mi a megerősítő tanulás?
a megerősítő tanulás olyan gépi tanulási módszer, amely arra vonatkozik, hogy a szoftverügynököknek hogyan kell cselekedniük egy környezetben. A megerősítő tanulás a mély tanulási módszer része, amely segít maximalizálni a kumulatív jutalom egy részét.
Ez a neurális hálózati tanulási módszer segít megtanulni, hogyan lehet elérni egy összetett célt, vagy maximalizálni egy adott dimenziót sok lépésben.
a megerősítő tanulás oktatóanyagában megtudhatja:
- mi a megerősítő tanulás?
- a mély megerősítési tanulási módszerben használt fontos kifejezések
- hogyan működik a megerősítési tanulás?
- megerősítési tanulási algoritmusok
- a megerősítési tanulás jellemzői
- a megerősítési tanulás típusai
- a megerősítési tanulás tanulási modelljei
- megerősítési tanulás vs. felügyelt tanulás
- a megerősítési tanulás alkalmazásai
- miért érdemes megerősítő tanulást használni?
- mikor ne használja a megerősítő tanulást?
- kihívások megerősítés tanulás
fontos használt kifejezések mély megerősítés tanulási módszer
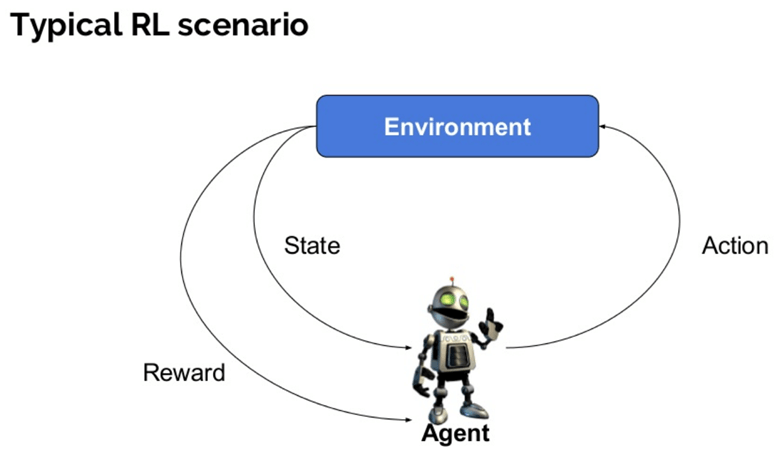
Íme néhány fontos használt kifejezések megerősítése AI:
- ügynök: ez egy feltételezett entitás, amely műveleteket hajt végre egy környezetben, hogy valamilyen jutalmat szerezzen.
- környezet (e): olyan forgatókönyv, amellyel egy ügynöknek szembe kell néznie.
- jutalom (R): Az ügynöknek adott azonnali visszatérés, amikor konkrét műveletet vagy feladatot hajt végre.
- állapot (ok): állapot a környezet által visszaadott jelenlegi helyzetre utal.
- politika (?): Ez egy olyan stratégia, amelyet az ügynök alkalmaz a következő művelet eldöntésére az aktuális állapot alapján.
- érték (V): hosszú távú hozam várható kedvezménnyel, a rövid távú jutalomhoz képest.
- Értékfüggvény: meghatározza egy állapot értékét, amely a jutalom teljes összege. Ez egy ügynök, amelyet az adott államtól kell elvárni.
- a környezet modellje: ez utánozza a környezet viselkedését. Segít abban, hogy következtetéseket vonjon le, és meghatározza, hogyan fog viselkedni a környezet.
- modell alapú módszerek: ez egy módszer a megerősítési tanulási problémák megoldására, amelyek modellalapú módszereket használnak.
- Q érték vagy műveleti érték (Q): A Q érték nagyon hasonló az értékhez. Az egyetlen különbség a kettő között az, hogy egy további paramétert vesz igénybe aktuális műveletként.
hogyan működik a megerősítő tanulás?
lássunk néhány egyszerű példát, amely segít bemutatni a megerősítő tanulási mechanizmust.
fontolja meg az új trükkök tanításának forgatókönyvét macskájának
- mivel macska nem ért angolul vagy más emberi nyelven, nem tudjuk közvetlenül megmondani neki, mit tegyen. Ehelyett más stratégiát követünk.
