Utoljára frissítve: február 17, 2021
a gépi tanulás szempontjából az előrejelzés egyetlen pont, amely elrejti az előrejelzés bizonytalanságát.
az előrejelzési intervallumok lehetővé teszik a bizonytalanság számszerűsítését és kommunikálását egy előrejelzésben. Ezek különböznek a konfidencia intervallumoktól, amelyek ehelyett egy populációs paraméter bizonytalanságának számszerűsítésére törekednek, például átlag vagy szórás. Az előrejelzési intervallumok egyetlen konkrét eredmény bizonytalanságát írják le.
ebben az oktatóanyagban felfedezheti az előrejelzési intervallumot, és hogyan kell kiszámítani egy egyszerű lineáris regressziós modellhez.
a bemutató befejezése után tudni fogja:
- hogy egy előrejelzési intervallum számszerűsíti az egypontos előrejelzés bizonytalanságát.
- hogy az előrejelzési intervallumok analitikusan becsülhetők egyszerű modellek esetén, de nagyobb kihívást jelentenek a nemlineáris gépi tanulási modellek esetében.
- hogyan lehet kiszámítani az előrejelzési intervallumot egy egyszerű lineáris regressziós modellhez.
indítsa el a projektet az új könyvemmel statisztika a gépi tanuláshoz, beleértve a lépésenkénti oktatóanyagokat és a Python forráskód fájlokat az összes példához.
kezdjük.
- Frissítve Június/2019: Korrigált szignifikancia szint a szórások töredékeként.
- Frissítve április/2020: rögzített elírás az előrejelzési intervallum diagramjában.

előrejelzési intervallumok a gépi tanuláshoz
fotó: Jim Bendon, néhány jog fenntartva.
bemutató Áttekintés
Ez a bemutató 5 részre oszlik; ezek:
- mi a baj egy Pontbecsléssel?
- mi az a predikciós intervallum?
- Hogyan számoljuk ki a predikciós intervallum
- predikciós intervallum lineáris regresszió
- dolgozott példa
segítségre van szüksége a statisztikák Gépi tanulás?
vegye ki az ingyenes 7 napos e-mail gyorstalpaló tanfolyamomat (mintakóddal).
kattintson a regisztrációhoz, és kapjon egy ingyenes PDF Ebook verziót a tanfolyamról.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict (X)
|
ahol yhat a betanított modell becsült eredménye vagy előrejelzése az adott bemeneti adatokra X.
Ez egy pont-előrejelzés.
definíció szerint becslés vagy közelítés, és tartalmaz némi bizonytalanságot.
a bizonytalanság a modell hibáiból és a bemeneti adatok zajából származik. A modell a bemeneti változók és a kimeneti változók közötti kapcsolat közelítése.
tekintettel a modell kiválasztására és hangolására használt folyamatra, ez lesz a legjobb közelítés a rendelkezésre álló információk alapján, de továbbra is hibákat okoz. A tartományból származó adatok természetesen elhomályosítják a bemeneti és kimeneti változók közötti mögöttes és ismeretlen kapcsolatot. Ez kihívást jelent a modell illesztéséhez, és kihívást jelent egy fit modell számára is, hogy előrejelzéseket készítsen.
e két fő hibaforrás miatt a prediktív modellből származó pont-előrejelzésük nem elegendő az előrejelzés valódi bizonytalanságának leírásához.
mi az a predikciós intervallum?
a predikciós intervallum az előrejelzés bizonytalanságának számszerűsítése.
valószínűségi felső és alsó határokat ad az eredményváltozó becsléséhez.
az egyetlen jövőbeli megfigyelés előrejelzési intervalluma egy olyan intervallum, amely meghatározott fokú megbízhatósággal tartalmaz egy eloszlásból véletlenszerűen kiválasztott jövőbeli megfigyelést.
— 27.oldal, statisztikai intervallumok: útmutató szakemberek és kutatók számára, 2017.
az előrejelzési intervallumokat leggyakrabban akkor használják, amikor előrejelzéseket vagy előrejelzéseket készítenek regressziós modellel, ahol egy mennyiséget jósolnak.
a predikciós intervallum bemutatására példa a következő:
az ” y “előrejelzésének adott” x “esetén 95% a valószínűsége annak, hogy az” A ” – ” b ” tartomány lefedi a valódi eredményt.
az előrejelzési intervallum körülveszi a modell által készített előrejelzést, és remélhetőleg lefedi a valódi eredmény tartományát.
az alábbi ábra segít vizuálisan megérteni az előrejelzés, az előrejelzési intervallum és a tényleges eredmény közötti kapcsolatot.
