verzióinformáció: az oldal kódját a Stata 12-ben tesztelték.
a Poisson regressziót a változók számának modellezésére használják.
kérjük, vegye figyelembe: ennek az oldalnak az a célja, hogy megmutassa, hogyan kell használni a különféle adatelemzési parancsokat. Nem terjed ki a kutatási folyamat minden olyan aspektusára, amelyet a kutatók elvárnak. Nem terjed ki különösen az adatok tisztítására és ellenőrzésére, a feltételezések ellenőrzésére, a modelldiagnosztikára vagy a lehetséges nyomon követési elemzésekre.
példák a Poisson regresszióra
1. példa. Az öszvérrel vagy lórúgással megölt személyek száma a porosz hadseregben évente.Ladislaus Bortkiewicz 20 kötetből gyűjtött adatokat preussischen statisztika. Ezeket az adatokat a porosz hadsereg 10 hadtestén gyűjtötték az 1800-as évek végén, 20 év alatt.
2. példa. Az emberek száma a sorban előtted az élelmiszerboltban. A prediktorok magukban foglalhatják a jelenleg kedvezményes áron kínált tételek számát, valamint azt, hogy egy különleges esemény (például ünnep, nagy sportesemény) három vagy kevesebb napra van-e.
3. példa. A diákok által egy középiskolában szerzett díjak száma. A megszerzett díjak számának előrejelzői közé tartozik a Program típusa, amelybe a hallgató beiratkozott (pl. szakmai, általános vagy akadémiai), valamint a matematika záróvizsgájának pontszáma.
az adatok leírása
illusztráció céljából szimuláltunk egy adatkészletet, például a fenti 3.példát. Ebben a példában a num_awards az eredményváltozó, és jelzi a középiskolában tanulók által egy év alatt megszerzett díjak számát, A matematika egy folyamatos prediktor változó, amely a hallgatók pontszámait képviseli a matematikai záróvizsgán, a prog pedig egy kategorikus prediktor változó, három szinttel, amely jelzi a program típusát, amelybe a hallgatók beiratkoztak.
kezdjük az adatok betöltésével és néhány leíró statisztika megtekintésével.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
minden változónak 200 érvényes megfigyelése van, és eloszlásuk meglehetősen ésszerűnek tűnik. Ebben a konkrét esetben az eredményváltozónk feltétel nélküli átlaga és varianciája nem nagyon különbözik egymástól.
folytassuk a változók leírását ebben az adatkészletben. Az alábbi táblázat a díjak átlagos számát mutatja programtípusonként, és úgy tűnik, hogy a program típusa jó jelölt a díjak számának előrejelzésére, az eredményváltozónk, mert az eredmény átlagértéke prog szerint változik.
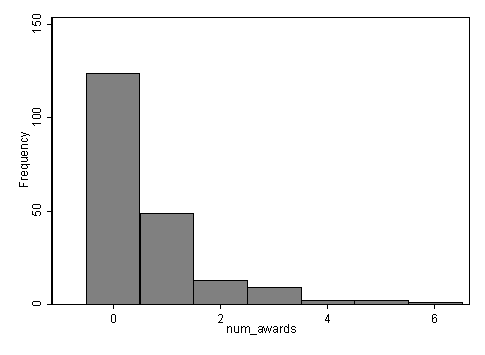
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
megfontolandó elemzési módszerek
az alábbiakban felsorolunk néhány lehetséges elemzési módszert. A felsorolt módszerek egy része meglehetősen ésszerű, míg mások vagy nem részesültek előnyben, vagy korlátozottak.
- Poisson regresszió-a Poisson regressziót gyakran használják a számlálási adatok modellezésére. A Poisson regresszió számos kiterjesztéssel rendelkezik, amelyek hasznosak a számlálási modellekhez.
- negatív binomiális regresszió-negatív binomiális regresszió használható a túl diszpergált számadatokhoz, vagyis amikor a feltételes variancia meghaladja a feltételes átlagot. A Poisson-regresszió általánosításának tekinthető, mivel ugyanaz az átlagos szerkezete, mint a Poisson-regressziónak, és van egy extra paramétere a túlzott diszperzió modellezésére. Ha az eredményváltozó feltételes eloszlása túl diszpergált,akkor a negatív binomialregesszió konfidencia intervallumai valószínűleg szűkebbek, mint a Poisson regresszió.
