Hola y bienvenido a la Guía Ilustrada de Larga Memoria a Corto Plazo (LSTM) y Cerrada Recurrente de Unidades (GRU). Soy Michael, y soy Ingeniero de Aprendizaje Automático en el espacio de asistente de voz de IA.
En este post, comenzaremos con la intuición detrás de LSTM y GRU. Luego explicaré los mecanismos internos que permiten que LSTM y GRU funcionen tan bien. Si quieres entender lo que está sucediendo bajo el capó de estas dos redes, entonces este post es para ti.
También puedes ver la versión en video de esta publicación en youtube si lo prefieres.
Recurrentes Redes Neuronales sufren de la memoria a corto plazo. Si una secuencia es lo suficientemente larga, tendrán dificultades para transportar información de pasos anteriores a pasos posteriores. Por lo tanto, si está tratando de procesar un párrafo de texto para hacer predicciones, las RNN pueden omitir información importante desde el principio.
Durante la propagación hacia atrás, las redes neuronales recurrentes sufren el problema del gradiente de desaparición. Los degradados son valores que se utilizan para actualizar los pesos de una red neuronal. El problema del gradiente de fuga es cuando el gradiente se contrae a medida que se propaga a través del tiempo. Si un valor de gradiente se vuelve extremadamente pequeño, no contribuye demasiado al aprendizaje.

De manera recurrente en las redes neuronales, las capas que conseguir un pequeño gradiente de actualización deja de aprender. Esas suelen ser las capas anteriores. Por lo tanto, debido a que estas capas no aprenden, los RNN pueden olvidar lo que vieron en secuencias más largas, teniendo así una memoria a corto plazo. Si quieres saber más sobre la mecánica de las redes neuronales recurrentes en general, puedes leer mi post anterior aquí.
LSTM y GRU como solución
LSTM y GRU se crearon como solución para la memoria a corto plazo. Tienen mecanismos internos llamados puertas que pueden regular el flujo de información.

Estas puertas pueden aprender que los datos de una secuencia es importante para mantener o desechar. Al hacer eso, puede pasar información relevante por la larga cadena de secuencias para hacer predicciones. Casi todos los resultados de última generación basados en redes neuronales recurrentes se logran con estas dos redes. Los LSTM y GRU se pueden encontrar en reconocimiento de voz, síntesis de voz y generación de texto. Incluso puedes usarlos para generar subtítulos para videos.
Ok, así que al final de este post deberías tener una sólida comprensión de por qué los LSTM y los GRU son buenos procesando secuencias largas. Voy a abordar esto con explicaciones e ilustraciones intuitivas y evitar la mayor cantidad de matemáticas posible.
Intuición
Ok, Comencemos con un experimento mental. Digamos que estás mirando reseñas en línea para determinar si quieres comprar cereales Life (no me preguntes por qué). Primero leerás la reseña y luego determinarás si alguien pensó que era buena o si era mala.

Cuando usted lea el examen, tu cerebro inconscientemente sólo recuerda palabras clave importantes. Recoges palabras como » increíble «y» desayuno perfectamente equilibrado». No te importan mucho las palabras como «esto», «dado», «todo», «debería», etc. Si un amigo te pregunta al día siguiente qué decía la reseña, probablemente no lo recuerdes palabra por palabra. Es posible que recuerde los puntos principales, como «definitivamente compraremos de nuevo». Si te pareces mucho a mí, las otras palabras desaparecerán de la memoria.

