päivitetty viimeksi 17.helmikuuta 2021
ennustaminen koneoppimisen näkökulmasta on yksi piste, joka kätkee ennustuksen epävarmuuden.
Ennustusvälit mahdollistavat ennusteen epävarmuuden kvantifioinnin ja viestimisen. Ne eroavat luottamusväleistä, joilla pyritään sen sijaan kvantifioimaan populaatioparametrin, kuten keskiarvon tai keskihajonnan, epävarmuus. Ennustusvälit kuvaavat yksittäisen tuloksen epävarmuutta.
tässä opetusohjelmassa tutustutaan ennustusväliin ja siihen, miten se lasketaan yksinkertaiselle lineaariselle regressiomallille.
tämän opetusohjelman suoritettuasi tiedät:
- , että ennustusväli määrittää yhden pisteen ennustuksen epävarmuuden.
- että ennustusvälit voidaan arvioida analyyttisesti yksinkertaisille malleille, mutta ovat haastavampia epälineaarisille koneoppimismalleille.
- kuinka lasketaan ennusteväli yksinkertaiselle lineaariselle regressiomallille.
Kick-start your project with my new book Statistics for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
aloitetaan.
- päivitetty kesä / 2019: korjattu merkitsevyystaso keskihajontojen murto-osana.
- päivitetty huhti / 2020: Korjattu kirjoitusvirhe ennustusvälin kuvaajassa.

Ennustusvälit Koneoppimiselle
Kuva: Jim Bendon, jotkut oikeudet pidätetään.
Tutorial Overview
Tämä opetusohjelma on jaettu 5 osaan; ne ovat:
- mitä vikaa Piste-Estimaatissa on?
- mikä on Ennusteväli?
- Miten lasketaan Ennustusväli
- Ennustusväli lineaariselle regressiolle
- toiminut esimerkki
Tarvitsetko apua koneoppimisen tilastoinnissa?
ota ilmainen 7 päivän sähköpostin pikakurssi nyt (näytekoodilla).
klikkaa ilmoittautuaksesi ja saat myös ilmaisen PDF Ebook-version kurssista.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict (X)
|
missä yhat on koulutetun mallin antama arvioitu tulos tai ennuste annetulle syöttötiedolle X.
Tämä on pisteennuste.
määritelmän mukaan se on estimaatti tai likiarvo ja sisältää jonkin verran epävarmuutta.
epävarmuus tulee itse mallin virheistä ja syöttötiedon kohinasta. Malli on approksimaatio panosmuuttujien ja lähtömuuttujien suhteesta.
kun otetaan huomioon mallin valinta-ja viritysprosessi, se on paras saatavilla olevien tietojen perusteella tehty likiarvo, mutta se tekee silti virheitä. Tiedot toimialueen luonnollisesti hämärtää taustalla ja tuntematon suhde Tulo ja Lähtö muuttujat. Tällöin mallin sovittaminen on haastavaa, ja myös ennusteiden tekeminen sopii mallille.
kun otetaan huomioon nämä kaksi pääasiallista virhelähdettä, niiden pisteennustus ennustemallista ei riitä kuvaamaan ennusteen todellista epävarmuutta.
mikä on Ennusteväli?
ennusteväli on ennusteen epävarmuuden kvantifiointi.
se antaa todennäköisyyslaskennan tulosmuuttujan estimaatille ylä-ja alarajan.
yksittäisen tulevaisuushavainnon ennustusväli on aikaväli, joka tietyllä luotettavuusasteella sisältää jakaumasta satunnaisesti valitun tulevan havainnon.
— Page 27, Statistical Intervalls: a Guide for Practitioners and Researchers, 2017.
Ennustusvälejä käytetään yleisimmin tehtäessä ennusteita tai ennusteita regressiomallilla, jossa ennustetaan Suure.
esimerkki ennustevälin esittämisestä on seuraava:
kun ennustetaan ” y ”annettuna ” x”, on 95 prosentin todennäköisyys, että vaihteluväli ” a ” – ” b ” kattaa todellisen tuloksen.
ennusteväli ympäröi mallin tekemän ennusteen ja kattaa toivottavasti todellisen tuloksen vaihteluvälin.
alla oleva kaavio auttaa visuaalisesti hahmottamaan ennusteen, ennustusvälin ja todellisen tuloksen välistä suhdetta.
