutila voi teoriassa kuljettaa oleellista tietoa koko sekvenssin käsittelyn ajan. Joten jopa aikaisempien aikavaiheiden tiedot voivat tehdä tiensä myöhempiin aikavaiheisiin, mikä vähentää lähimuistin vaikutuksia. Solutilan jatkuessa matkaansa informaatio siirtyy tai poistuu solutilaan porttien kautta. Portit ovat erilaisia neuroverkkoja, jotka päättävät, mikä tieto solutilassa on sallittua. Porteilla voi opetella, mitä tietoja on tärkeää pitää tai unohtaa koulutuksen aikana.
Sigmoid
Gates sisältää sigmoid-aktivaatioita. Sigmoid-aktivaatio on samankaltainen kuin tanh-aktivaatio. Sen sijaan, että se litistäisi arvoja välillä -1 ja 1, se litistää arvoja välillä 0 ja 1. Tämä on hyödyllistä päivittää tai unohtaa tietoja, koska mikä tahansa numero saada kerrottuna 0 on 0, aiheuttaa arvojen katoaa tai on ”unohdettu.”Mikä tahansa luku kerrottuna 1: llä on sama arvo, joten arvon oleskelu on sama tai pidetään.”Verkko voi oppia, mitkä tiedot eivät ole tärkeitä, joten ne voidaan unohtaa tai mitkä tiedot on tärkeää säilyttää.

sigmoid squishes values to be between 0 and 1
Let ’ s kaivaa hieman syvemmälle mitä eri portit tekevät, shall we? Meillä on kolme porttia, jotka säätelevät tiedonkulkua lstm: n solussa. Forget gate, input gate ja output gate.
Forget gate
ensin on forget gate. Tämä portti päättää, mitä tietoja pitäisi heittää pois tai säilyttää. Edellisen piilotilan tiedot ja nykyisen tulon tiedot kulkevat sigmoid-funktion kautta. Arvot tulevat ulos välillä 0 ja 1. Lähempänä 0 tarkoittaa unohtaa, ja lähempänä 1 tarkoittaa pitää.

syöttöportti
solun tilan päivittämiseksi meillä on syöttöportti. Ensin siirrämme edellisen piilotilan ja nykyisen tulon sigmoid-funktioon. Joka päättää, mitä arvoja päivitetään muuttamalla arvot ovat välillä 0 ja 1. 0 tarkoittaa ei tärkeää, ja 1 tarkoittaa tärkeää. Voit myös siirtää piilotilan ja nykyisen tulon tanh-funktioon litistämään arvot välillä -1 ja 1 auttaaksesi verkon säätelyssä. Sitten kerrotaan tanh-lähtö sigmoid-ulostulolla. Sigmoid-tuloste päättää, mitkä tiedot on tärkeää pitää tanh-tulosteesta.

solutila
nyt pitäisi olla riittävästi tietoa solun tilan laskemiseksi. Ensin solutila saadaan pointwise kerrottuna forget-vektorilla. Tällä on mahdollisuus pudottaa arvoja solutilassa, jos se saa kerrottuna arvoilla, jotka ovat lähellä arvoa 0. Sitten otamme lähtö sisääntuloportista ja teemme pistekohtaisen yhteenlaskun, joka päivittää solutilan uusiin arvoihin, jotka neuroverkko pitää merkityksellisinä. Se antaa meille uuden solutilan.

lähtöportti
Viimeksi meillä on lähtöportti. Lähtöportti päättää, mikä on seuraava piilotila. Muista, että piilotettu tila sisältää tietoa aiemmista panoksista. Piilotilaa käytetään myös ennusteissa. Ensin ohitamme edellisen piilotilan ja nykyisen tulon sigmoid-funktioksi. Sitten siirrämme uudelleen muunnellun solutilan tanh-funktiolle. Kerromme tanh-lähdön sigmoid-ulostulolla päättääksemme, mitä tietoja piilotetun tilan pitäisi sisältää. Lähtö on piilotila. Uusi solutila ja uusi piilotettu siirretään sitten seuraavaan aikavaiheeseen.

tarkistaakseen forget gate päättää, mikä on oleellista salata aiemmilta vaiheilta. Syöttöportti päättää, mitä tietoja on tärkeää lisätä nykyisestä vaiheesta. Lähtöportti määrittää, mikä on seuraava piilotettu tila.
Koodidemo
niille, jotka ymmärtävät koodin näkemisen kautta paremmin, tässä on esimerkki python pseudokoodista.

1. Ensimmäinen, edellinen piilotettu tila ja nykyinen panos saavat yhtyä. Kutsumme sitä combineiksi.
2. Yhdistä get syötetään unohda kerros. Tämä taso poistaa epäolennaisia tietoja.
4. Ehdokaskerros luodaan Combinen avulla. Ehdokkaalla on Mahdolliset arvot, joita voidaan lisätä solutilaan.
3. Combine myös get ’ s syötetään tulokerrokseen. Tämä taso päättää, mitä tietoja ehdokkaasta lisätään uuteen solutilaan.
5. Forget-kerroksen, ehdokaskerroksen ja tulokerroksen laskemisen jälkeen solun tila lasketaan näiden vektorien ja edellisen solutilan avulla.
6. Tämän jälkeen tuloste lasketaan.
7. Pistekohtaisesti kertomalla lähtö ja uusi solutila antaa meille uuden piilotilan.
That ’ s it! LSTM-verkon ohjausvirtaa ovat muutama tensorioperaatio ja for-silmukka. Voit käyttää piilotiloja ennusteisiin. Yhdistämällä kaikki nämä mekanismit lstm voi valita, mitkä tiedot on tärkeää muistaa tai unohtaa sekvenssin käsittelyn aikana.
GRU
So now we know how an LSTM work, let ’ s shortly look at the GRU. GRU on uusiutuvien neuroverkkojen uudempaa sukupolvea ja muistuttaa melko paljon LSTM: ää. GRU pääsi eroon solutilasta ja käytti piilotilaa tiedon siirtämiseen. Se on myös vain kaksi porttia, reset gate ja update gate.

päivitysportti
päivitysportti toimii samalla tavalla kuin lstm: n forget-ja Input-portti. Se päättää, mitä tietoja heitetään pois ja mitä uutta tietoa lisätään.
Nollausportti
nollausportti on toinen portti, jolla päätetään, kuinka paljon mennyttä tietoa pitää unohtaa.
ja se on GRU. GRU: lla on vähemmän tensorioperaatioita; siksi ne ovat hieman nopeampia kouluttaa sitten LSTM: n. ei ole selvää voittaja kumpi on parempi. Tutkijat ja insinöörit yleensä yrittää molemmat selvittää, kumpi toimii paremmin niiden käyttötapaus.
niin siinä se
tämän yhteenvetona, RNN: t ovat hyviä prosessoimaan sekvenssitietoja ennusteita varten, mutta kärsivät lähimuistista. LSTM: t ja GRU: t luotiin menetelmäksi lieventää lähimuistia gatesiksi kutsuttujen mekanismien avulla. Portit ovat vain neuroverkostoja, jotka säätelevät sekvenssiketjun läpi virtaavaa informaatiovirtaa. LSTM: ää ja GRU: ta käytetään uusimmissa syväoppimisen sovelluksissa, kuten puheentunnistuksessa, puhesynteesissä, luonnollisen kielen ymmärtämisessä jne.
Jos olet kiinnostunut menemään syvemmälle, tässä on linkkejä upeista resursseista, jotka voivat antaa sinulle erilaisen näkökulman LSTM: n ja GRU: n ymmärtämiseen.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/