Y eso es lo que esencialmente una LSTM o GRU hace. Puede aprender a guardar solo información relevante para hacer predicciones y olvidar datos no relevantes. En este caso, las palabras que recordaste te hicieron juzgar que era bueno.
Revisión de las Redes Neuronales Recurrentes
Para comprender cómo LSTM o GRU logran esto, revisemos la red neuronal recurrente. Un RNN funciona así; las primeras palabras se transforman en vectores legibles por máquina. Luego, el RNN procesa la secuencia de vectores uno por uno.

durante el procesamiento, se pasa a la anterior estado oculto para el siguiente paso de la secuencia. El estado oculto actúa como la memoria de las redes neuronales. Contiene información sobre datos anteriores que la red ha visto antes.

echemos un vistazo a una celda de la RNN a ver cómo calcular el estado oculto. En primer lugar, la entrada y el estado oculto anterior se combinan para formar un vector. Ese vector ahora tiene información sobre la entrada actual y las entradas anteriores. El vector pasa por la activación de tanh, y la salida es el nuevo estado oculto, o la memoria de la red.

Tanh de activación
El tanh de activación se utiliza para ayudar a regular los valores que fluye a través de la red. La función tanh comprime los valores para que siempre estén entre -1 y 1.

Cuando los vectores están fluyendo a través de una red neuronal, que sufre muchas transformaciones, debido a las diferentes operaciones matemáticas. Imaginen un valor que continúa multiplicándose por, digamos, 3. Se puede ver cómo algunos valores pueden explotar y convertirse en astronómicos, haciendo que otros valores parezcan insignificantes.

Una función tanh se asegura de que los valores se mantengan entre -1 y 1, por tanto la regulación de la salida de la red neuronal. Puede ver cómo los mismos valores de arriba permanecen entre los límites permitidos por la función tanh.

de Modo que, una RNN. Tiene muy pocas operaciones internas, pero funciona bastante bien dadas las circunstancias adecuadas (como secuencias cortas). Las RNN utilizan muchos menos recursos computacionales que sus variantes evolucionadas, las LSTM y las GRU.
LSTM
Una LSTM tiene un flujo de control similar al de una red neuronal recurrente. Procesa datos que transmiten información a medida que se propaga hacia adelante. Las diferencias son las operaciones dentro de las celdas del LSTM.