- utánozunk egy helyzetet, és a macska sokféle módon próbál reagálni. Ha a macska válasza a kívánt módon, akkor halat adunk neki.
- most, amikor a macska ki van téve ugyanannak a helyzetnek, a macska hasonló műveletet hajt végre, még lelkesebben elvárva, hogy több jutalmat(ételt) kapjon.
- ez olyan, mintha megtanulnánk, hogy a macska a “mit kell tennie” pozitív tapasztalatokból származik.
- ugyanakkor a macska azt is megtanulja, hogy mit ne tegyen, ha negatív tapasztalatokkal szembesül.
A példa magyarázata:
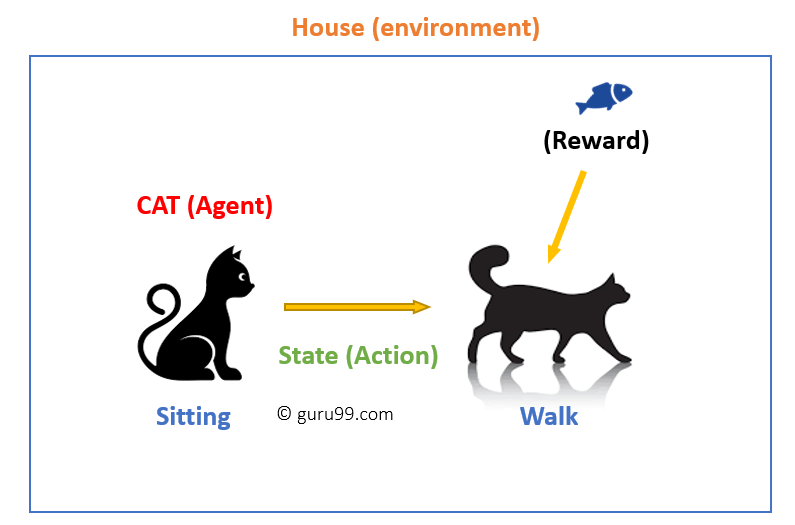
ebben az esetben
- macskája a környezetnek kitett szer. Ebben az esetben ez a ház. Egy példa az állam lehet a macska ül, és egy adott szót a macska járni.
- ügynökünk úgy reagál, hogy egy “állapot” – ból egy másik “állapotba való átmenetet hajt végre.”
- például a macskád üléstől járásig megy.
- az ágens reakciója cselekvés, a politika pedig egy olyan művelet kiválasztásának módszere, amely egy állapotot ad a jobb eredmények elvárására.
- az átmenet után jutalmat vagy büntetést kaphatnak cserébe.
megerősítési tanulási algoritmusok
három megközelítés létezik a megerősítési tanulási algoritmus megvalósítására.
értékalapú:
értékalapú megerősítési tanulási módszernél meg kell próbálnia maximalizálni egy értékfüggvényt V(s). Ebben a módszerben az ügynök a jelenlegi államok hosszú távú visszatérését várja a politika alatt ?.
Policy-based:
egy policy-based RL metódusban megpróbálsz olyan politikát kidolgozni, hogy a minden államban végrehajtott művelet segít a maximális jutalom megszerzésében a jövőben.
a politikaalapú módszerek két típusa:
- determinisztikus: bármely állam esetében ugyanazt a műveletet hozza létre a politika ?.
- sztochasztikus: minden műveletnek van egy bizonyos valószínűsége, amelyet a következő egyenlet határoz meg.Sztochasztikus politika:
n{a\s) = P\A, = a\S, =S]
modell alapú:
ebben a megerősítő tanulási módszerben minden környezethez létre kell hoznia egy virtuális modellt. Az ügynök megtanulja végrehajtani az adott környezetben.
