William W Wold
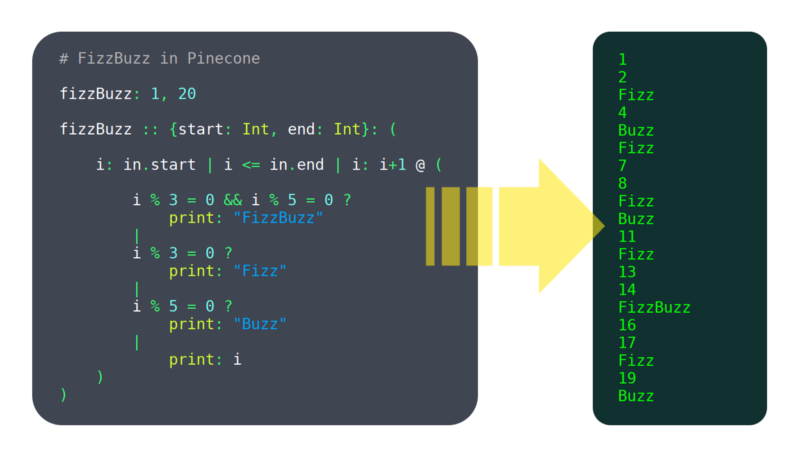
viimeisten 6 kuukauden aikana olen työstänyt ohjelmointikieltä nimeltä Käpy. En kutsuisi sitä vielä kypsäksi, mutta siinä on jo tarpeeksi toimivia ominaisuuksia käyttökelpoisiksi, kuten:
- muuttujat
- funktiot
- käyttäjän määrittelemät rakenteet
Jos se kiinnostaa, tutustu Käpylän aloitussivuun tai sen GitHub-repoon.
en ole asiantuntija. Kun aloitin tämän projektin, minulla ei ollut aavistustakaan siitä, mitä olin tekemässä, enkä vieläkään tiedä. olen ottanut nolla kurssia kielten luomisesta, lukenut siitä vain vähän netistä, enkä noudattanut juurikaan neuvoja, joita olen saanut.
ja silti tein vielä täysin uuden kielen. Ja se toimii. Joten minun täytyy tehdä jotain oikein.
tässä postauksessa sukellan konepellin alle ja näytän, millä pipeline käpy (ja muut ohjelmointikielet) käyttävät lähdekoodin muuttamista taikuudeksi.
aion myös käsitellä joitakin tradeoffs olen ollut tehdä, ja miksi tein päätöksiä tein.
Tämä ei suinkaan ole täydellinen opetusohjelma ohjelmointikielen kirjoittamiseen, mutta se on hyvä lähtökohta, jos kielen kehitys kiinnostaa.
aloitus
”minulla ei ole aavistustakaan, mistä edes aloittaisin” kuuluu paljon, kun kerron muille kehittäjille kirjoittavani kieltä. Siltä varalta, että se on reaktiosi, käyn nyt läpi joitakin alustavia päätöksiä, jotka on tehty ja toimenpiteitä, jotka on otettu, kun aloitat uuden kielen.
kootut vs Tulkatut
on olemassa kaksi päätyyppiä: kootut ja tulkatut kielet:
- kääntäjä selvittää kaiken, mitä ohjelma tekee, muuttaa sen ”konekoodiksi” (formaatti, jota tietokone voi ajaa todella nopeasti) ja tallentaa sen myöhemmin suoritettavaksi.
- tulkki kulkee lähdekoodia rivi riviltä ja miettii, mitä se tekee mennessään.
teknisesti mikä tahansa kieli voidaan koota tai tulkita, mutta jompikumpi on yleensä järkevämpi tietylle kielelle. Yleensä tulkkaus on joustavampaa, kun taas kääntäminen on yleensä tehokkaampaa. Mutta tämä on vain raapaisua pintaa hyvin monimutkainen aihe.
arvostan suorituskykyä suuresti, ja näin, että ohjelmointikielet, jotka ovat sekä suorituskykyisiä että yksinkertaisuuteen painottuvia, puuttuvat, joten lähdin käpylälle käännettyjen kanssa.