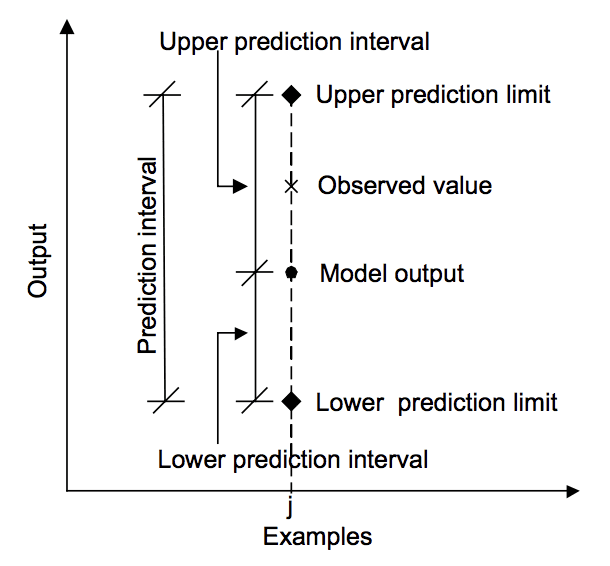
ennusteen, todellisen arvon ja ennustusvälin suhde.
otettu teoksesta ”Machine learning approaches for estimation of prediction interval for the model output”, 2006.
ennusteväli on eri kuin luottamusväli.
luottamusväli kvantifioi estimoidun populaatiomuuttujan, kuten keskiarvon tai keskihajonnan, epävarmuuden. Kun taas ennusteväli kvantifioi populaatiosta arvioidun yksittäisen havainnon epävarmuuden.
ennustemallinnuksessa voidaan käyttää luottamusväliä mallin arvioidun taidon epävarmuuden kvantifiointiin, kun taas ennusteväliä voidaan käyttää yksittäisen ennusteen epävarmuuden kvantifiointiin.
ennusteväli on usein luottamusväliä suurempi, koska siinä on otettava huomioon ennustettavan tuotosmuuttujan luottamusväli ja varianssi.
Ennustusvälit ovat aina laajemmat kuin luottamusvälit , koska ne selittävät E: hen liittyvän epävarmuuden, irreducible-virheen.
— Page 103, An Introduction to Statistical Learning: with Applications in R, 2013.
Miten lasketaan Ennusteväli
ennusteväli lasketaan jonkinlaisena yhdistelmänä mallin arvioidusta varianssista ja lopputulosmuuttujan varianssista.
Ennustusvälit on helppo kuvata, mutta käytännössä vaikea laskea.
yksinkertaisissa tapauksissa, kuten lineaarisessa regressiossa, voimme arvioida ennustusvälin suoraan.
epälineaaristen regressioalgoritmien, kuten keinotekoisten neuroverkkojen, tapauksessa se on paljon haastavampaa ja vaatii erikoistekniikoiden valintaa ja toteuttamista. Yleisiä tekniikoita, kuten bootstrap resampling menetelmä voidaan käyttää, mutta ovat laskennallisesti kalliita laskea.
paperi ”a Comprehensive Review of Neural Network-based Prediction Intervalls and New Advances” tarjoaa kohtuullisen tuoreen tutkimuksen epälineaaristen mallien ennustusväleistä neuroverkkojen yhteydessä. Seuraavassa luettelossa on yhteenveto menetelmistä, joita voidaan käyttää epälineaaristen koneoppimismallien ennustusepävarmuuteen:
- Delta-menetelmä epälineaarisen regression kentältä.
- Bayesilainen menetelmä, bayesilaisesta mallinnuksesta ja tilastoista.
- Keskiarvovarianssin estimointimenetelmä, jossa käytetään estimoituja tilastoja.