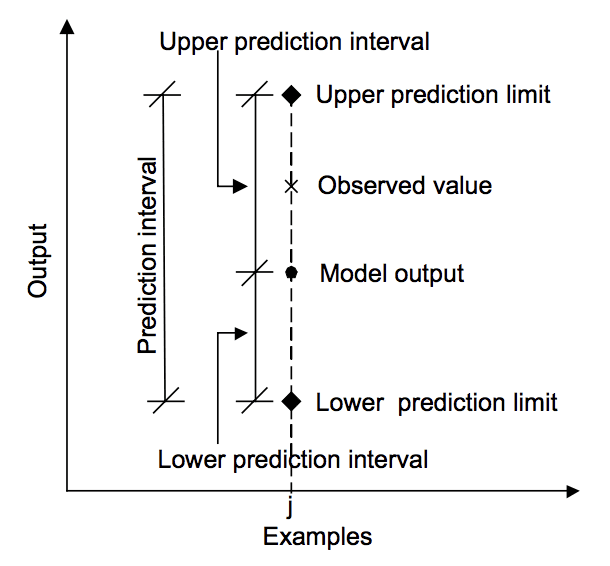
az előrejelzés, a tényleges érték és az előrejelzési intervallum közötti kapcsolat.
a “gépi tanulási megközelítések a modell kimenetének előrejelzési intervallumának becsléséhez”, 2006.
a predikciós intervallum eltér a konfidencia intervallumtól.
a konfidencia intervallum számszerűsíti a becsült populációs változó bizonytalanságát, például az átlagot vagy a szórást. Míg egy előrejelzési intervallum számszerűsíti a populációból becsült egyetlen megfigyelés bizonytalanságát.
a prediktív modellezésben a konfidencia intervallum felhasználható a modell becsült készségének bizonytalanságának számszerűsítésére, míg a előrejelzési intervallum felhasználható egyetlen előrejelzés bizonytalanságának számszerűsítésére.
a predikciós intervallum gyakran nagyobb, mint a konfidencia intervallum, mivel figyelembe kell vennie a konfidencia intervallumot és a megjósolt kimeneti változó varianciáját.
az előrejelzési intervallumok mindig szélesebbek lesznek , mint a konfidencia intervallumok, mert figyelembe veszik az e-vel kapcsolatos bizonytalanságot, az irreducibilis hibát.
— 103.oldal, Bevezetés a statisztikai tanulásba: alkalmazásokkal az R-ben, 2013.
az előrejelzési intervallum kiszámítása
az előrejelzési intervallum kiszámítása a modell becsült varianciájának és az eredményváltozó varianciájának valamilyen kombinációjaként történik.
az előrejelzési intervallumok könnyen leírhatók, de a gyakorlatban nehéz kiszámítani.
olyan egyszerű esetekben, mint a lineáris regresszió, közvetlenül megbecsülhetjük az előrejelzési intervallumot.
a nemlineáris regressziós algoritmusok, például a mesterséges neurális hálózatok esetében ez sokkal nagyobb kihívást jelent, és speciális technikák kiválasztását és végrehajtását igényli. Általános technikák, például a bootstrap újramintavételezési módszer használható, de számítási szempontból drága kiszámítani.
az “a neurális hálózat alapú előrejelzési intervallumok és az új előrelépések átfogó áttekintése” című cikk meglehetősen friss tanulmányt nyújt a nemlineáris modellek előrejelzési intervallumairól a neurális hálózatok összefüggésében. Az alábbi lista összefoglalja azokat a módszereket, amelyek felhasználhatók a nemlineáris gépi tanulási modellek előrejelzési bizonytalanságához:
- a Delta módszer, a nemlineáris regresszió területéről.
- a bayesi módszer, bayesi modellezés és statisztika.
- Az átlagos variancia becslési módszer, becsült statisztikák felhasználásával.