Tämä oli tärkeä päätös jo varhain, koska se vaikuttaa moniin kielen suunnittelupäätöksiin (esimerkiksi staattinen kirjoittaminen on suuri etu käännetyille kielille, mutta ei niinkään tulkituille).
huolimatta siitä, että Käpy on suunniteltu kääntämistä ajatellen, siinä on täysin toimiva tulkki, joka oli hetken aikaa ainoa tapa pyörittää sitä. Tähän on useita syitä, joita Selitän myöhemmin.
Kielen valitseminen
tiedän, että se on vähän meta, mutta ohjelmointikieli on itsessään ohjelma, joten se pitää kirjoittaa kielellä. Valitsin C++: n sen suorituskyvyn ja suuren ominaisuuskokonaisuuden vuoksi. Myös, olen todella nauttia työskentely C++.
Jos kirjoitat tulkattua kieltä, on järkevää kirjoittaa se kootulla kielellä (kuten C, C++ tai Swift), koska tulkkisi ja tulkkiasi tulkkaavan tulkin kielestä kadonnut suoritus lisääntyy.
Jos aiot kääntää, hitaampi kieli (kuten Python tai JavaScript) on hyväksyttävämpi. Käännösaika voi olla huono, mutta mielestäni se ei ole läheskään niin iso asia kuin huono ajoaika.
korkean tason suunnittelu
ohjelmointikieli rakentuu yleensä putkistoksi. Toisin sanoen siinä on useita vaiheita. Jokaisessa vaiheessa tiedot on muotoiltu tietyllä, hyvin määritellyllä tavalla. Siinä on myös toimintoja, joilla tietoja voidaan muuttaa kustakin vaiheesta seuraavaan.
ensimmäinen vaihe on merkkijono, joka sisältää koko syötetyn lähdetiedoston. Viimeinen erikoiskoe on sellainen, joka voidaan ajaa. Tämä kaikki selviää, kun käymme Käpyputken läpi vaihe vaiheelta.
Lexing

useimmissa ohjelmointikielissä ensimmäinen vaihe on lexing eli tokenisointi. ”Lex” on lyhenne sanoista lexical analysis, erittäin hieno sana jakaa joukko tekstiä poletteihin. Sana ”tokenizer” on paljon järkevämpi, mutta ”lexer” on niin hauska sanoa, että käytän sitä joka tapauksessa.
Token
token on kielen pieni yksikkö. Token voi olla muuttujan tai funktion nimi (Alias tunniste), operaattori tai numero.
Lexerin tehtävä
lexerin oletetaan ottavan mukaan merkkijonon, joka sisältää kokonaisen tiedoston verran lähdekoodia, ja sylkevän esiin luettelon, joka sisältää jokaisen Tokenin.
putken tulevat vaiheet eivät viittaa takaisin alkuperäiseen lähdekoodiin, joten lekserin on tuotettava kaikki tarvitsemansa tieto. Syynä tähän suhteellisen tiukkaan putkimuotoon on se, että lexer voi tehdä tehtäviä, kuten poistaa kommentteja tai havaita, jos jokin on numero tai tunniste. Haluat pitää tuon logiikan lukittuna lekserin sisällä, jotta sinun ei tarvitse miettiä näitä sääntöjä kirjoittaessasi muuta kieltä, ja jotta voit muuttaa tämän tyyppistä syntaksia yhdessä paikassa.
