Version info: Code for this page was tested in Stata 12.
Poisson-regressiota käytetään mallintamaan muuttujien määrää.
huomaa: tämän sivun tarkoituksena on näyttää, miten käytetään erilaisia tietojen analysointikomentoja. Se ei kata kaikkia tutkimusprosessin näkökohtia, joita tutkijoiden odotetaan tekevän. Se ei kata etenkään tietojen puhdistamista ja tarkistamista, oletusten todentamista, mallidiagnostiikkaa tai mahdollisia seuranta-analyysejä.
Examples of Poisson regression
Esimerkki 1. Muulin tai hevosen potkuihin kuolleiden määrä Preussin armeijassa vuodessa.Ladislaus Bortkiewicz keräsi tietoja 20 volyymit ofPreussischen Statistik. Nämä tiedot kerättiin Preussin armeijan 10 armeijakunnasta 1800-luvun lopulla 20 vuoden aikana.
Esimerkki 2. Ruokakaupassa edessä jonottavien ihmisten määrä. Ennusteisiin voi sisältyä se, kuinka paljon tuotteita tarjotaan tällä hetkellä alennettuun hintaan ja onko erityinen tapahtuma (esim.loma, suuri urheilutapahtuma) kolmen tai vähemmän päivän päässä.
esimerkki 3. Yhden lukion opiskelijoiden saamien palkintojen määrä. Palkintojen määrää ennustavat muun muassa se, millaiseen ohjelmaan opiskelija oli kirjoilla (esim.ammatillinen, yleissivistävä tai akateeminen), sekä matematiikan loppukokeiden pisteet.
tietojen kuvaus
havainnollistamista varten olemme simuloineet tietojoukon esimerkiksi 3 yllä. Tässä esimerkissä num_awards on tulosmuuttuja ja ilmaisee opiskelijoiden saamien palkintojen määrän lukiossa vuodessa, matematiikka on jatkuva predikaattorimuuttuja ja edustaa opiskelijoiden pistemääriä matematiikan loppukokeessa, ja prog on kategorinen predikaattorimuuttuja, jossa on kolme tasoa, jotka ilmaisevat ohjelman tyypin, johon opiskelijat olivat kirjoilla.
aloitetaan lataamalla aineisto ja katsomalla kuvailevia tilastoja.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
jokaisella muuttujalla on 200 pätevää havaintoa ja niiden jakaumat vaikuttavat varsin kohtuullisilta. Tässä yhteydessä tulosmuuttujan ehdoton keskiarvo ja varianssi eivät ole kovin erilaisia.
jatketaan tämän aineiston muuttujien kuvausta. Alla oleva taulukko näyttää palkintojen keskimääräiset määrät ohjelmatyypeittäin ja näyttää viittaavan siihen, että ohjelmatyyppi on hyvä ehdokas palkintojen määrän ennustamiseen, meidän tulosmuuttujamme, koska tuloksen keskiarvo näyttää vaihtelevan prog: n mukaan.
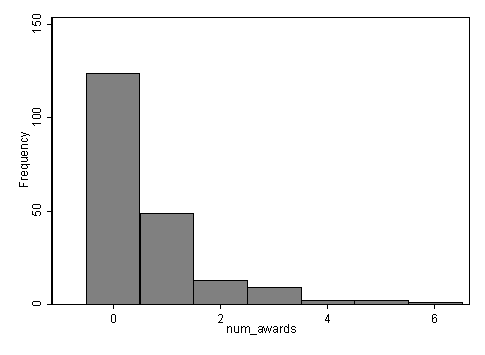
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
analyysimenetelmät, joita voit harkita
alla on luettelo mahdollisesti kohtaamistasi analyysimenetelmistä. Jotkin listatuista menetelmistä ovat varsin järkeviä, kun taas toiset ovat joko jääneet pois suosiosta tai niillä on rajoituksia.
- Poisson – regressiota käytetään usein laskentatietojen mallintamiseen. Poisson-regressiolla on useita laskentamalleille hyödyllisiä laajennuksia.
- negatiivinen Binomiregressio – negatiivista binomiregressiota voidaan käyttää yli-dispergoiduille laskutiedoille, eli kun ehdollinen varianssi ylittää ehdollisen keskiarvon. Sitä voidaan pitää Poisson-regression yleistyksenä, koska sillä on sama keskirakenne kuin Poisson-regressiolla ja sillä on ylimääräinen parametri mallintamaan ylidispersiota. Jos tulosmuuttujan ehdollinen jakauma on ylijakaumallinen, negatiivisen Binomirregression luottamusvälit ovat todennäköisesti kapeammat kuin Poisson-regressiossa.
