Szia és üdvözöljük a hosszú rövid távú memória illusztrált útmutatójában (LSTM) és a kapuzott visszatérő egységek (Gru). Michael vagyok, gépi tanulási mérnök az AI hangsegéd térben.
ebben a bejegyzésben az LSTM és a GRU mögött rejlő intuícióval kezdjük. aztán elmagyarázom azokat a belső mechanizmusokat, amelyek lehetővé teszik az LSTM és a GRU számára, hogy ilyen jól teljesítsenek. Ha meg akarja érteni, mi történik a motorháztető alatt e két hálózat esetében, akkor ez a bejegyzés az Ön számára készült.
a bejegyzés videó verzióját a youtube-on is megnézheti, ha úgy tetszik.
a visszatérő neurális hálózatok rövid távú memóriától szenvednek. Ha egy szekvencia elég hosszú, akkor nehezen tudják továbbítani az információkat a korábbi időlépésekről a későbbiekre. Tehát, ha egy bekezdést próbál feldolgozni jóslatok készítéséhez, az RNN-ek a kezdetektől fogva fontos információkat hagyhatnak ki.
a hátsó terjedés során a visszatérő neurális hálózatok szenvednek az eltűnő gradiens problémától. A színátmenetek olyan értékek, amelyeket a neurális hálózatok súlyainak frissítésére használnak. Az eltűnő gradiens probléma az, amikor a gradiens zsugorodik, amikor visszaáll az időben. Ha egy gradiens érték rendkívül kicsi lesz, akkor nem járul hozzá túl sok tanuláshoz.
tehát a visszatérő neurális hálózatokban a kis gradiens frissítést kapó rétegek leállítják a tanulást. Ezek általában a korábbi rétegek. Tehát mivel ezek a rétegek nem tanulnak, az RNN-ek elfelejthetik azt, amit hosszabb szekvenciákban láttak, így rövid távú memóriájuk van. Ha többet szeretne tudni a visszatérő neurális hálózatok mechanikájáról általában, itt olvashatja el előző bejegyzésemet.
LSTM-ek és GRU-k mint megoldás
LSTM-ek és GRU-k a rövid távú memória megoldásaként jöttek létre. Belső mechanizmusaik vannak, úgynevezett kapuk, amelyek szabályozhatják az információáramlást.

ezek a kapuk megtudhatják, hogy egy sorozatban mely adatokat kell megtartani vagy eldobni. Ezzel releváns információkat továbbíthat a szekvenciák hosszú láncán, hogy előrejelzéseket készítsen. Ezzel a két hálózattal szinte az összes korszerű, ismétlődő neurális hálózaton alapuló eredmény érhető el. Az LSTM-ek és a GRU-k megtalálhatók a beszédfelismerésben, a beszédszintézisben és a szöveggenerálásban. Akár azt is használja őket, hogy létrehoz feliratok videók.
Ok, tehát a bejegyzés végére alaposan meg kell értened, hogy az LSTM és a GRU miért jó a hosszú szekvenciák feldolgozásában. Ezt intuitív magyarázatokkal és illusztrációkkal fogom megközelíteni, és a lehető legtöbb matematikát kerülöm.
intuíció
Ok, kezdjük egy gondolatkísérlettel. Tegyük fel, hogy online véleményeket néz, hogy meghatározza, meg akarja-e vásárolni az élet gabonapelyhet (ne kérdezd, miért). Először olvassa el a felülvizsgálatot, majd határozza meg, hogy valaki jónak vagy rossznak gondolta-e.

amikor elolvassa a felülvizsgálatot, az agy tudat alatt csak a fontos kulcsszavakra emlékszik. Olyan szavakat vesz fel, mint a” csodálatos “és a”tökéletesen kiegyensúlyozott reggeli”. Nem sokat érdekel az olyan szavak, mint “ez”, “adott”, “minden”, “kellene” stb. Ha egy barátja másnap megkérdezi, hogy mit mondott a felülvizsgálat, akkor valószínűleg nem emlékszik rá szóról szóra. Lehet, hogy emlékszik a főbb pontokat, bár, mint a”biztosan vásárol újra”. Ha olyan vagy, mint én, a többi szó elhalványul az emlékezetből.

és ez lényegében az, amit egy LSTM vagy Gru csinál. Megtanulhatja, hogy csak releváns információkat tartson meg az előrejelzések készítéséhez, és elfelejtse a nem releváns adatokat. Ebben az esetben az emlékezett szavak arra késztették, hogy megítélje, hogy jó.