A megerősítő tanulás jellemzői
itt vannak a megerősítő tanulás fontos jellemzői
- nincs felügyelő, csak egy valós szám vagy jutalom jel
- szekvenciális döntéshozatal
- az idő döntő szerepet játszik a megerősítési problémákban
- a visszajelzés mindig késik, nem pedig azonnali
- Az ügynök műveletei meghatározzák a kapott későbbi adatokat
A megerősítő tanulás típusai
kétféle megerősítési tanulási módszer:
pozitív:
Ez egy olyan esemény, amely egy adott viselkedés miatt következik be. Növeli a viselkedés erősségét és gyakoriságát, és pozitívan befolyásolja az ügynök által hozott intézkedéseket.
Ez a fajta megerősítés segít maximalizálni a teljesítményt és fenntartani a változást hosszabb ideig. A túl sok megerősítés azonban az állapot túlzott optimalizálásához vezethet, ami befolyásolhatja az eredményeket.
negatív:
a negatív megerősítés a viselkedés megerősítése, amely egy negatív állapot miatt következik be, amelyet meg kellett volna állítani vagy elkerülni. Segít meghatározni a teljesítmény minimális állását. Ennek a módszernek az a hátránya, hogy elegendő ahhoz, hogy megfeleljen a minimális viselkedésnek.
A megerősítés tanulási modelljei
a megerősítéses tanulásban két fontos tanulási modell létezik:
- Markov döntési folyamat
- Q tanulás
Markov döntési folyamat
a következő paramétereket használjuk a megoldás eléréséhez:
- műveletek halmaza-a
- állapotok halmaza-s
- jutalom-R
- politika-n
- érték-V
a matematikai megközelítés a megoldás feltérképezéséhez a megerősítési tanulásban a recon mint Markov döntési folyamat vagy (MDP).
Q-Learning
A Q learning egy értékalapú információszolgáltatási módszer annak érdekében, hogy az ügynöknek milyen lépéseket kell tennie.
értsük meg ezt a módszert a következő példával:
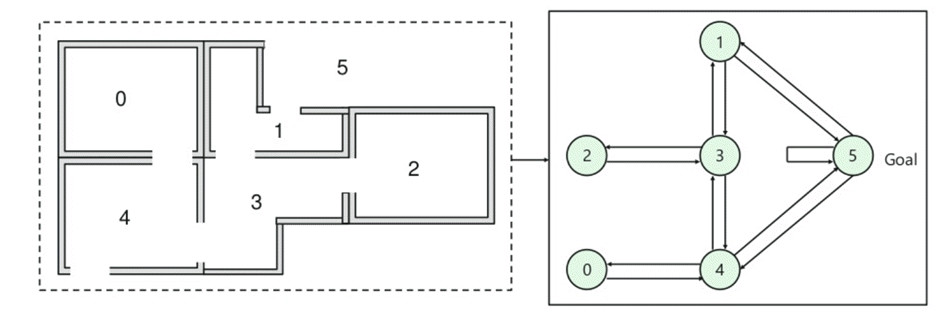
- egy épületben öt szoba van, amelyeket ajtók kötnek össze.
- minden szoba 0-tól 4-ig van számozva
- az épület külső része lehet egy nagy külső terület (5)
- az 1-es és a 4-es ajtók az 5-ös szobából vezetnek be az épületbe
ezután minden ajtóhoz hozzá kell rendelni egy jutalom értéket:
- ajtók, amelyek közvetlenül a cél van egy jutalom 100
- ajtók, amelyek nem közvetlenül kapcsolódik a cél szoba ad nulla jutalom
- mivel az ajtók kétirányú, és két nyíl van rendelve minden szobában
- minden nyíl a fenti képen tartalmaz egy azonnali jutalom értéke
magyarázat:
Ezen a képen, akkor megtekintheti, hogy a szoba egy állam
az ügynök egyik szobából a másikba történő mozgása egy műveletet jelent
az alábbi képen egy állapotot csomópontként írnak le, míg a nyilak a műveletet mutatják.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Felügyelt tanulás
| paraméterek | megerősítés tanulás | felügyelt tanulás |
| döntési stílus | megerősítés tanulás segít, hogy a döntéseket egymás után. | ebben a módszerben döntés születik az elején megadott bemenetről. |
| működik | működik kölcsönhatásban áll a környezettel. a | példákon vagy adott mintaadatokon működik. |
| függés a döntéstől | az RL módszerben a tanulási döntés függ. Ezért címkéket kell adnia az összes függő döntéshez. | felügyelt tanulás a döntéseket, amelyek függetlenek egymástól, így címkék kapnak minden döntést. |
| a legmegfelelőbb | támogatja és jobban működik az AI-ben, ahol az emberi interakció elterjedt. | leginkább interaktív szoftverrendszerrel vagy alkalmazásokkal működik. |
| példa | sakkjáték | Objektumfelismerés |
A megerősítő tanulás alkalmazásai
itt találhatók a megerősítő tanulás alkalmazásai:
- robotika ipari automatizáláshoz.