- a Bootstrap módszer, adatok újramintázásával és modellek együttesének fejlesztésével.
tudjuk, hogy a számítás a predikciós intervallum beton egy megmunkált példa a következő részben.
predikciós intervallum lineáris regresszióhoz
a lineáris regresszió olyan modell, amely leírja a bemenetek lineáris kombinációját a kimeneti változók kiszámításához.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
nem ismerjük a B0 és b1 együtthatók valós értékeit. Nem ismerjük a valós populációs paramétereket, például az átlagot és a szórást x vagy y. ezeket az elemeket meg kell becsülni, ami bizonytalanságot vezet be a modell használatába az előrejelzések készítése érdekében.
feltételezhetjük, hogy az X és y eloszlása, valamint a modell által tett előrejelzési hibák, az úgynevezett maradványok, Gauss-féle.
az yhat körüli előrejelzési intervallum a következőképpen számítható ki:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
a gyakorlatban nem ismerjük. Az előrejelzett szórás elfogulatlan becslését az alábbiak szerint számíthatjuk ki (a gépi tanulási megközelítésekből a modell kimenetének előrejelzési intervallumának becsléséhez):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
megmunkált példa
tegyük konkrétvá a lineáris regressziós előrejelzési intervallumok esetét egy megmunkált példával.
először határozzunk meg egy egyszerű kétváltozós adatkészletet, ahol a kimeneti változó (y) függ a bemeneti változótól (x) némi Gauss-zajjal.
az alábbi példa meghatározza az ehhez a példához használt adatkészletet.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
ezután létrejön az adatkészlet diagramja.
láthatjuk a változók közötti egyértelmű lineáris kapcsolatot a pontok terjedésével, kiemelve a kapcsolat zaját vagy véletlenszerű hibáját.
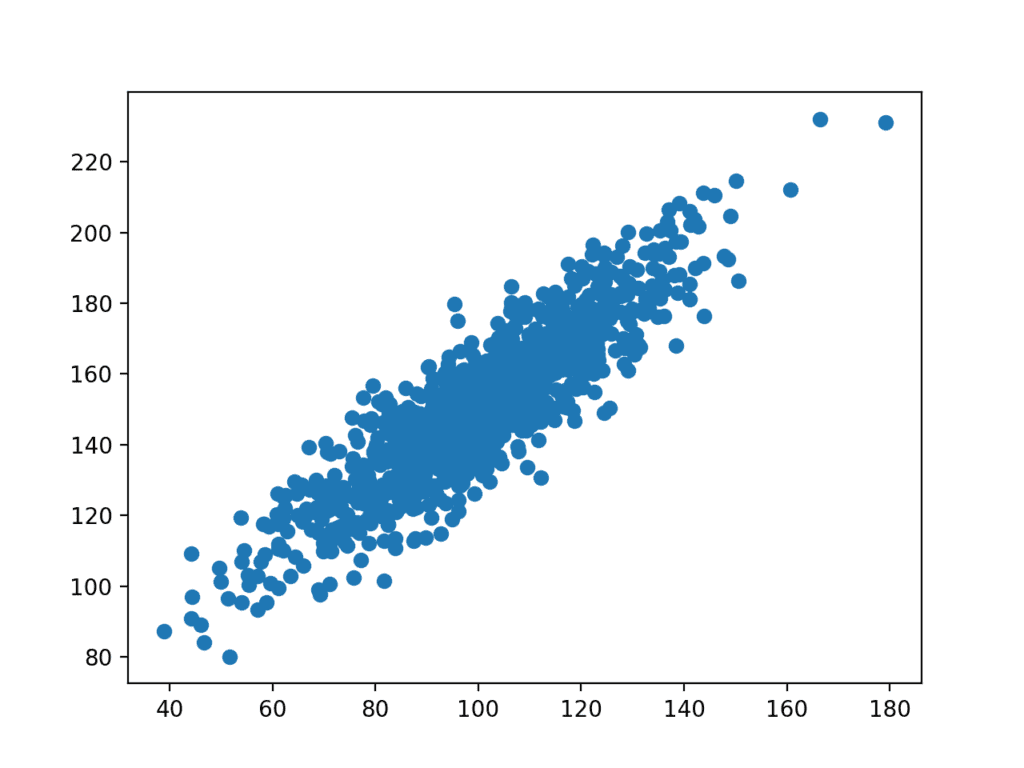
a kapcsolódó változók Szórásdiagramja
ezután kidolgozhatunk egy egyszerű lineáris regressziót, amely az X bemeneti változót figyelembe véve megjósolja az y változót. Használhatjuk a linregress () SciPy függvényt, hogy illeszkedjen a modellhez, és visszaadja a modell b0 és b1 együtthatóit.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# egyszerű nemlineáris regressziós modell
a numpy-tól.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‘b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
az együtthatókat ezután az adatkészlet bemeneteivel együtt használják előrejelzéshez. Az eredményül kapott bemenetek és az előre jelzett y-értékek egy sorként vannak ábrázolva az adatkészlet szórási diagramjának tetején.