Estas operaciones se utiliza para permitir que el LSTM para mantener o se olvida de la información. Ahora, mirar estas operaciones puede ser un poco abrumador, así que repasaremos esto paso a paso.
Concepto de núcleo
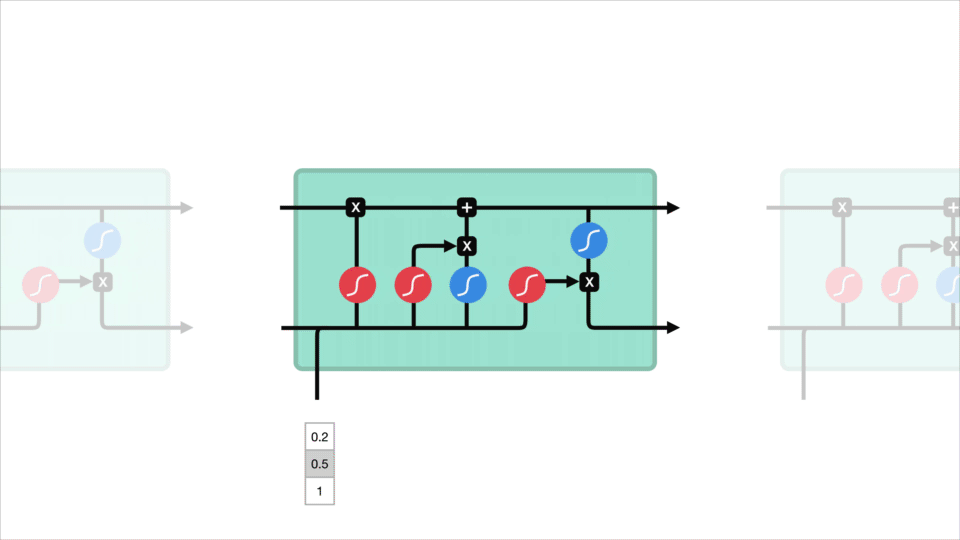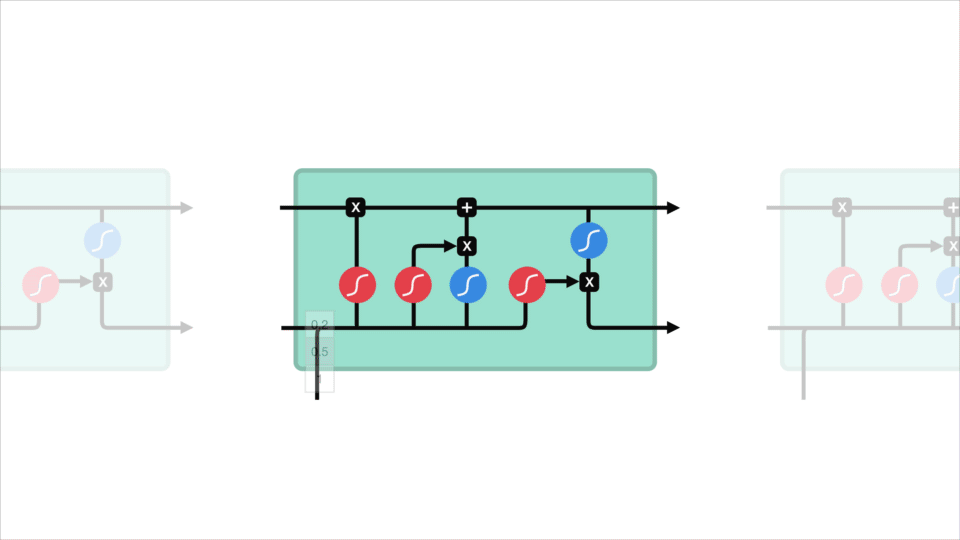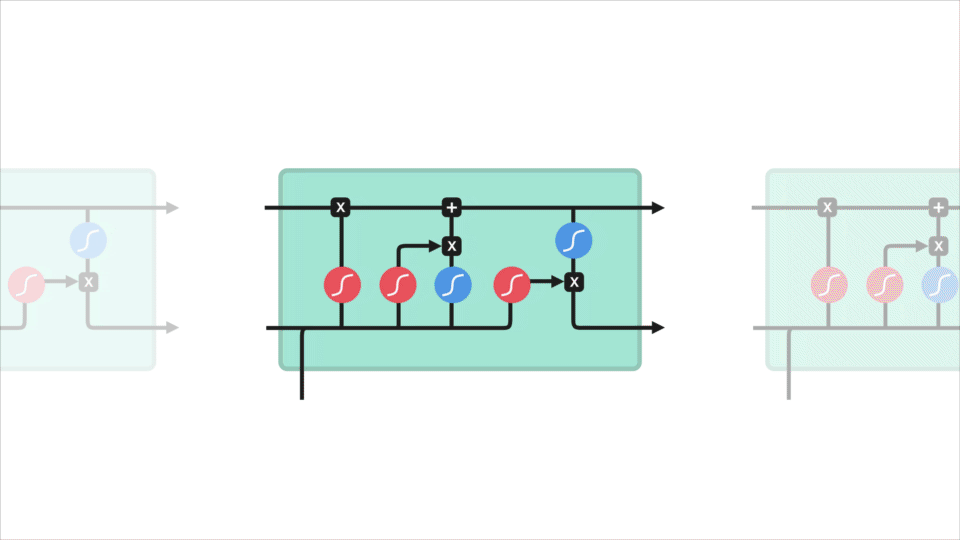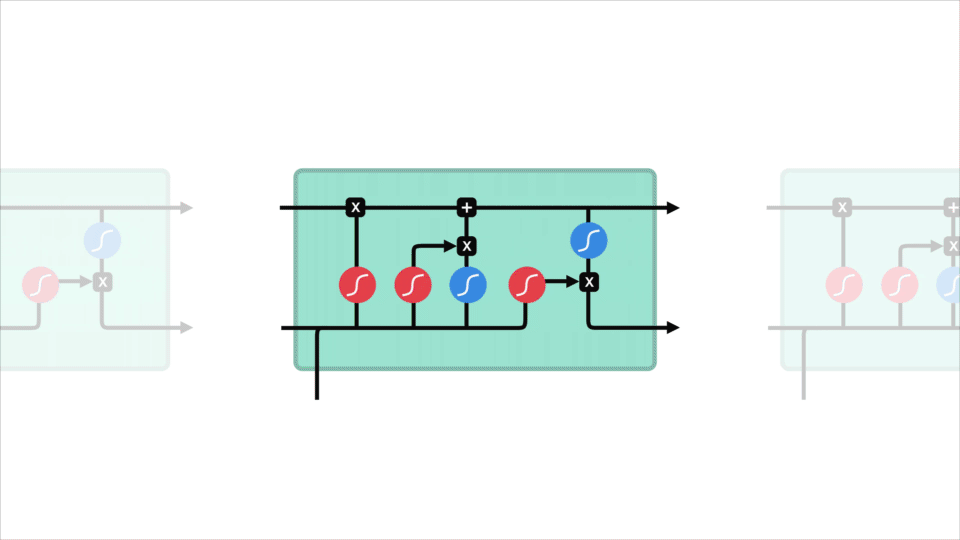
El concepto de núcleo de LSTM es el estado de la celda, y tiene varias puertas. El estado celular actúa como una carretera de transporte que transfiere información relativa hasta el final de la cadena de secuencia. Puedes considerarlo como la «memoria» de la red. El estado de la célula, en teoría, puede llevar información relevante a lo largo del procesamiento de la secuencia. Por lo tanto, incluso la información de los pasos de tiempo anteriores puede llegar a los pasos de tiempo posteriores, lo que reduce los efectos de la memoria a corto plazo. A medida que el estado de la celda avanza, la información se agrega o elimina al estado de la celda a través de puertas. Las puertas son diferentes redes neuronales que deciden qué información se permite en el estado de la célula. Las puertas pueden aprender qué información es relevante para conservar u olvidar durante el entrenamiento.
Sigmoide
las Puertas contiene sigmoide activaciones. Una activación sigmoide es similar a la activación tanh. En lugar de aplastar valores entre -1 y 1, comprime valores entre 0 y 1. Esto es útil para actualizar u olvidar datos porque cualquier número que se multiplica por 0 es 0, lo que hace que los valores desaparezcan o se «olviden».»Cualquier número multiplicado por 1 es el mismo valor, por lo tanto, ese valor permanece igual o se mantiene».»La red puede aprender qué datos no son importantes, por lo tanto, puede olvidarse o qué datos es importante conservar.