- Bootstrap-menetelmä, jossa hyödynnetään datan resampling ja kehitetään mallikokonaisuus.
voimme konkretisoida ennustevälin laskemisen seuraavassa osiossa toimivalla esimerkillä.
lineaarisen Regression Ennustusväli
lineaarinen regressio on malli, joka kuvaa tulojen lineaarista yhdistelmää lähtömuuttujien laskemiseksi.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
emme tiedä kertoimien B0 ja b1 todellisia arvoja. Emme myöskään tiedä todellisia populaatioparametreja, kuten keskiarvoa ja keskihajontaa X: lle tai y: lle. kaikki nämä tekijät on estimoitava, mikä tuo epävarmuutta mallin käyttöön, jotta voidaan tehdä ennusteita.
voimme tehdä joitakin oletuksia, kuten X: n ja y: n jakaumat ja mallin tekemät ennustevirheet, joita kutsutaan residuaaleiksi, ovat Gaussin.
ennusteväli yhatin ympärillä voidaan laskea seuraavasti:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
emme tiedä käytännössä. Voimme laskea puolueettoman estimaatin ennustetusta keskihajonnasta seuraavasti (otettu koneoppimisen lähestymistavoista mallin tuotoksen ennustusvälin arvioimiseksi):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
Työesimerkki
tehdään lineaaristen regressioennustusvälien tapaus konkreettiseksi työesimerkillä.
määritellään ensin yksinkertainen kahden muuttujan datajoukko, jossa lähtömuuttuja (y) riippuu tulomuuttujasta (x), jossa on jonkin verran Gaussin kohinaa.
alla olevassa esimerkissä määritellään aineisto, jota käytämme tässä esimerkissä.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
aineiston kuvaaja luodaan.
voidaan nähdä selkeä lineaarinen suhde muuttujien välillä pisteiden hajaantuessa korostaen kohinaa tai satunnaisvirhettä suhteessa.
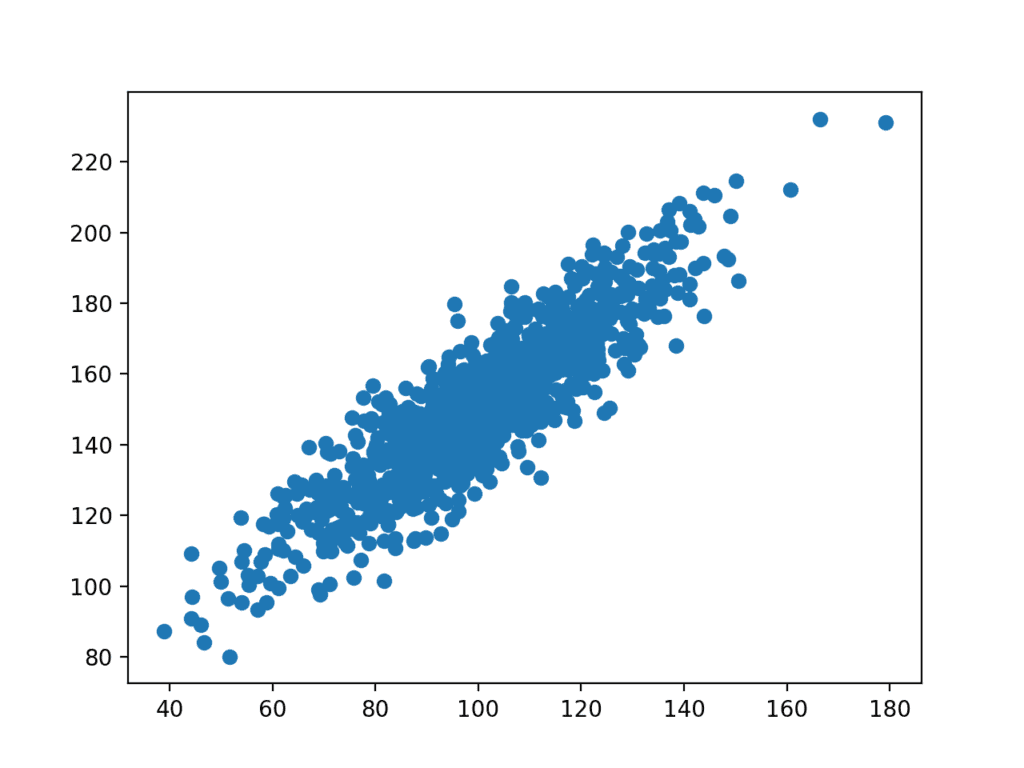
vastaavien muuttujien Hajontakaavio
seuraavaksi voidaan kehittää yksinkertainen lineaarinen regressio, joka syöttömuuttujan x perusteella ennustaa y-muuttujan. Linregressin () SciPy-funktiolla voidaan sovittaa malliin ja palauttaa mallin B0-ja b1-kertoimet.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# yksinkertainen epälineaarinen regressiomalli
alkaen numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(’b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
kertoimia käytetään sitten aineistosta saatujen syötteiden kanssa ennusteen tekemiseksi. Tuloksena saatavat tulot ja ennustetut y-arvot piirretään viivaksi aineiston scatter-kuvaajan päälle.
