mitä on vahvistaminen oppiminen?
vahvistaminen oppiminen määritellään koneoppimisen menetelmäksi, joka käsittelee sitä, miten ohjelmistoagenttien tulisi toimia ympäristössä. Vahvistaminen oppiminen on osa syväoppimismenetelmää, jonka avulla voit maksimoida osan kumulatiivisesta palkitsemisesta.
tämä neuroverkkooppimismenetelmä auttaa sinua oppimaan, miten saavuttaa monimutkainen tavoite tai maksimoida tietty ulottuvuus monien vaiheiden aikana.
Vahvennusoppimisen tutoriaalissa opit:
- mitä on Vahvistusoppiminen?
- tärkeitä termejä, joita käytetään Syvävahvistuksen oppimismenetelmässä
- miten vahvistaminen oppiminen toimii?
- Vahvisteoppimisen algoritmit
- Vahvisteoppimisen ominaisuudet
- Vahvisteoppimisen tyypit
- Vahvisteoppimisen oppimismallit
- Vahvisteoppimisen oppimismallit vs. Ohjattu oppiminen
- Vahvisteoppimisen Sovellukset
- Miksi käyttää Vahvisteoppimista?
- milloin ei kannata käyttää Vahvistusoppimista?
- Vahvennusoppimisen haasteet
Syvävahvistusoppimismenetelmässä käytetyt tärkeät termit
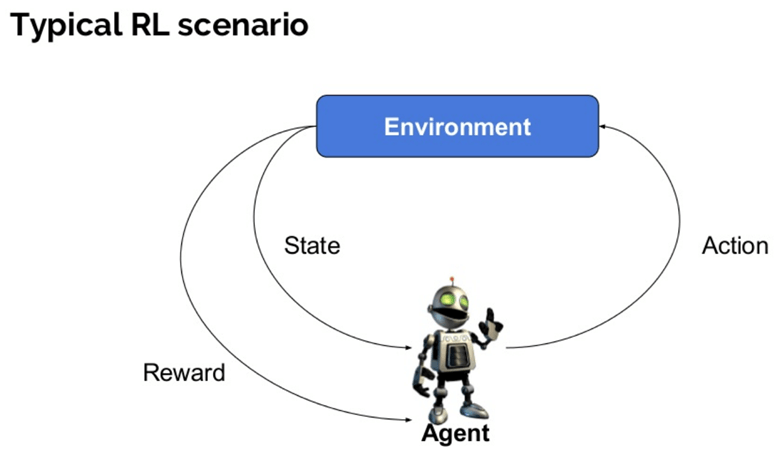
Tässä muutamia tärkeitä Vahvennusälyssä käytettyjä termejä:
- agentti: oletettu yhteisö, joka suorittaa toimia ympäristössä saadakseen jonkin palkkion.
- ympäristö (e): skenaario, joka agentin on kohdattava.
- palkinto (P): Välitön palautus, joka annetaan agentille, kun hän suorittaa tiettyä toimintaa tai tehtävää.
- valtio (t): valtio tarkoittaa ympäristön palauttamaa nykytilannetta.
- politiikka (?): Se on strategia, jota agentti soveltaa päättääkseen seuraavasta toimesta nykytilan perusteella.
- arvo (V): odotettavissa on pitkän aikavälin tuotto alennuksella verrattuna lyhytaikaiseen palkkioon.
- Arvofunktio: se määrittää valtion arvon, joka on palkkion kokonaismäärä. Se on agentti, joka on odotettavissa alkaen siitä valtiosta.
- ympäristön malli: Tämä jäljittelee ympäristön käyttäytymistä. Se auttaa tekemään johtopäätöksiä ja myös määrittämään, miten ympäristö käyttäytyy.
- Model based methods: se on malli-pohjaisia menetelmiä käyttävä menetelmä vahvistaminen-oppimisongelmien ratkaisemiseen.
- Q-arvo tai toiminta-arvo (Q): Q-arvo on melko samanlainen kuin arvo. Ainoa ero näiden kahden välillä on, että se vie lisäparametrin nykyisenä toimintana.
miten vahvistaminen oppiminen toimii?
katsotaanpa yksinkertainen esimerkki, joka auttaa havainnollistamaan vahvistuksen oppimismekanismia.
harkitse skenaariota, jossa kissallesi opetetaan uusia temppuja
- koska kissa ei ymmärrä englantia tai mitään muutakaan ihmiskieltä, emme voi sanoa hänelle suoraan mitä tehdä. Sen sijaan noudatamme erilaista strategiaa.