A visszatérő neurális hálózatok áttekintése
annak megértéséhez, hogy az LSTM vagy a GRU hogyan éri el ezt, nézzük át a visszatérő neurális hálózatot. Az RNN így működik; az első szavak géppel olvasható vektorokká alakulnak át. Ezután az RNN egyenként feldolgozza a vektorok sorrendjét.
feldolgozás közben az előző rejtett állapotot átadja a szekvencia következő lépésének. A rejtett állapot a neurális hálózatok memóriájaként működik. Információkat tartalmaz a hálózat által korábban látott korábbi adatokról.
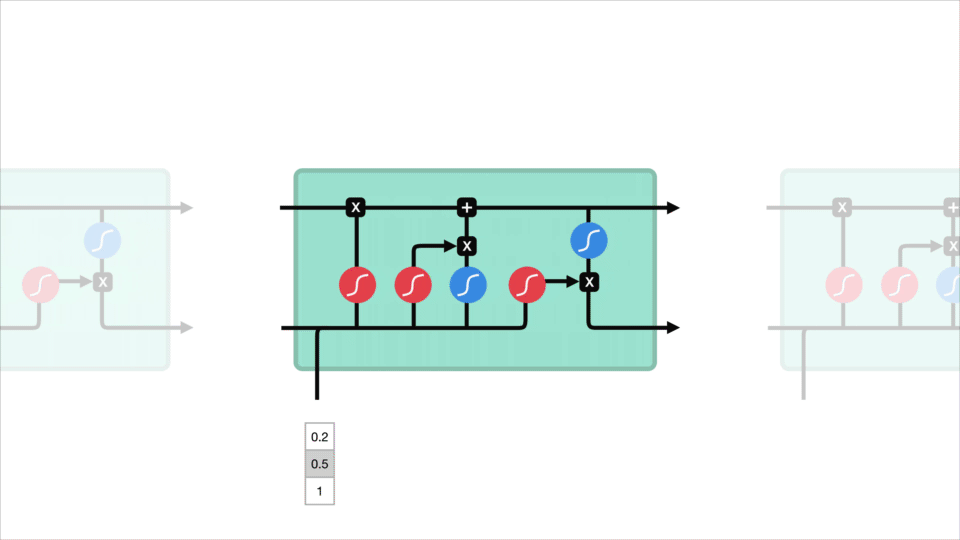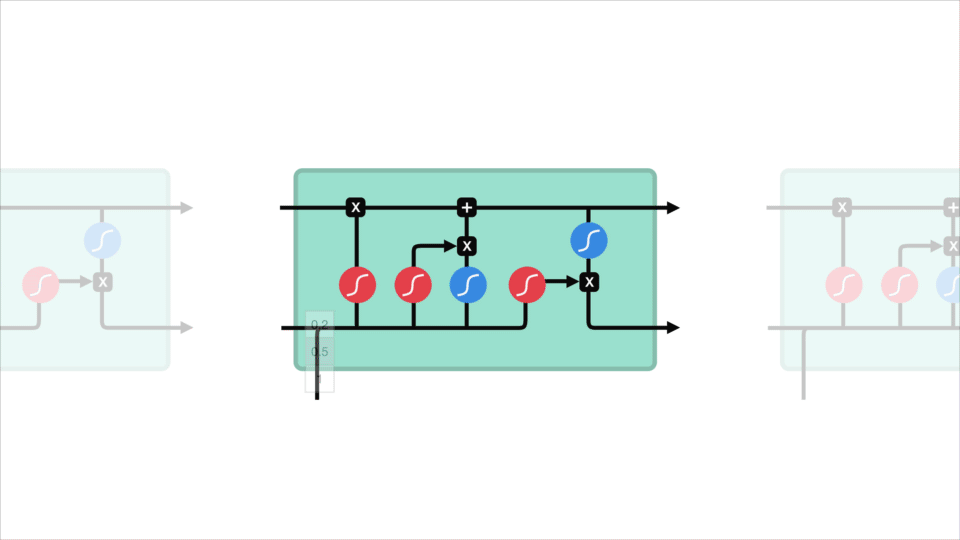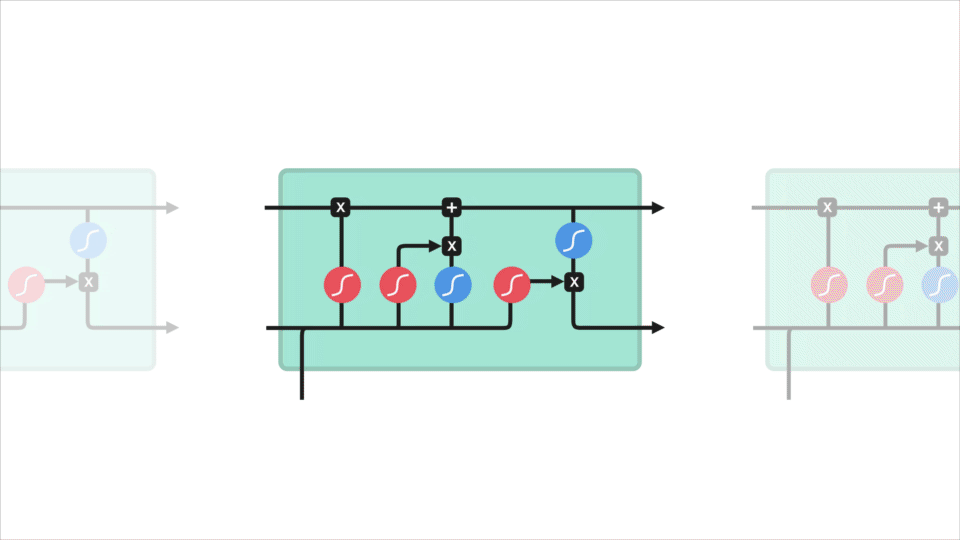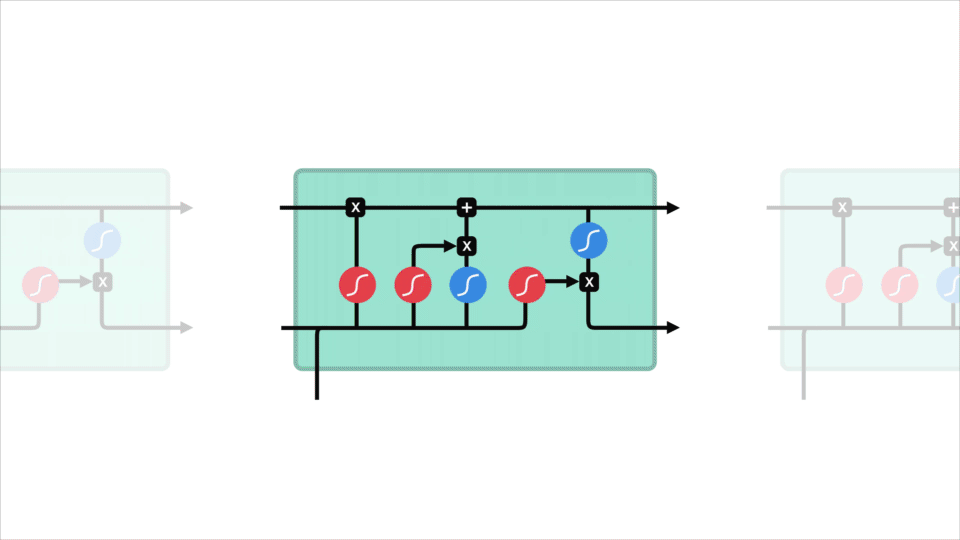
nézzük meg az RNN celláját, hogy lássuk, hogyan számítaná ki a rejtett állapotot. Először a bemenet és az előző Rejtett állapot kombinálódik, hogy vektort képezzen. Ez a vektor most információkat tartalmaz az aktuális bemenetről és a korábbi bemenetekről. A vektor A tanh aktiváláson megy keresztül, a kimenet pedig az új rejtett állapot, vagy a hálózat memóriája.
tanh aktiválás
A Tanh aktiválás segít szabályozni a hálózaton keresztül áramló értékeket. A tanh függvény az értékeket mindig -1 és 1 közé szorítja.
amikor a vektorok egy neurális hálózaton keresztül áramlanak, számos átalakuláson megy keresztül a különböző matematikai műveletek miatt. Képzeljünk el tehát egy olyan értéket, amelyet továbbra is megszorozunk mondjuk 3-mal. Láthatjuk, hogy egyes értékek felrobbanhatnak és csillagászattá válhatnak, ami más értékeket jelentéktelennek tűnik.