Vamos a profundizar un poco más en lo que las diversas puertas que están haciendo, vamos? Así que tenemos tres puertas diferentes que regulan el flujo de información en una celda LSTM. Una puerta de olvido, puerta de entrada y puerta de salida.
Puerta olvidada
Primero, tenemos la puerta olvidada. Esta puerta decide qué información debe desecharse o guardarse. La información del estado oculto anterior y la información de la entrada actual se pasan a través de la función sigmoide. Los valores salen entre 0 y 1. Cuanto más cerca de 0 significa olvidar, y cuanto más cerca de 1 significa mantener.

La Puerta de entrada de
Para actualizar el estado de la celda, tenemos la puerta de entrada. Primero, pasamos el estado oculto anterior y la entrada actual a una función sigmoide. Eso decide qué valores se actualizarán transformando los valores para que estén entre 0 y 1. 0 significa no importante, y 1 significa importante. También pasa el estado oculto y la entrada de corriente a la función tanh para aplastar valores entre -1 y 1 para ayudar a regular la red. Luego se multiplica la salida tanh por la salida sigmoide. La salida sigmoide decidirá qué información es importante mantener de la salida tanh.

El Estado de la celda
Ahora bien, debemos tener la suficiente información para calcular el estado de la célula. Primero, el estado de la celda se multiplica por el vector olvidar. Esto tiene la posibilidad de eliminar valores en el estado de la celda si se multiplica por valores cercanos a 0. Luego tomamos la salida de la puerta de entrada y hacemos una adición puntual que actualiza el estado de la celda a nuevos valores que la red neuronal considera relevantes. Eso nos da nuestro nuevo estado celular.

La salida de la Puerta
por Último, tenemos la salida de la puerta. La puerta de salida decide cuál debe ser el siguiente estado oculto. Recuerde que el estado oculto contiene información de entradas anteriores. El estado oculto también se utiliza para las predicciones. Primero, pasamos el estado oculto anterior y la entrada actual a una función sigmoide. Luego pasamos el estado de celda recién modificado a la función tanh. Multiplicamos la salida tanh con la salida sigmoide para decidir qué información debe llevar el estado oculto. La salida es el estado oculto. El nuevo estado de celda y el nuevo estado oculto se transfieren al siguiente paso de tiempo.

Para la revisión, el Olvidar puerta decide lo que es relevante para mantener a los anteriores pasos. La puerta de entrada decide qué información es relevante agregar del paso actual. La puerta de salida determina cuál debe ser el siguiente estado oculto.
Demo de código
Para aquellos de ustedes que entienden mejor al ver el código, aquí hay un ejemplo usando pseudo código python.

1. Primero, el estado oculto anterior y la entrada actual se concatenan. Lo llamaremos combinar.
2. Combine los alimentos de get en la capa de olvidar. Esta capa elimina datos no relevantes.
4. Se crea una capa candidata mediante combinar. El candidato contiene valores posibles para agregar al estado de la celda.
3. Combine también la alimentación de get en la capa de entrada. Esta capa decide qué datos del candidato deben agregarse al nuevo estado de celda.
5. Después de calcular la capa de olvido, la capa candidata y la capa de entrada, el estado de la celda se calcula utilizando esos vectores y el estado de la celda anterior.
6. La salida se calcula entonces.
7. La multiplicación puntual de la salida y el nuevo estado de celda nos da el nuevo estado oculto.
Eso es todo! El flujo de control de una red LSTM son unas pocas operaciones de tensor y un bucle for. Puede usar los estados ocultos para las predicciones. Combinando todos esos mecanismos, un LSTM puede elegir qué información es relevante recordar u olvidar durante el procesamiento de secuencias.
GRU
Ahora que sabemos cómo funciona un LSTM, veamos brevemente el GRU. El GRU es la nueva generación de redes neuronales Recurrentes y es bastante similar a un LSTM. GRU se deshizo del estado de la celda y usó el estado oculto para transferir información. También solo tiene dos puertas, una puerta de reinicio y una puerta de actualización.

Actualización de la Puerta
La actualización de la puerta actúa de manera similar a la olvide y la puerta de entrada de un LSTM. Decide qué información desechar y qué nueva información agregar.
Reset Gate
La puerta de reset es otra puerta que se utiliza para decidir cuánta información pasada olvidar.
Y eso es un GRU. GRU tiene menos operaciones de tensor; por lo tanto, son un poco más rápidos para entrenar que los LSTM. No hay un ganador claro cuál es mejor. Los investigadores y los ingenieros generalmente intentan ambos para determinar cuál funciona mejor para su caso de uso.
Así que eso es todo
Para resumir esto, los RNN son buenos para procesar datos de secuencia para predicciones, pero sufren de memoria a corto plazo. Los LSTM y GRU se crearon como un método para mitigar la memoria a corto plazo utilizando mecanismos llamados gates. Las puertas son solo redes neuronales que regulan el flujo de información que fluye a través de la cadena de secuencias. Los LSTM y GRU se utilizan en aplicaciones de aprendizaje profundo de última generación como reconocimiento de voz, síntesis de voz, comprensión del lenguaje natural, etc.
Si estás interesado en profundizar, aquí hay enlaces de algunos recursos fantásticos que pueden darte una perspectiva diferente para entender LSTM y GRU.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/