- matkimme tilannetta, ja kissa yrittää vastata monin eri tavoin. Jos kissan vastaus on toivottu, annamme sille kalaa.
- nyt aina kun kissa altistuu samalle tilanteelle, kissa suorittaa samanlaisen teon entistäkin innokkaammin odottaen saavansa lisää palkkiota(ruokaa).
- se on kuin oppisi, että kissa saa ”mitä tehdä” positiivisista kokemuksista.
- samalla kissa oppii myös, mitä ei tee kohdatessaan negatiivisia kokemuksia.
selitys esimerkistä:
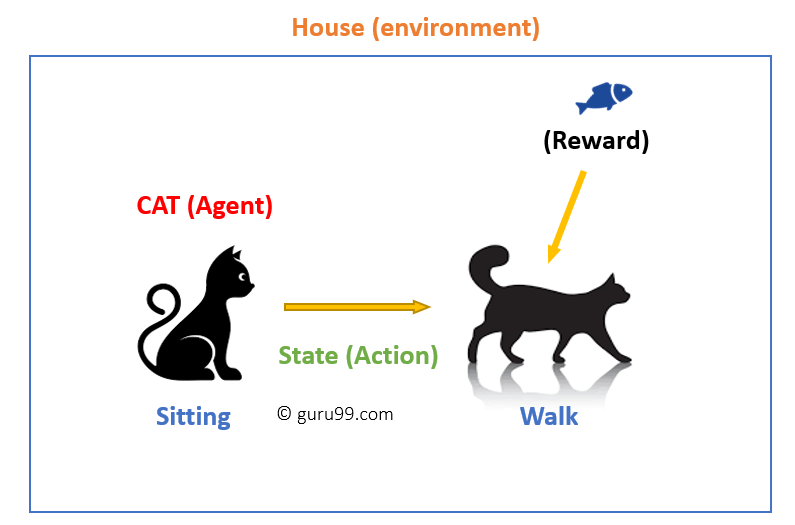
tässä tapauksessa
- kissasi on ympäristölle altistuva aine. Tässä tapauksessa se on sinun talosi. Esimerkki valtion voisi olla kissan istuu, ja käytät tiettyä sanaa kissa kävellä.
- agenttimme reagoi suorittamalla toiminnan siirtymisen yhdestä ”tilasta” toiseen ”tilaan.”
- esimerkiksi kissasi kulkee istumisesta kävelyyn.
- agentin reaktio on toiminta, ja politiikka on tapa valita toiminta, joka annetaan tilaan, jossa odotetaan parempia tuloksia.
- siirtymän jälkeen he voivat saada palkkion tai rangaistuksen vastineeksi.
Vahvisteoppimisalgoritmeja
on kolme tapaa toteuttaa Vahvisteoppimisalgoritmi.
arvoperusteinen:
arvoperusteisessa Vahvistuskoulutusmenetelmässä kannattaa pyrkiä maksimoimaan arvofunktio V(s). Tässä menetelmässä agentti odottaa nykyisten valtioiden pitkän aikavälin paluuta politiikan alle ?.
Policy-based:
policy-based RL-menetelmässä yritetään keksiä sellainen linjaus, että jokaisessa valtiossa tehty toiminta auttaa saamaan mahdollisimman suuren palkkion tulevaisuudessa.
kahdenlaisia politiikkatapoja on:
- deterministisiä: minkä tahansa valtion kohdalla sama toiminta syntyy politiikasta ?.
- Stokastinen: jokaisella aktiolla on tietty todennäköisyys, joka määräytyy seuraavan yhtälön avulla.Stokastinen politiikka:
n{a\s) = P\A, = a\S, =S]
mallipohjainen:
tässä Vahvistusoppimismenetelmässä jokaiselle ympäristölle pitää luoda virtuaalinen malli. Agentti oppii esiintymään siinä tietyssä ympäristössä.