- üzleti stratégia tervezés
- Gépi tanulás és adatfeldolgozás
- ez segít létrehozni képzési rendszerek, amelyek az egyéni oktatás és anyagok szerint a követelmény a diákok.
- repülőgép-vezérlés és robot mozgásvezérlés
miért használja a megerősítő tanulást?
itt vannak a megerősítés tanulásának elsődleges okai:
- ez segít megtalálni, hogy melyik helyzethez van szükség cselekvésre
- segít felfedezni, hogy melyik művelet hozza a legnagyobb jutalmat a hosszabb időszakban.
- a megerősítő tanulás jutalmazási funkciót is biztosít a tanulási ügynök számára.
- azt is lehetővé teszi, hogy kitalálja a legjobb módszert a nagy jutalmak megszerzésére.
mikor ne használjon megerősítő tanulást?
nem lehet alkalmazni erősítő tanulási modell minden a helyzet. Íme néhány feltétel, amikor nem szabad megerősítő tanulási modellt használni.
- ha elegendő adattal rendelkezik a probléma megoldásához egy felügyelt tanulási módszerrel
- ne feledje, hogy a megerősítő tanulás számítástechnikai szempontból nehéz és időigényes. különösen akkor, ha a cselekvési tér nagy.
A megerősítés tanulásának kihívásai
itt vannak a legfontosabb kihívások, amelyekkel szembe kell néznie a megerősítés megszerzése közben:
- Feature/reward design, amelyet nagyon be kell vonni
- a paraméterek befolyásolhatják a tanulás sebességét.
- a reális környezetek részleges megfigyelhetőséggel rendelkezhetnek.
- a túl sok megerősítés az állapotok túlterheléséhez vezethet, ami csökkentheti az eredményeket.
- a reális környezetek nem helyhez kötöttek lehetnek.
Összegzés:
- a megerősítő tanulás egy gépi tanulási módszer
- segít felfedezni, hogy melyik művelet hozza a legnagyobb jutalmat a hosszabb időszakban.
- a megerősítő tanulás három módszere: 1) értékalapú 2) Politikaalapú és modellalapú tanulás.
- ügynök, állapot, jutalom, környezet, a környezet Értékfüggvény-modellje, modell alapú módszerek, néhány fontos kifejezés az RL tanulási módszerben
- a megerősítő tanulás példája az, hogy a macskád olyan ügynök, amely ki van téve a környezetnek.
- ennek a módszernek a legnagyobb jellemzője, hogy nincs felügyelő, csak valós szám vagy jutalomjel
- a megerősítő tanulás két típusa 1) pozitív 2) negatív
- két széles körben használt tanulási modell 1) Markov döntési folyamat 2) Q tanulás
- a megerősítő tanulási módszer a környezettel való kölcsönhatáson működik, míg a felügyelt tanulási módszer az adott mintaadatokon vagy példákon működik.
- alkalmazás vagy megerősítés tanulási módszerek: Robotika ipari automatizáláshoz és üzleti stratégia tervezéshez
- ne használja ezt a módszert, ha elegendő adata van a probléma megoldásához
- a módszer legnagyobb kihívása az, hogy a paraméterek befolyásolhatják a tanulás sebességét