Flex
sinä päivänä, kun aloitin kielen, kirjoitin ensimmäiseksi yksinkertaisen lekserin. Pian sen jälkeen, aloin oppia työkaluja, jotka muka tehdä lexing yksinkertaisempi, ja vähemmän buginen.
vallitseva tällainen työkalu on flex, ohjelma, joka luo lexereitä. Annat sille tiedoston, jossa on erityinen syntaksi kuvaamaan kielen kielioppia. Siitä se luo C-ohjelman, joka lexes merkkijono ja tuottaa halutun tuotoksen.
päätökseni
päätin pitää kirjoittamani lekserin toistaiseksi. Lopulta en nähnyt merkittäviä etuja käyttämällä Flex, ainakaan tarpeeksi perustella lisäämällä riippuvuutta ja vaikeuttaa rakentaa prosessi.
lekserini on vain muutaman sadan rivin mittainen, ja aiheuttaa harvoin ongelmia. Oman lexerin pyörittäminen antaa myös lisää joustavuutta, kuten mahdollisuuden lisätä kieleen operaattorin muokkaamatta useita tiedostoja.
jäsennys

putken toinen vaihe on jäsennin. Jäsennin muuttaa polettien luettelon solmujen puuksi. Puu, jota käytetään tämäntyyppisten tietojen tallentamiseen, tunnetaan abstraktina Syntaksipuuna eli AST: na. Ainakaan Käpylässä AST: lla ei ole tietoa tyypeistä tai siitä, mitkä tunnisteet ovat mitäkin. Se on yksinkertaisesti jäsennelty poletteja.
Parseritehtävät
parseri lisää rakenteen lekserin tuottamiin tokeneihin. Epäselvyyksien lopettamiseksi jäsentäjän on otettava huomioon sulut ja leikkausjärjestys. Yksinkertaisesti jäsentäminen operaattorit ei ole hirveän vaikeaa, mutta enemmän kielen konstruktioita saada lisätään, jäsentäminen voi tulla hyvin monimutkainen.
biisonit
taas tehtiin päätös kolmannen osapuolen kirjastosta. Vallitseva jäsennyskirjasto on Biisoni. Bisons toimii kuin Flex. Kirjoitat tiedoston muokatussa muodossa, joka tallentaa kielioppitiedot, sitten Bison käyttää sitä luomaan C-ohjelman, joka tekee jäsennyksen. En valinnut biisonia.
miksi Custom on parempi
lekserin kanssa päätös käyttää omaa koodia oli melko ilmeinen. Lekseri on niin vähäpätöinen ohjelma, että Oman kirjoittamatta jättäminen tuntui melkein yhtä hölmöltä kuin Oman ”vasemmanpuoleisen” kirjoittamatta jättäminen.
parserin kanssa asia on toisin. Käpylehteni on tällä hetkellä 750 riviä pitkä, ja olen kirjoittanut niistä kolme, koska kaksi ensimmäistä olivat roskaa.
tein päätökseni alun perin useista syistä, ja vaikka se ei ole sujunut täysin ongelmitta, useimmat niistä pitävät paikkansa. Tärkeimmät ovat seuraavat:
- minimoi kontekstin vaihtaminen työnkulussa: kontekstin vaihtaminen C++: n ja käpysuomun välillä on tarpeeksi paha ilman bisonin kielioppia
- pidä build simple: joka kerta kun kielioppi muuttuu Bison on ajettava ennen buildia. Tämä voidaan automatisoida, mutta se tulee kipu, kun siirrytään rakentaa järjestelmiä.
- tykkään rakentaa siistiä kamaa: en tehnyt käpyä, koska ajattelin sen olevan helppoa, joten miksi delegoisin keskeistä roolia, kun voisin tehdä sen itse? Mukautettu jäsennin ei välttämättä ole vähäpätöinen, mutta se on täysin toteutettavissa.
alussa en ollut täysin varma, olinko menossa elinkelpoiselle polulle, mutta sain itseluottamusta siitä, mitä Walter Bright (C++: n varhaisen version kehittäjä ja D-kielen luoja) sanoi aiheesta:
”hieman kiistanalaisempi, en viitsisi tuhlata aikaa lexerin tai jäsentimen generaattoreihin ja muihin ns.”He ovat ajanhukkaa. Kirjoittaminen lekseri ja jäsennin on pieni prosenttiosuus työstä kirjallisesti kääntäjä. Generaattorin käyttäminen vie suunnilleen yhtä paljon aikaa kuin yhden kirjoittaminen käsin, ja se vie sinut generaattorille (millä on merkitystä siirrettäessä kääntäjä uudelle alustalle). Generaattoreilla on myös valitettava maine, että ne lähettävät surkeita virheilmoituksia.”