Vahvistusoppimisen ominaisuudet
tässä on tärkeitä vahvistusoppimisen ominaisuuksia
- valvojaa ei ole, vain reaaliluku tai palkitsemissignaali
- Jaksollinen päätöksenteko
- aika on ratkaisevassa roolissa Vahvistusongelmissa
- palautteen anto viivästyy aina, ei hetkellinen
- agentin toiminta määrää sen saaman myöhemmän tiedon
Vahvistusoppimisen tyypit
kahdenlaisia vahvistusoppimistapoja on:
positiivisia:
se määritellään tapahtumaksi, joka tapahtuu tietyn käyttäytymisen vuoksi. Se lisää käyttäytymisen voimakkuutta ja taajuutta ja vaikuttaa positiivisesti agentin toimintaan.
tämän tyyppinen vahvistaminen auttaa maksimoimaan suorituskyvyn ja ylläpitämään muutosta pidempään. Liika vahvistaminen voi kuitenkin johtaa tilan ylioptimointiin, mikä voi vaikuttaa tuloksiin.
negatiivinen:
negatiivinen vahvistaminen määritellään sellaisen käyttäytymisen vahvistumisena, joka johtuu negatiivisesta tilasta, jonka olisi pitänyt loppua tai välttää. Se auttaa määrittelemään suorituskyvyn minimitason. Tämän menetelmän haittapuolena on kuitenkin se, että se tarjoaa tarpeeksi täyttämään minimikäyttäytymisen.
vahvistuksen oppimismalleja
vahvistusoppimisessa on kaksi tärkeää oppimismallia:
- Markovin päätösprosessi
- Q oppiminen
Markovin päätösprosessi
seuraavien parametrien avulla saadaan ratkaisu:
- joukko toimia – a
- joukko valtioita-s
- Reward – R
- Policy – n
- Value – V
matemaattinen lähestymistapa vahvistusoppimisen ratkaisun kartoittamiseen on recon as a Markov Decision Process or (MDP).
Q-Learning
Q-learning on arvopohjainen menetelmä, jolla annetaan tietoa siitä, mihin toimiin agentin tulisi ryhtyä.
ymmärretään tämä menetelmä seuraavalla esimerkillä:
- rakennuksessa on viisi huonetta, jotka on yhdistetty ovilla.
- jokainen huone on numeroitu 0-4
- rakennuksen ulkopuoli voi olla yksi iso ulkoalue (5)
- ovet numero 1 ja 4 johtavat rakennukseen huoneesta 5
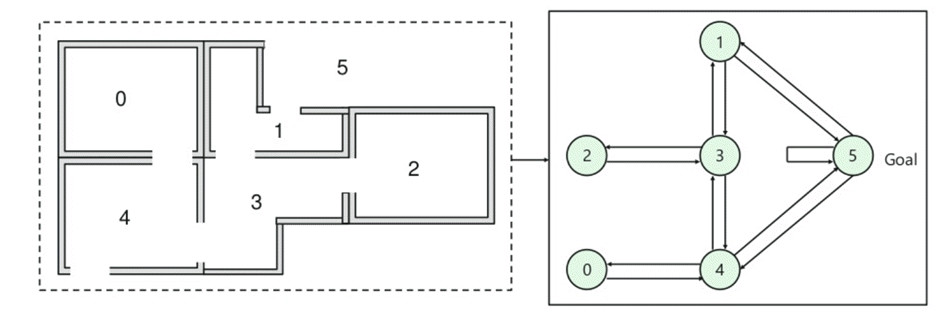
seuraavaksi jokaiseen oveen pitää liittää palkkioarvo:
- suoraan maaliin johtavien ovien palkkio on 100
- ovet, jotka eivät ole suoraan yhteydessä kohdehuoneeseen, antavat nollapalkkion
- koska ovet ovat kaksisuuntaisia ja jokaista huonetta kohti on määrätty kaksi nuolta
- jokainen yllä olevan kuvan nuoli sisältää välittömän palkintoarvon
selitys:
tässä kuvassa voit katsoa, että huone edustaa tilaa
agentin liike huoneesta toiseen edustaa toimintaa
alla olevassa kuvassa tila kuvataan solmuksi, kun taas nuolet näyttävät toiminnan.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Valvottu oppiminen
| parametrit | valvottu oppiminen | valvottu oppiminen |
| Päätöksentekotyyli | vahvistaminen oppiminen auttaa tekemään päätökset peräkkäin. | tässä menetelmässä tehdään päätös alussa annetusta syötteestä. |
| toimii | toimii vuorovaikutuksessa ympäristön kanssa. | toimii esimerkeillä tai annetuilla otostiedoilla. |
| riippuvuus päätöksestä | RL metodin oppimispäätös on riippuvainen. Siksi sinun pitäisi antaa etikettejä kaikille riippuvaisille päätöksille. | valvottu oppiminen päätöksistä, jotka ovat toisistaan riippumattomia, joten jokaiselle päätökselle annetaan Leimat. |
| parhaiten sopii | tukee ja toimii paremmin tekoälyssä, jossa ihmisten vuorovaikutus on yleistä. | se toimii useimmiten interaktiivisella ohjelmistojärjestelmällä tai sovelluksilla. | esimerkki | shakkipeli | Oliotunnistus |
Raudoitusoppimisen Sovellukset
tässä ovat Raudoitusoppimisen Sovellukset:
- robotiikka teollisuusautomaatioon.