voimme selvästi nähdä, että malli on oppinut aineiston taustalla olevan suhteen.
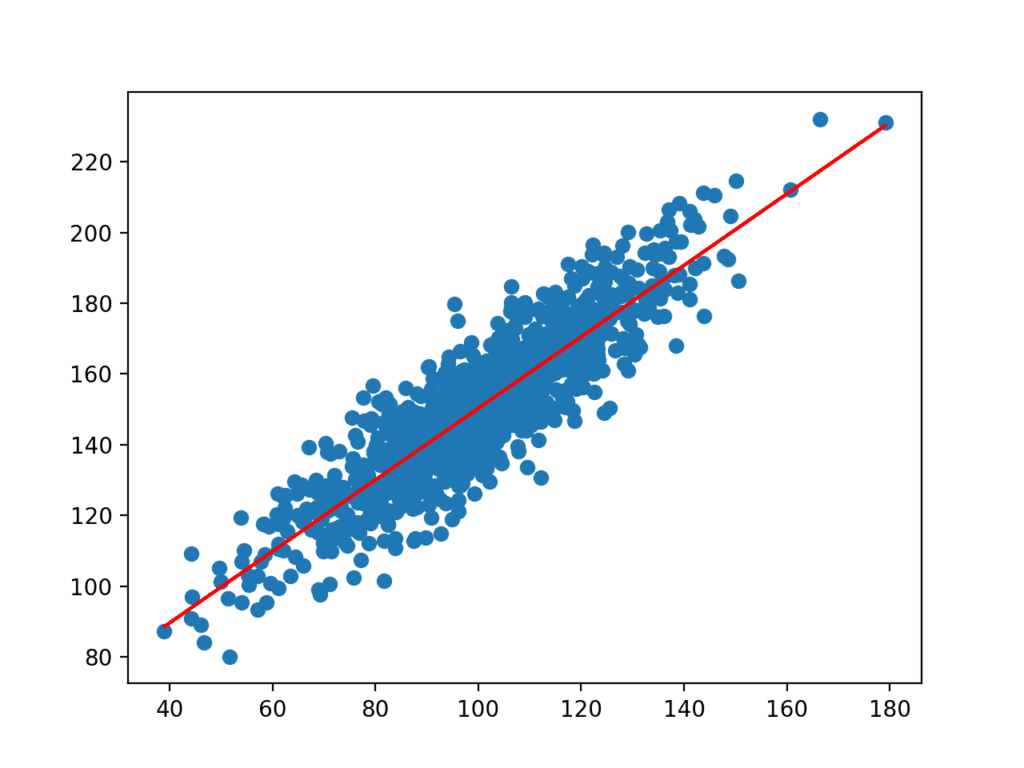
aineiston Hajontakaavio yksinkertaisella lineaarisella Regressiomallilla
olemme nyt valmiita tekemään ennusteen yksinkertaisella lineaarisella regressiomallilla ja lisäämään ennustusvälin.