Toimintapuu
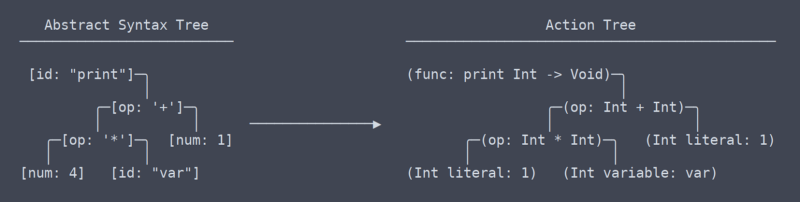
olemme nyt poistuneet yhteisten, yleispätevien termien alueelta, tai ainakaan en tiedä mitä ehdot ovat enää. Käsitykseni mukaan se, mitä kutsun ”toimintapuuksi”, muistuttaa eniten LLVM: n IR (intermediate representation).
toimintapuun ja abstraktin syntaksipuun välillä on hiuksenhieno mutta hyvin merkittävä ero. Kesti jonkin aikaa selvittää, että siellä edes pitäisi olla ero niiden välillä (joka osaltaan tarpeen uudelleenkirjoituksia, jäsennin).
Toimintapuu vs AST
Yksinkertaisesti sanottuna toimintapuu on AST, jolla on konteksti. Tämä asiayhteys on tieto, kuten minkä tyyppinen funktio palauttaa, tai että kaksi paikkaa, joissa muuttujaa käytetään, käyttävät itse asiassa samaa muuttujaa. Koska sen on selvitettävä ja muistettava kaikki tämä asiayhteys, toimintopuun tuottava koodi tarvitsee paljon nimiavaruustaulukoita ja muita asioita.
Toimintopuun juokseminen
kun toimintopuu on meillä, koodin juokseminen on helppoa. Jokaisella toimintosolmulla on toiminto ”suorita”, joka vie jonkin verran syötettä, tekee mitä tahansa toiminnon pitäisi (mukaan lukien mahdollisesti kutsuva alitoiminto) ja palauttaa toiminnon tuotoksen. Tässä on tulkki toiminnassa.
Kokoamisvaihtoehdot
”but wait!”Kuulen sinun sanovan,” eikö Käpy kuulu koota?”Kyllä on. Kääntäminen on kuitenkin vaikeampaa kuin tulkitseminen. On olemassa muutamia mahdollisia lähestymistapoja.
Rakenna oma Kääntäjäni
tämä kuulosti aluksi hyvältä idealta. Rakastan itse tekemistä, ja olen kaivannut tekosyytä tulla hyväksi kokoonpanossa.
valitettavasti kannettavan kääntäjän kirjoittaminen ei ole yhtä helppoa kuin jonkin konekoodin kirjoittaminen jokaiselle kielielementille. Arkkitehtuurien ja käyttöjärjestelmien määrän vuoksi on epäkäytännöllistä, että kukaan henkilö kirjoittaisi cross platform-kääntäjän taustajärjestelmää.
edes Swiftin, Rust and Clangin taustajoukot eivät halua vaivautua yksin, joten sen sijaan he kaikki käyttävät…
LLVM
LLVM on kokoelma kääntäjän työkaluja. Se on periaatteessa kirjasto, joka muuttaa kielesi kootuksi suoritettavaksi binääriksi. Se tuntui täydelliseltä valinnalta, joten hyppäsin heti mukaan. Valitettavasti en tarkistanut, kuinka syvä vesi oli ja hukuin välittömästi.