világosan láthatjuk, hogy a modell megtanulta a mögöttes kapcsolatot az adatkészletben.
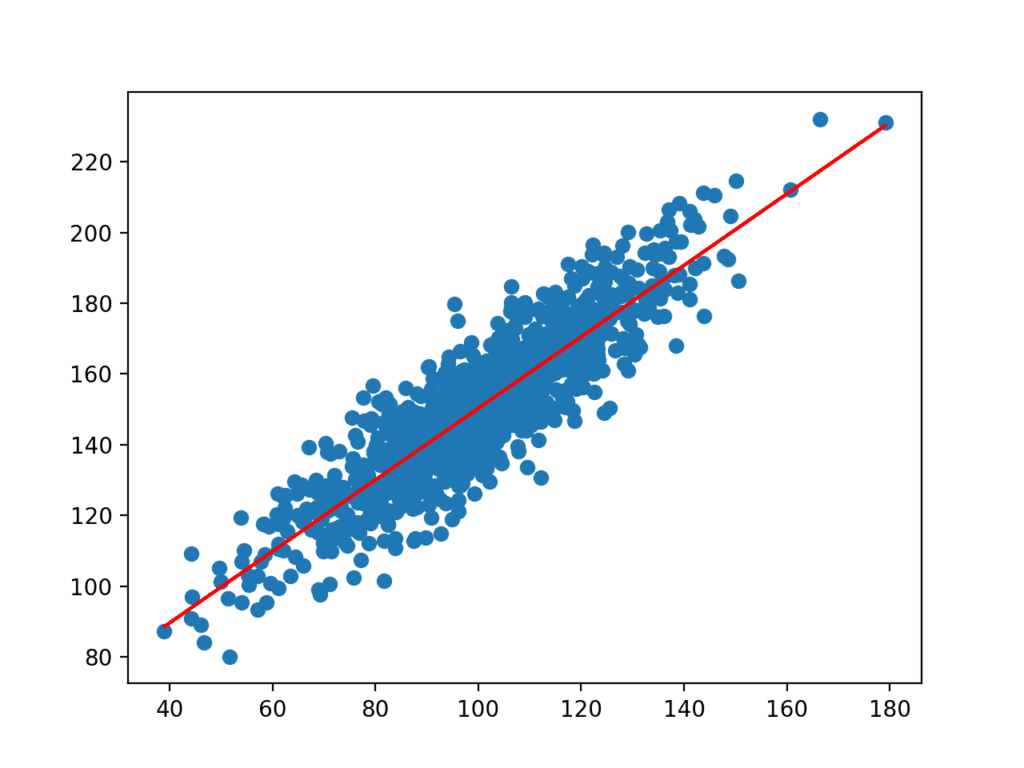
az adatkészlet szórási diagramja az egyszerű lineáris regressziós modellhez
készen állunk arra, hogy előrejelzést készítsünk az egyszerű lineáris regressziós modellünkkel, és adjunk hozzá egy előrejelzési intervallumot.
a modellhez illeszkedünk, mint korábban. Ezúttal egy mintát veszünk az adatkészletből az előrejelzési intervallum bemutatására. Az input segítségével előrejelzést készítünk, kiszámítjuk az előrejelzés intervallumát, és összehasonlítjuk az előrejelzést és az intervallumot az ismert várható értékkel.
először határozzuk meg a bemeneti, előrejelzési és várható értékeket.