- Nollapullotetut regressiomallit-Nollapullotetut mallit yrittävät selittää ylimääräisten nollien määrän. Toisin sanoen aineistossa ajatellaan olevan kahdenlaisia nollia, ”oikeita nollia” ja ”ylimääräisiä nollia”. Nollapistemalleissa arvioidaan samanaikaisesti kahta yhtälöä, joista toinen on laskentamallille ja toinen ylimääräisille nollille.
- OLS – regressiomuuttujat muunnetaan joskus log-muunnoksiksi ja analysoidaan OLS-regression avulla. Monet ongelmat syntyvät tämän lähestymistavan, mukaan lukien tietojen menetys johtuu määrittelemättömistä arvoista, jotka syntyvät ottamalla log of zero (joka on määrittelemätön) ja puolueellisia arvioita.
Poisson-regressio
alla käytetään poisson-komentoa estimoimaan Poisson-regressiomallia. I. ennen prog osoittaa, että se on tekijämuuttuja (ts., kategorinen muuttuja), ja että se tulisi sisällyttää malliin indikaattorimuuttujien sarjana.
käytämme VCE(robust) – vaihtoehtoa, jotta saadaan vakaat standardivirheet Cameronin ja Trivedin (2009) suosittelemiin parametrin estimaatteihin, jotta voidaan valvoa taustalla olevien oletusten lievää rikkomista.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
kahden vapausasteen khi-neliötesti osoittaa, että prog on yhdessä laskettuna tilastollisesti merkitsevä num_awardsin ennustaja.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
mallin sopivuuden arvioimiseksi estat gof-komennolla voidaan saada hyvyys-of-fit chi-potenssitesti. Tämä ei ole mallikertoimien testi (jonka näimme otsikkotiedoissa), vaan mallilomakkeen testi: sopiiko poisson-mallilomake tietoihimme?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
päädymme siihen, että malli sopii kohtuullisen hyvin, koska hyvyyskoe ei ole tilastollisesti merkitsevä. Jos testi olisi ollut tilastollisesti merkittävä, se osoittaisi, etteivät tiedot sovi malliin hyvin. Tässä tilanteessa, voimme yrittää määrittää, jos on jätetty pois prediktor muuttujia, jos meidän lineaarisuus oletus pätee ja / tai jos on kysymys yli-dispersion.
joskus haluamme esittää regressiotulokset tapahtumanopeussuhteina, Voimme käyttää niidenr-vaihtoehtoa. Nämä IRR-arvot ovat yhtä suuret kuin meidän kertoimet edellä eksponentioidusta tuotoksesta.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
yllä oleva ulostulo osoittaa, että 2.prog on 2,96 – kertainen verrattuna viiteryhmän (1.prog). Samoin tapahtumataajuus 3.prog on 1,45-kertainen verrattuna vertailuryhmään, joka pitää muut muuttujat vakiona. Prosentuaalinen muutos num_awardsin tapahtumanopeudessa on 7%: n lisäys jokaista matematiikan yksikön lisäystä kohden.
muistuta malliyhtälön muotoa:
log(num_awards) = Intercept + b1(prog=2) + b2(prog=3) + b3math.
Tämä merkitsee:
num_awards = exp(Intercept + b1(prog=2) + B2(prog=3)+ b3math) = exp(Intercept) * exp(B1(prog=2)) * exp(B2(prog=3))) * exp(b3math)
kertoimilla on additiivinen vaikutus log(y) – asteikolla ja IRR: llä multiplikatiivinen vaikutus y-asteikolla.
lisätietoja eri mittareista, joilla tulokset voidaan esittää, ja niiden tulkinnasta, on J. Scott Longin ja Jeremy Freesen julkaisemassa Regressiomalleissa Kategorisista riippuvaisista muuttujista Statan avulla (2006).
ymmärtääksemme mallia paremmin voimme käyttää marginaalit-komentoa. Alla käytetään marginaalit-komentoa ennustettujen lukujen laskemiseen kullakin Prog-tasolla, pitäen kaikki muut muuttujat (tässä esimerkissä matematiikka) mallissa keskiarvoissaan.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
yllä olevasta lähdöstä nähdään, että progin tason 1 tapahtumien ennustettu määrä on noin .21, pitämässä matematiikkaa keskiarvossaan. Ennustettu määrä tapahtumia tasolla 2 prog on suurempi .62, ja ennustettu määrä tapahtumia tasolla 3 prog on noin .31. Huomaa, että Prog: n tason 2 ennustettu lukema on (.6249446/.211411) = 2,96 kertaa suurempi kuin prog: n tason 1 ennustettu määrä. Tämä vastaa sitä, mitä näimme IRR: n tulostaulukossa.