me sovitellaan mallia kuten ennenkin. Tällä kertaa otamme yhden näytteen aineistosta osoittaaksemme ennustusvälin. Käytämme syötteen tehdä ennusteen, laskea ennusteen aikaväli ennusteen, ja vertaa ennuste ja aikaväli tunnettu odotusarvo.
määritellään ensin tulo -, ennuste-ja odotusarvot.
|
1
2
3
|
x_in = X
y_out = y
yhat_out = yhat |
seuraavaksi voidaan arvioida vakiokäyrä ennusteen suuntaan.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.tilastot import linregress
from matplotlib import pyplot
# Seed random number generator
seed(1)
# preparate the data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit the nonlinear regression model
B1, B0, r_value, p_value, std_err = linregress(x, y)
# Mark predictions
yhat = B0 + B1 * x
# define new input, expected value and prediction
x_in = x
y_out = y
yhat_out = yhat
# estimate StDev of yhat
sum_errs = arraysum ((y – yhat)**2)
stdev = sqrt(1/(len (y)-2) * sum_errs)
# calculate prediction interval
interval = 1, 96 * stdev
print (”Prediction Interval: %.3f ’ % interval)
lower, upper = yhat_out – interval, yhat_out + interval
print(’95%% todennäköisyys, että todellinen arvo on välillä %.3f ja %.3f ’ % (Alempi, Ylempi))
print (”todellinen arvo: %.3f ’ % y_out)
# havaintoaineisto ja ennustaminen intervallilla
pyplot.hajonta (x, y)
pyplot.plot (x, yhat, color= ”punainen”)
pyplot.errorbar (x_in, yhat_out, yerr=interval, color= ”black”, fmt= ”o”)
pyplot.show ()
|
esimerkin Juoksu arvioi yhatin keskihajonnan ja laskee sitten ennustevälin.
kun on laskettu, ennusteväli esitetään käyttäjälle annetun syöttömuuttujan osalta. Koska me keksimme tämän esimerkin, me tiedämme todellisen lopputuloksen,jonka me myös näytämme. Voimme nähdä, että tässä tapauksessa 95%: n ennusteväli ei kata todellista odotusarvoa.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
luodaan myös kuvaaja, joka esittää raakaa aineistoa sirontajuonena, aineistoa koskevia ennusteita punaisena viivana ja ennustusväliä mustana pisteenä ja viivana.
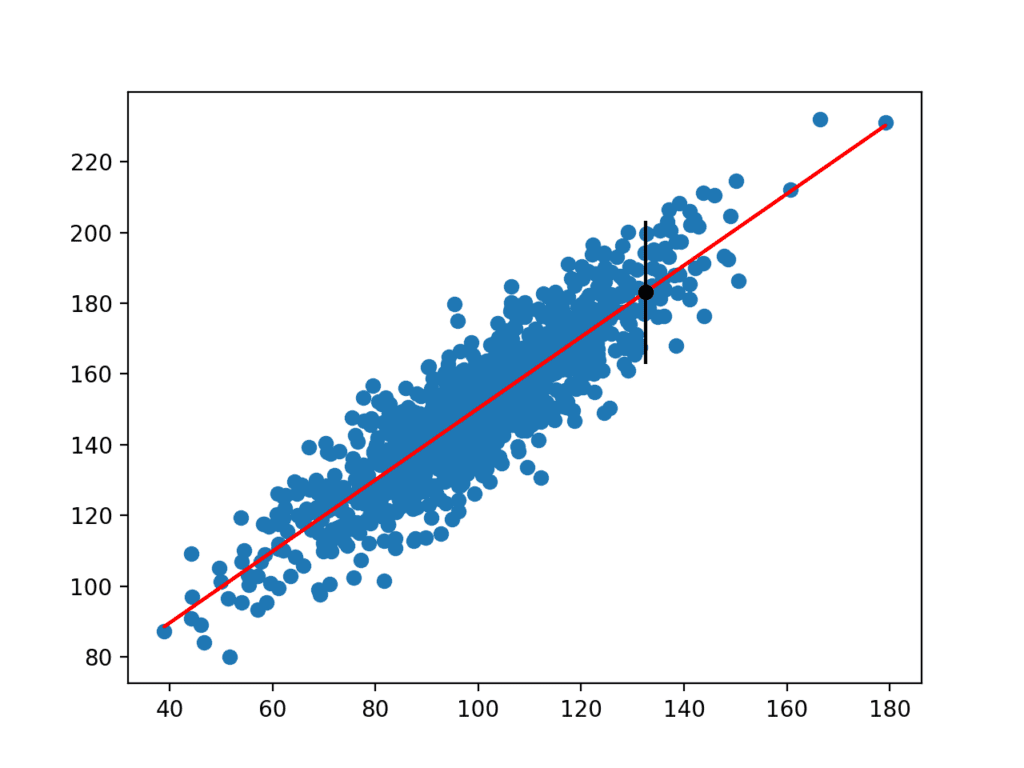
tietokokonaisuuden Hajontakaavio lineaarisella mallilla ja Ennustusvälillä
laajennukset
tässä osiossa luetellaan joitakin ideoita opetusohjelman laajentamiseksi, joita haluat ehkä tutkia.