|
1
2
3
|
x_in = x
y_out = y
yhat_out = yhat
|
ezután megbecsülhetjük a standard görbületet az előrejelzési irányban.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.statisztika import linregress
a matplotlib import pyplot
# seed véletlenszám-generátor
seed(1)
# készítse elő az adatokat
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# illessze be a nemlineáris regressziós modellt
B1, B0, r_value, p_value, std_err = linregress(x, y)
# Mark előrejelzések
yhat = B0 + B1 * x
# új bemenet, várható érték és előrejelzés meghatározása
x_in = x
y_out = y
yhat_out = yhat
# yhat StDev becslése
sum_errs = arraysum ((y – yhat)**2)
stdev = sqrt(1/(len (y)-2) * sum_errs)
# számítsa ki az előrejelzési intervallumot
intervallum = 1,96 * stdev
nyomtatás (‘előrejelzési intervallum: %.3f ‘ % intervallum)
alsó, felső = yhat_out-intervallum, yhat_out + intervallum
nyomtatás (‘95%% valószínűsége annak, hogy a valódi érték %között van.3f és %.3f ‘ % (alsó, felső))
nyomtatás(‘valódi érték: %.3f ‘ % y_out)
# plot adatkészlet és predikció intervallummal
pyplot.scatter (x, y)
pyplot.plot (x, yhat, Szín=’Piros’)
pyplot.errorbar (x_in, yhat_out, yerr=intervallum, Szín=’Fekete’, fmt=’o’)
pyplot.show ()
|
a példa futtatása becsüli az yhat szórást, majd kiszámítja az előrejelzési intervallumot.
a kiszámítás után az előrejelzési intervallum megjelenik a felhasználó számára az adott bemeneti változóhoz. Mivel kitaláltuk ezt a példát, ismerjük a valódi eredményt, amelyet szintén bemutatunk. Láthatjuk, hogy ebben az esetben a 95% – os előrejelzési intervallum lefedi a valódi várható értéket.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
létrehozunk egy ábrát is, amely a nyers adatkészletet szórási diagramként, az adatkészlet előrejelzéseit piros vonalként, az előrejelzési és előrejelzési intervallumot pedig fekete pontként, illetve vonalként mutatja.
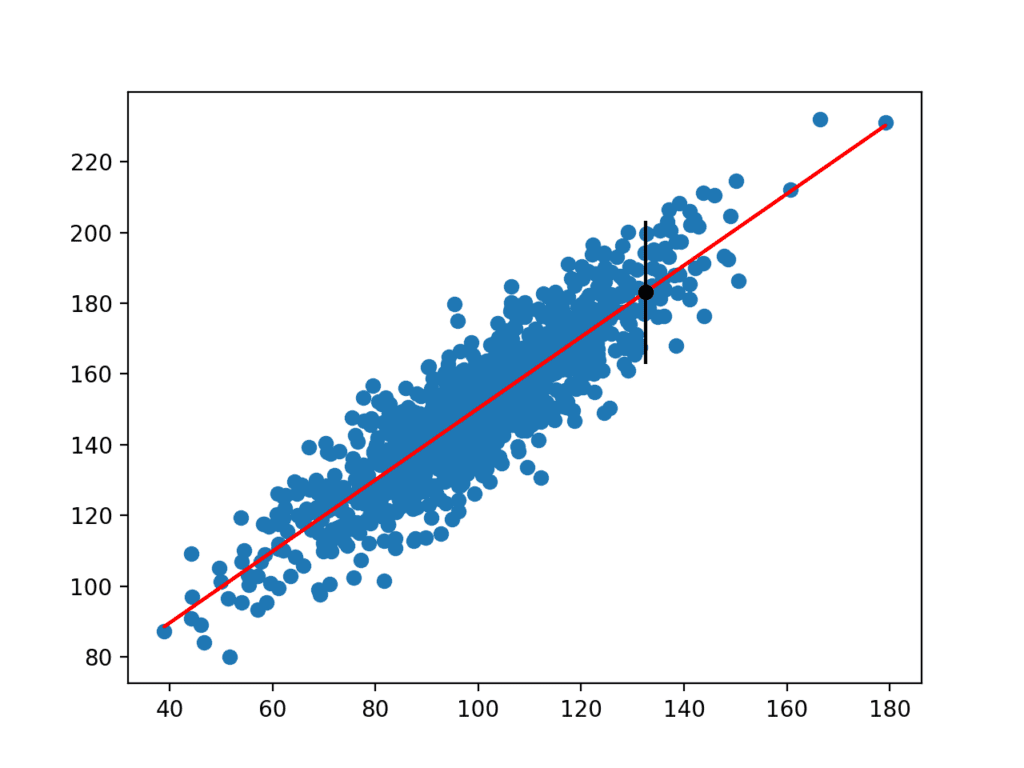
az adatkészlet szórási rajza lineáris modellel és előrejelzési intervallummal
kiterjesztések
Ez a szakasz felsorol néhány ötletet az oktatóanyag kiterjesztésére, amelyet érdemes felfedezni.