alla saadaan matematiikan arvoille ennustetut lukemat, jotka vaihtelevat 35: stä 75: een 10: n välein.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
yllä olevasta taulukosta käy ilmi, että kun prog on havaintoarvoissaan ja matematiikka on kaikkien havaintojen kohdalla 35, ennustettu keskiarvo (tai palkintojen keskimääräinen lukumäärä) on noin .13; kun math = 75, keskimääräinen ennustettu määrä on noin 2,17. Jos vertaamme ennustettuja laskuja pisteillä math = 35 ja math = 45, voimme nähdä, että suhde on (.2644714/.1311326) = 2.017. Tämä vastaa 1.0727: n IRR: ää 10 yksikön vaihtuessa: 1.0727^10 = 2.017.
käyttäjän kirjoittamalla fitstat-komennolla (sekä Statan estat-komennoilla) voi saada lisätietoa, josta voi olla hyötyä, jos haluaa vertailla malleja. Voit ladata tämän ohjelman kirjoittamalla search fitstat (katso kuinka voin käyttää hakukomentoa etsiäkseni ohjelmia ja saadakseni lisäapua? lisätietoja hakujen käytöstä).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
voit piirtää ennustetun tapahtumamäärän alla olevilla komennoilla. Graafi osoittaa, että eniten palkintoja ennustetaan akateemisessa ohjelmassa oleville (prog = 2), varsinkin jos opiskelijalla on korkeat matematiikan pisteet. Vähiten ennustettuja palkintoja on yleisohjelman opiskelijoille (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
harkittavia asioita
- Jos ylikunto näyttää olevan ongelma, ensin tarkista, onko mallimme asianmukaisesti määritelty, kuten poistetut muuttujat ja funktionaaliset lomakkeet. Jos esimerkiksi jättäisimme pois predikaattorimuuttujan progin edellä mainitussa esimerkissä, mallillamme näyttäisi olevan ongelma liiallisen hajonnan kanssa. Toisin sanoen väärin määritelty malli voi aiheuttaa oireen, kuten liiallisen hajontaongelman.
- olettaen, että malli on määritetty oikein, voit tarkistaa, onko se ylivirittynyt. Tämä voidaan tehdä useilla tavoilla, mukaan lukien todennäköisyyssuhdetesti ylidispersioparametri Alfalle ajamalla sama regressiomalli käyttäen negatiivista binomijakaumaa (nbreg).
- yksi yleinen liikahajonnan aiheuttaja ovat ylimääräiset nollat, jotka puolestaan syntyvät lisädataa tuottavassa prosessissa. Tässä tilanteessa pitäisi harkita nollapistemallia.
- Jos tietojen tuottamisprosessi ei mahdollista mitään 0s: ää (kuten sairaalassa vietettyjen päivien määrää), nollatynkä-malli voi olla tarkoituksenmukaisempi.
- Laskentatiedoissa on usein altistusmuuttuja, joka kertoo kuinka monta kertaa tapahtuma on voinut tapahtua. Tämä muuttuja liitetään Poisson-malliin Exp () – vaihtoehdon avulla.
- Loppumuuttujalla Poisson-regressiossa ei voi olla negatiivisia lukuja, eikä valotuksella voi olla 0s.
- Statassa Poisson-Malli voidaan arvioida glm-komennolla log-linkin ja Poisson-perheen avulla.
- sinun täytyy käyttää GLM-komentoa saadaksesi jäännökset tarkistaaksesi muita Poisson-mallin oletuksia (katso Cameron and Trivedi (1998) ja Dupont (2002) lisätietoja).
- pseudo-R-potenssiin on olemassa monia erilaisia mittoja. Ne kaikki pyrkivät antamaan samanlaista tietoa kuin R-potenssiin OLS-regressiossa, vaikka mitään niistä ei voida tulkita täsmälleen samalla tavalla kuin R-potenssiin OLS-regressiossa. Jos haluat keskustella eri pseudo-R-neliöt, katso Long and Freese (2006) tai meidän FAQ pageWhat ovat pseudo R-squareds?.
- Poisson-regressio estimoidaan suurimman todennäköisyyden estimoinnin avulla. Se vaatii yleensä suuren otoskoon.
Katso myös
- kommentoitu ulostulo poisson-komennolle
- Stata FAQ: Miten voin käyttää countfitiä laskentamallin valinnassa?
- Stata online manual
- poisson
- Stata FAQs
- miten Poissonin ja nbregin insidence-rate ratioille (IRRs) lasketaan keskivirheet ja luottamusvälit?