- summaa toleranssin, luottamuksen ja ennustusvälien välisen eron.
- kehitä lineaarinen regressiomalli tavalliselle koneoppimisen aineistolle ja laske ennustusvälit pienelle testisarjalle.
- kuvaile yksityiskohtaisesti, miten yksi epälineaarinen ennustusvälimenetelmä toimii.
jos tutkit jotain näistä laajennuksista, haluaisin tietää.
lisätietoja
tästä osiosta saa lisää resursseja aiheeseen, jos haluaa mennä syvemmälle.
Posts
- kuinka raportoida luokittajan suorituskyky Luottamusvälein
- Miten lasketaan Bootstrap-luottamusvälit koneoppimisen tuloksille Pythonissa
- ymmärrä aikasarjan ennusteen epävarmuus käyttämällä luottamusvälejä Pythonilla
- arvioi stokastisten Koneoppimisalgoritmien kokeiden määrä
Kirjat
- uusien tilastojen ymmärtäminen: Vaikutuskoot, luottamusvälit ja Meta-analyysi, 2017.
- tilastolliset intervallit: a Guide for Practitioners and Researchers, 2017.
- an Introduction to Statistical Learning: with Applications in R, 2013.
- Introduction to the New Statistics: Estimation, Open Science, and Beyond, 2016.
- Forecasting: principles and practice, 2013.
Papers
- a comparison of some error estimates for neural network models, 1995.
- Machine learning approaches for estimation of prediction interval for the model output, 2006.
- a Comprehensive Review of Neural Network-based Prediction Intervalls and New Advances, 2010.
API
- scipy.tilastot.linregress () API
- matplotlib.pyplot.hajonta () API
- matplotlib.pyplot.errorbar () API
Artikkelit
- Ennustusväli Wikipediassa
- Bootstrap-ennustusväli ristiin validoidulla
Yhteenveto
tässä opetusohjelmassa selvitit ennustusvälin ja sen laskemisen yksinkertaiselle lineaariselle regressiomallille.
erityisesti opit:
- , että ennustusväli kvantifioi yhden pisteen ennustuksen epävarmuutta.
- että ennustusvälit voidaan arvioida analyyttisesti yksinkertaisille malleille, mutta ne ovat haastavampia epälineaarisille koneoppimismalleille.
- kuinka lasketaan ennusteväli yksinkertaiselle lineaariselle regressiomallille.
onko sinulla kysyttävää?
kysy kysymyksesi alla olevissa kommenteissa ja teen parhaani vastatakseni.
ota haltuun koneoppimisen tilastot!

kehittävät työskentelyymmärrystä tilastoista
…kirjoittamalla koodirivejä Pythonilla
Discover how in my new Ebook:
Statistical Methods for Machine Learning
It provides self-study tutorials on topics like:
Hypothesis Tests, Correlation, Nonparametric Stats, Resampling, and much more…
selvitä, miten Data muutetaan tiedoksi
Ohita akateemikot. Pelkkiä Tuloksia.
see What ’ s Inside