- foglalja össze a tolerancia, a bizalom és az előrejelzési intervallumok közötti különbséget.
- dolgozzon ki egy lineáris regressziós modellt egy szabványos gépi tanulási adatkészlethez, és számítsa ki az előrejelzési intervallumokat egy kis tesztkészlethez.
- részletesen írja le, hogyan működik egy nemlineáris előrejelzési intervallum módszer.
ha felfedezed ezeket a kiterjesztéseket, szeretném tudni.
további olvasmányok
Ez a szakasz további forrásokat biztosít a témában, ha mélyebbre szeretne menni.
Hozzászólások
- hogyan jelentsük az osztályozó teljesítményét konfidencia intervallumokkal
- Hogyan számítsuk ki a Bootstrap konfidencia intervallumokat a gépi tanulási eredményekhez Pythonban
- értsük meg az idősorok előrejelzési bizonytalanságát a konfidencia intervallumok használatával Pythonnal
- becsüljük meg a sztochasztikus gépi tanulási algoritmusok kísérleti ismétléseinek számát
Könyvek
- az új statisztikák megértése: Hatásméretek, konfidencia intervallumok és metaanalízis, 2017.
- statisztikai intervallumok: útmutató szakemberek és kutatók számára, 2017.
- Bevezetés a statisztikai tanulásba: alkalmazásokkal az R-ben, 2013.
- Bevezetés az új statisztikákba: becslés, nyílt tudomány, és azon túl, 2016.
- előrejelzés: elvek és gyakorlat, 2013.
Papers
- néhány hibabecslés összehasonlítása a neurális hálózati modellekhez, 1995.
- gépi tanulási megközelítések a modell kimenetének előrejelzési intervallumának becsléséhez, 2006.
- a neurális hálózat alapú előrejelzési intervallumok és az új előrelépések átfogó áttekintése, 2010.
API
- scipy.statisztika.linregress () API
- matplotlib.pyplot.scatter () API
- matplotlib.pyplot.errorbar() API
cikkek
- predikciós intervallum a Wikipédián
- Bootstrap predikciós intervallum Keresztvalidált
összefoglaló
ebben a bemutatóban felfedezted a predikciós intervallumot, és hogyan kell kiszámítani egy egyszerű lineáris regressziós modellhez.
konkrétan megtanultad:
- hogy egy előrejelzési intervallum számszerűsíti az egypontos előrejelzés bizonytalanságát.
- hogy az előrejelzési intervallumok analitikusan becsülhetők egyszerű modellekre, de nagyobb kihívást jelentenek a nemlineáris gépi tanulási modellek esetében.
- hogyan lehet kiszámítani az előrejelzési intervallumot egy egyszerű lineáris regressziós modellhez.
kérdése van?
tegye fel kérdéseit az alábbi megjegyzésekben, és mindent megteszek, hogy válaszoljak.
kap egy fogantyú statisztikák Gépi tanulás!

dolgozzon ki egy működő statisztikai megértést
…írásával sorokat kódot python
fedezze fel, hogy az én új Ebook:
statisztikai módszerek Gépi tanulás
Ez biztosítja önálló tanulás oktatóanyagok témákban, mint például:
hipotézis tesztek, korreláció, nem paraméteres statisztika, Újramintavételezés, és még sok más…
fedezze fel, hogyan lehet az adatokat tudássá alakítani
hagyja ki az akadémikusokat. Csak Eredmények.
lásd, mi van benne