William Wold
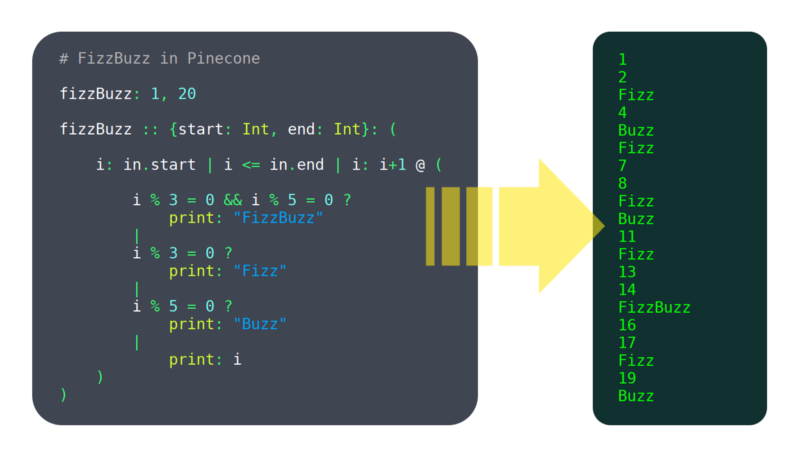
az elmúlt 6 hónapban egy Pinecone nevű programozási nyelven dolgoztam. Még nem nevezném érettnek, de már elég funkciója van ahhoz, hogy használható legyen, például:
- változók
- függvények
- felhasználó által definiált struktúrák
Ha érdekel, nézd meg a Pinecone céloldalát vagy annak GitHub repóját.
nem vagyok szakértő. Amikor elkezdtem ezt a projektet, fogalmam sem volt, mit csinálok, és még mindig nem. nulla órát vettem a nyelvalkotásról, csak egy kicsit olvastam róla az interneten, és nem sok tanácsot követtem.
és mégis teljesen új nyelvet készítettem. És működik. Tehát valamit jól kell csinálnom.
ebben a bejegyzésben a motorháztető alá merülök, és megmutatom a Pinecone (és más programozási nyelvek) csővezetékét, amellyel a forráskódot varázslatgá változtatják.
azt is érinteni néhány kompromisszumok már volt, hogy, és miért hoztam a döntéseket tettem.
ez egyáltalán nem egy teljes bemutató a programozási nyelv írásáról, de jó kiindulópont, ha kíváncsi a nyelvfejlesztésre.
első lépések
“fogalmam sincs, hol is kezdeném” van valami, amit sokat hallok, amikor azt mondom más fejlesztőknek, hogy nyelvet írok. Abban az esetben, ha ez a reakciód, most megyek át néhány kezdeti döntést, amelyeket meghoznak, és lépéseket tesznek, amikor bármilyen új nyelvet elindítanak.
lefordított vs értelmezett
a nyelveknek két fő típusa van: lefordított és értelmezett:
- a fordító kitalál mindent, amit EGY program meg fog tenni, “gépi kódgá” alakítja (olyan formátumba, amelyet a számítógép nagyon gyorsan képes futtatni), majd elmenti, hogy később végrehajtsa.
- a tolmács sorról sorra lép át a forráskódon, kitalálva, hogy mit csinál, ahogy megy.
technikailag bármely nyelv lefordítható vagy értelmezhető, de az egyiknek vagy a másiknak általában több értelme van egy adott nyelv számára. Általában a tolmácsolás általában rugalmasabb, míg a fordítás általában nagyobb teljesítményű. De ez csak egy nagyon összetett téma felületét karcolja meg.
nagyra értékelem a teljesítményt, és láttam, hogy hiányoznak a nagy teljesítményű és egyszerűségorientált programozási nyelvek, ezért a compiled for Pinecone-t választottam.
Ez egy fontos döntés volt, amelyet korán meg kellett hozni, mert sok nyelvtervezési döntést befolyásol (például a statikus gépelés nagy előnye a lefordított nyelveknek, de nem annyira az értelmezett nyelveknek).
annak ellenére, hogy a Pinecone-t a fordítás szem előtt tartásával tervezték, van egy teljesen működőképes tolmácsa, amely az egyetlen módja annak, hogy egy ideig futtassa. Ennek számos oka van, amelyeket később elmagyarázok.
nyelv kiválasztása
tudom, hogy ez egy kicsit meta, de a programozási nyelv maga is program, ezért meg kell írni egy nyelven. A C++ – t a teljesítménye és a nagy funkciókészlet miatt választottam. Egyébként nagyon szeretek C++ – ban dolgozni.