LLVM, vaikka se ei ole assembly language hard, on jättimäinen kompleksikirjasto kova. Se ei ole mahdotonta käyttää, ja heillä on hyviä opetusohjelmia, mutta tajusin, että minun pitäisi saada hieman harjoitusta ennen kuin olin valmis täysin toteuttamaan Käpy kääntäjä sen kanssa.
Transpilointi
halusin jonkinlaisen kootun Käpylän ja halusin sen nopeasti, joten käännyin yhteen metodiin, jonka tiesin pystyväni toimimaan: transpilointiin.
kirjoitin käpysuomun C++ – transpileriin ja lisäsin kyvyn kääntää lähdelähde automaattisesti GCC: llä. Tämä toimii tällä hetkellä lähes kaikissa Pinecone-ohjelmissa (tosin muutama reunatapaus rikkoo sen). Se ei ole erityisen kannettava tai skaalautuva ratkaisu, mutta se toimii toistaiseksi.
Future
olettaen, että jatkan Käpylän kehittämistä, se saa LLVM: n kokoavan tuen ennemmin tai myöhemmin. Epäilen ei mater kuinka paljon työskentelen sen, transpiler koskaan täysin vakaa ja edut LLVM ovat lukuisia. Kyse on vain siitä, milloin minulla on aikaa tehdä joitakin esimerkkiprojekteja LLVM: ssä ja päästä jyvälle siitä.
siihen asti tulkki sopii hyvin triviaaleihin ohjelmiin ja C++ – transpilointi toimii useimpiin asioihin, jotka tarvitsevat enemmän suorituskykyä.
johtopäätös
toivon, että olen tehnyt ohjelmointikielistä hieman vähemmän salaperäisiä sinulle. Jos haluat tehdä yhden itse, suosittelen sitä. On ton täytäntöönpanon yksityiskohtia selvittää, mutta ääriviivat tässä pitäisi olla tarpeeksi saada sinut menossa.
tässä on korkean tason neuvoni aloittamiseen (muista, en oikein tiedä mitä teen, joten ota se suolajyvällä):
- Jos epäilet, mene tulkiten. Tulkatut kielet ovat yleensä helpompia suunnitella, rakentaa ja oppia. En lannista sinua kirjoittamasta koottua, jos tiedät, että haluat tehdä niin, mutta jos olet aidalla, menisin tulkitsemaan.
- kun on kyse leksereistä ja parsereista, tee mitä haluat. Oman kirjoittamisen puolesta ja vastaan on päteviä argumentteja. Loppujen lopuksi, jos suunnittelet ja toteutat kaiken järkevällä tavalla, sillä ei ole oikeastaan väliä.
- Opi putkesta, johon päädyin. Paljon yritystä ja erehdystä meni suunnittelemaan putkistoa, joka minulla nyt on. Olen yrittänyt eliminoida ASTs, ASTs jotka muuttuvat toimia puita paikallaan, ja muita kauheita ideoita. Tämä putki toimii, joten älä muuta sitä, ellei sinulla ole todella hyvä idea.
- Jos sinulla ei ole aikaa tai motivaatiota toteuttaa monimutkaista yleiskieltä, kokeile toteuttaa esoteerinen kieli kuten Brainfuck. Nämä tulkit voivat olla jopa muutaman sadan rivin mittaisia.
Käpylinnun kehitys kaduttaa minua hyvin vähän. Tein matkan varrella useita huonoja valintoja, mutta olen kirjoittanut uudelleen suurimman osan koodista, johon tällaiset virheet vaikuttavat.
juuri nyt Käpy on sen verran hyvässä kunnossa, että se toimii hyvin ja sitä on helppo parantaa. Käpylän kirjoittaminen on ollut minulle valtavan opettavainen ja nautittava kokemus, ja se on vasta pääsemässä alkuun.