- liiketoimintastrategian suunnittelu
- Koneoppiminen ja tietojenkäsittely
- Sen avulla voidaan luoda koulutusjärjestelmiä, jotka tarjoavat räätälöityä opetusta ja materiaaleja opiskelijoiden tarpeiden mukaan.
- Lentokoneohjaus ja robotin Liikkeenohjaus
Miksi käyttää Tehosteoppimista?
tässä on tärkeimmät syyt Vahvennusoppimisen käyttöön:
- se auttaa löytämään, mikä tilanne vaatii toimintaa
- auttaa löytämään, mikä toiminta tuottaa suurimman palkkion pidemmällä aikavälillä.
- Vahvistusoppiminen antaa myös oppijalle palkitsemistehtävän.
- Sen avulla se voi myös selvittää parhaan tavan saada suuria palkkioita.
milloin ei kannata käyttää Vahvistusoppimista?
vahvistuksen oppimismallia ei voi soveltaa, on kaikki tilanne. Tässä on joitakin ehtoja, kun sinun ei pitäisi käyttää vahvistaminen oppimismalli.
- kun tietoa on riittävästi ongelman ratkaisemiseen ohjatulla oppimismenetelmällä
- , on muistettava, että Vahvistusoppiminen on tietotekniikkaa vaativaa ja aikaa vievää. erityisesti silloin, kun toimintatilaa on suuri.
Vahvennusoppimisen haasteet
tässä ovat Vahvennusoppimisen suurimmat haasteet:
- ominaisuus/palkitseminen, jonka tulisi olla hyvin mukana
- parametrit voivat vaikuttaa oppimisen nopeuteen.
- realistisilla ympäristöillä voi olla osittainen havainnoitavuus.
- liika vahvistaminen voi johtaa tilojen ylikuormittumiseen, mikä voi heikentää tuloksia.
- realistiset ympäristöt voivat olla ei-stationaarisia.
Yhteenveto:
- Tehosteoppiminen on koneoppimisen menetelmä
- auttaa selvittämään, mistä toiminnasta saa pidemmällä aikavälillä suurimman palkkion.
- kolme oppimisen vahvistamismenetelmää ovat 1) Arvolähtöinen 2) politiikkalähtöinen ja mallipohjainen oppiminen.
- agentti, tila, palkinto, ympäristö, ympäristön Arvofunktiomalli, mallipohjaiset menetelmät, ovat tärkeitä termejä, joita käytetään rl-oppimismenetelmässä
- esimerkki vahvistusoppimisesta on kissasi on agentti, joka altistuu ympäristölle.
- tämän menetelmän suurin ominaisuus on se, että ei ole ohjaajaa, vain reaaliluku tai palkitsemissignaali
- kahdenlaista vahvistusoppimista ovat 1) positiiviset 2) negatiiviset
- kaksi laajalti käytettyä oppimismallia ovat 1) Markovin päätösprosessi 2) Q oppiminen
- vahvistaminen oppimismenetelmä toimii vuorovaikutuksessa ympäristön kanssa, kun taas ohjattu oppimismenetelmä toimii annetulla otosdatalla tai esimerkillä.
- soveltaminen tai vahvistaminen oppimismenetelmät ovat: Robotiikka teollisuusautomaatioon ja liiketoimintastrategian suunnitteluun
- tätä menetelmää ei kannata käyttää, kun on tarpeeksi tietoa ongelman ratkaisemiseksi
- menetelmän suurin haaste on, että parametrit voivat vaikuttaa oppimisen nopeuteen