ha értelmezett nyelvet írsz, sok értelme van lefordított nyelven írni (például C, C++ vagy Swift), mert a tolmács és a tolmács tolmácsoló nyelvén Elveszett teljesítmény összetett lesz.
ha fordítást tervez, akkor egy lassabb nyelv (például Python vagy JavaScript) elfogadhatóbb. A fordítási idő rossz lehet, de véleményem szerint ez közel sem olyan nagy ügy, mint a rossz futási idő.
magas szintű tervezés
a programozási nyelv általában csővezetékként van felépítve. Vagyis több szakaszból áll. Minden szakaszban az adatok meghatározott, jól meghatározott módon vannak formázva. Ezenkívül funkciói vannak az adatok átalakítására az egyes szakaszokról a következőre.
az első szakasz egy karakterlánc, amely a teljes bemeneti forrásfájlt tartalmazza. Az utolsó szakasz futtatható. Mindez világossá válik, amikor lépésről lépésre haladunk át a Pinecone csővezetéken.
Lexing

a legtöbb programozási nyelv első lépése a lexing vagy a tokenizálás. A’ Lex ‘ a lexikai elemzés rövidítése, egy nagyon divatos szó egy csomó szöveg tokenekre bontására. A ‘tokenizer’ szónak sokkal több értelme van, de a ‘lexer’ annyira szórakoztató azt mondani, hogy egyébként is használom.
tokenek
a token egy nyelv kis egysége. A token lehet változó vagy függvénynév (más néven azonosító), operátor vagy szám.
A Lexer feladata
a lexer egy egész fájl értékű forráskódot tartalmazó karakterláncot vesz fel, és kiköp egy listát, amely minden tokent tartalmaz.
a csővezeték jövőbeli szakaszai nem utalnak vissza az eredeti forráskódra, ezért a lexernek minden szükséges információt meg kell adnia. Ennek a viszonylag szigorú csővezeték-formátumnak az az oka, hogy a lexer olyan feladatokat végezhet, mint például a Megjegyzések eltávolítása vagy annak észlelése, hogy valami szám vagy azonosító. Ezt a logikát zárva akarja tartani a lexerben, mindkettőt, hogy ne kelljen ezekre a szabályokra gondolnia a nyelv többi részének írásakor, és így az ilyen típusú szintaxist egy helyen megváltoztathatja.
Flex
azon a napon, amikor elkezdtem a nyelvet, az első dolog, amit írtam, egy egyszerű lexer volt. Nem sokkal ezután elkezdtem olyan eszközöket tanulni, amelyek állítólag egyszerűbbé és kevésbé hibássá teszik a lexinget.
az uralkodó ilyen eszköz a Flex, egy olyan program, amely lexereket generál. Olyan fájlt adsz neki, amelynek speciális szintaxisa van a nyelv nyelvtanának leírására. Ebből létrehoz egy C programot, amely Lex egy karakterláncot, és létrehozza a kívánt kimenetet.
döntésem
úgy döntöttem, hogy egyelőre megtartom az általam írt lexert. Végül nem láttam a Flex használatának jelentős előnyeit, legalábbis nem elég ahhoz, hogy igazolja a függőség hozzáadását és az építési folyamat bonyolítását.
a lexerem csak néhány száz sor hosszú, és ritkán okoz problémát. Gördülő saját lexer is ad nekem nagyobb rugalmasságot, mint például a képesség, hogy adjunk egy operátor a nyelv szerkesztése nélkül több fájlt.
elemzés

a csővezeték második szakasza az elemző. Az elemző a tokenek listáját csomópontok fájává változtatja. Az ilyen típusú adatok tárolására használt fát absztrakt Szintaxisfának vagy AST-nek nevezik. Legalább Pinecone – ban az AST-nek nincs információja a típusokról vagy az azonosítókról. Ez egyszerűen strukturált tokenek.
elemző feladatok
az elemző hozzáadja a struktúrát a lexer által előállított tokenek rendezett listájához. A kétértelműségek megállításához az elemzőnek figyelembe kell vennie a zárójelet és a műveletek sorrendjét. Az operátorok egyszerű elemzése nem túl nehéz, de mivel több nyelvi konstrukció kerül hozzáadásra, az elemzés nagyon összetetté válhat.
bölény
ismét döntés született egy harmadik fél könyvtárának bevonásával. Az uralkodó elemző könyvtár a bölény. A Bison úgy működik, mint a Flex. Egyéni formátumban ír egy fájlt, amely tárolja a nyelvtani információkat, majd a Bison ezt használja egy C program létrehozására, amely elvégzi az elemzést. Nem a bölényt választottam.
miért jobb az egyéni
a lexerrel a saját kódom használatának döntése meglehetősen nyilvánvaló volt. A lexer olyan triviális program, hogy nem írtam a sajátomat, majdnem olyan butaságnak éreztem magam, mint nem írtam a saját ‘bal-padomat’.
az elemzővel ez más kérdés. A Pinecone elemzőm jelenleg 750 sor hosszú, és hármat írtam, mert az első kettő szemét volt.
eredetileg számos okból hoztam meg a döntésemet, és bár nem ment teljesen zökkenőmentesen, a legtöbbjük igaz. A legfontosabbak a következők:
- minimalizálja a kontextusváltást a munkafolyamatban: a kontextusváltás a C++ és a Pinecone között elég rossz anélkül, hogy bedobná a Bison nyelvtanát nyelvtan
- tartsa egyszerű: minden alkalommal, amikor a nyelvtan megváltozik, a Bison-t a build előtt kell futtatni. Ez automatizálható, de fájdalmassá válik az építési rendszerek közötti váltáskor.
- szeretek hűvös szart építeni: nem azért csináltam Pinecone-t, mert azt hittem, hogy könnyű lesz, miért delegálnék egy központi szerepet, amikor magam is meg tudom csinálni? Lehet, hogy az egyéni elemző nem triviális, de teljesen megvalósítható.
kezdetben nem voltam teljesen biztos abban, hogy életképes úton haladok-e, de bizalmat kaptam attól, amit Walter Bright (a C++ korai verziójának fejlesztője és a D nyelv készítője) mondott a témában:
” kissé ellentmondásosabb, nem zavarnám az időt a lexer vagy az elemző generátorokkal és más úgynevezett “fordító fordítókkal.”Csak időpocsékolás. A lexer és az elemző írása a fordító írásának apró százaléka. A generátor használata körülbelül annyi időt vesz igénybe, mint egy kézzel történő írás, és feleségül veszi a generátort (ami számít, ha a fordítót új platformra portolja). A generátoroknak pedig az a szerencsétlen hírneve is van, hogy pocsék hibaüzeneteket bocsátanak ki.”
Action Tree
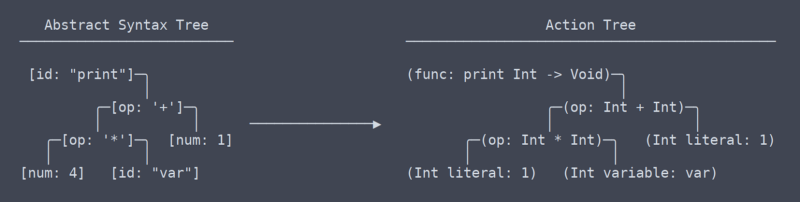
most elhagytuk a közös, univerzális kifejezések területét, vagy legalábbis nem tudom mi a feltételek már. Megértésem szerint az, amit ‘akciófának’ nevezek, leginkább az LLVM IR-jéhez hasonlít (köztes reprezentáció).
van egy finom, de nagyon jelentős különbség az akciófa és az absztrakt szintaxisfa között. Eltartott egy ideig, amíg rájöttem, hogy még különbséget kell tenni közöttük (ami hozzájárult az elemző átírásának szükségességéhez).
Akciófa vs AST
egyszerűen fogalmazva, az akciófa az AST kontextussal. Ez a kontextus olyan információ, mint például, hogy milyen típusú függvény tér vissza, vagy hogy két hely, ahol egy változót használnak, valójában ugyanazt a változót használják. Mivel ki kell találnia és emlékeznie kell erre a kontextusra, a műveletfát létrehozó kódnak sok névtér-Keresési táblára és más thingamabobra van szüksége.
az Akciófa futtatása
Miután megvan az akciófa, a kód futtatása egyszerű. Minden műveletcsomópontnak van egy ‘execute’ függvénye, amely valamilyen bemenetet vesz igénybe, bármit megtesz, amit a műveletnek meg kell tennie (beleértve a sub action meghívását is), és visszaadja a művelet kimenetét. Ez a tolmács akcióban.
fordítási lehetőségek
“de várj!”Hallom, azt mondod,” Nem Pinecone kellene által összeállított?”Igen, az. De a fordítás nehezebb, mint a tolmácsolás. Van néhány lehetséges megközelítés.
készítsd el a saját Fordítómat
Ez először jó ötletnek tűnt számomra. Imádok magam csinálni dolgokat, és már alig várom, hogy jó legyen az összeszerelés.
sajnos a hordozható fordító írása nem olyan egyszerű, mint néhány gépi kód írása az egyes nyelvi elemekhez. Az architektúrák és az operációs rendszerek száma miatt nem praktikus, hogy bárki írjon egy cross platform fordító háttérprogramot.
még a Swift, A Rust és a Clang mögött álló csapatok sem akarnak egyedül bajlódni ezzel az egésszel, ezért ehelyett mindannyian…
LLVM
az LLVM fordító eszközök gyűjteménye. Ez alapvetően egy könyvtár, amely viszont a nyelv egy lefordított futtatható bináris. Tökéletes választásnak tűnt, így rögtön beugrottam. Sajnos nem néztem meg, milyen mély a víz, és azonnal megfulladtam.
LLVM, bár nem assembly nyelv kemény, gigantikus komplex könyvtár nehéz. Nem lehetetlen használni, és jó oktatóanyagaik vannak, de rájöttem, hogy némi gyakorlatot kell szereznem, mielőtt készen állnék egy Pinecone fordító teljes megvalósítására.
Transzpiling
valamilyen összeállított Pinecone-t akartam, és gyorsan akartam, ezért egy olyan módszerhez fordultam, amelyről tudtam, hogy képes vagyok dolgozni: transpiling.
írtam egy Pinecone-t a C++ transpiler-hez, és hozzáadtam azt a képességet, hogy automatikusan lefordítsam a kimeneti forrást a GCC-vel. Ez jelenleg működik szinte minden Pinecone programok(bár van néhány él esetben, hogy megtörje). Ez nem különösebben hordozható vagy skálázható megoldás, de egyelőre működik.
jövő
feltételezve, hogy folytatom a Pinecone fejlesztését, előbb-utóbb megkapja az LLVM fordítási támogatását. Gyanítom, nem mater mennyit dolgozom rajta, a transzpiler soha nem lesz teljesen stabil, és az előnyeit LLVM számos. Csak az a kérdés, hogy mikor van időm néhány mintaprojektet készíteni az LLVM-ben, és megérteni.
addig a tolmács kiválóan alkalmas triviális programokra, a C++ transzpiling pedig a legtöbb olyan dologra működik, amely nagyobb teljesítményt igényel.
következtetés
remélem, kicsit kevésbé titokzatossá tettem a programozási nyelveket az Ön számára. Ha azt szeretnénk, hogy egy magad, én nagyon ajánlom. Van egy csomó végrehajtási részleteket kitalálni, de a vázlat itt kell lennie ahhoz, hogy neked megy.
itt van a magas szintű tanácsom az induláshoz (ne feledje, nem igazán tudom, mit csinálok, ezért vegye be egy szem sóval):
- ha kétségei vannak, értelmezze. Az értelmezett nyelvek általában könnyebben tervezhetők, építhetők és tanulhatók. Nem akadályozlak meg abban, hogy összeállíts egy összeállítást, ha tudod, hogy ezt akarod csinálni, de ha a kerítésen állsz, értelmeznék.
- amikor lexerekről és elemzőkről van szó, csinálj, amit akarsz. Vannak érvényes érvek a saját írása mellett és ellen. Végül, ha átgondolja a tervét, és mindent ésszerű módon hajt végre, az nem igazán számít.
- tanulj a csővezetékből, amivel végül végeztem. Sok próbálkozás és hiba történt a csővezeték tervezésében. Megpróbáltam kiküszöbölni az ASTs-t, az ASTs-t, amely cselekvési fákká változik a helyén, és más szörnyű ötleteket. Ez a csővezeték működik, ezért ne változtassa meg, hacsak nincs igazán jó ötlete.
- Ha nincs ideje vagy motivációja egy összetett általános célú nyelv megvalósítására, próbáljon meg egy ezoterikus nyelvet, például a Brainfuck-ot megvalósítani. Ezek a tolmácsok akár néhány száz sor is lehetnek.
nagyon kevés sajnálom, amikor a Pinecone fejlesztéséről van szó. Számos rossz döntést hoztam az út mentén, de az ilyen hibák által érintett kód nagy részét átírtam.
jelenleg a Pinecone elég jó állapotban van ahhoz, hogy jól működjön és könnyen javítható legyen. A Pinecone írása rendkívül oktató és élvezetes élmény volt számomra, és még csak most kezdődik.