- nulla-felfújt regressziós modell – a nulla-felfújt modellek megpróbálják elszámolni a felesleges nullákat. Más szavakkal, az adatokban kétféle nulla létezik, az” igaz nullák “és a”felesleges nullák”. A nulla felfújt modellek két egyenletet becsülnek egyszerre, egyet a számlálási modellre, egyet a nullák feleslegére.
- az OLS regresszió – számlálási eredményváltozókat néha log-transzformálják és OLS regresszióval elemzik. Sok probléma merül fel ezzel a megközelítéssel, beleértve az adatvesztést a meghatározatlan értékek miatt, amelyeket a nulla naplója (amely nem definiált) és az elfogult becslések.
Poisson regresszió
Az alábbiakban a poisson paranccsal becsüljük meg a Poisson regressziós modellt. Az I. előtt prog azt jelzi, hogy ez egy tényezőváltozó (azaz., kategorikus változó), és hogy a modellben indikátorváltozók sorozataként kell szerepeltetni.
a VCE(robusztus) opciót használjuk a Cameron and Trivedi (2009) által javasolt paraméterbecslések robusztus standard hibáinak megszerzésére az alapul szolgáló feltételezések enyhe megsértésének ellenőrzésére.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
a két szabadságfokú chi-négyzet teszt azt jelzi, hogy a prog együttesen a num_awards statisztikailag szignifikáns előrejelzője.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
a modell illeszkedésének értékeléséhez az estat gof parancs használható a jóság-of-fit chi-négyzet teszt megszerzéséhez. Ez nem a modell koefficiensek tesztje (amelyet a fejléc információiban láttunk), hanem a modellforma tesztje: a poisson modellforma megfelel-e adatainknak?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
arra a következtetésre jutottunk, hogy a modell meglehetősen jól illeszkedik, mert a jóság-of-fit chi-négyzet teszt nem statisztikailag szignifikáns. Ha a teszt statisztikailag szignifikáns volt, az azt jelzi, hogy az adatok nem felelnek meg jól a modellnek. Ebben a helyzetben megpróbálhatjuk meghatározni, hogy vannak-e kihagyott prediktor változók, fennáll-e a linearitás feltételezése és/vagy fennáll-e a túlzott diszperzió kérdése.
néha előfordulhat, hogy a regressziós eredményeket incidenssebességi arányként szeretnénk bemutatni, használhatjuk az arr opciót. Ezek az IRR értékek megegyeznek a fenti kimeneti együtthatókkal exponenciált.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
a fenti kimenet azt jelzi, hogy az incidens aránya 2.a prog a referenciacsoport incidenciájának 2,96-szorosa (1.prog). Hasonlóképpen, az incidensek aránya 3.a prog 1,45-szerese annak a referenciacsoportnak, amely a többi változót állandó értéken tartja. A num_awards incidenssebességének százalékos változása 7% – os növekedést jelent a matematika minden egységnövekedése esetén.
Emlékezzünk vissza a modell egyenletünk formájára:
log(num_awards) = elfogás + b1(prog=2) + b2(prog=3) + b3math.
Ez azt jelenti:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3)) * EXP(b3math)
az együtthatók additív hatást fejtenek ki a log(y) skálán, az IRR pedig multiplikatív hatást fejt ki az Y skálán.
további információkat a különböző mutatókról, amelyekben az eredmények bemutathatók, és ezek értelmezését lásd regressziós modellek kategorikus függő változókhoz stata használatával, J. Scott Long and Jeremy Freese második kiadása (2006).
a modell jobb megértéséhez használhatjuk a margók parancsot. Az alábbiakban a margók paranccsal számítjuk ki az előrejelzett számokat a program minden szintjén, az összes többi változót (ebben a példában a matematikát) a modellben az átlagértékükön tartva.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
a fenti kimeneten azt látjuk, hogy a prog 1 .szintjének előre jelzett eseményszáma kb.21, tartja a matekot. A prog 2. szintjén előre jelzett események száma magasabb .62, és a prog 3. szintjének várható eseményszáma kb.31. Vegye figyelembe, hogy a prog 2.szintjének várható száma (.6249446/.211411) = 2,96-szor nagyobb, mint a prog 1.szintjének előre jelzett száma. Ez megegyezik azzal, amit az IRR kimeneti táblázatban láttunk.
Az alábbiakban megkapjuk a 35-től 75-ig terjedő matematikai értékek előrejelzett számát 10-es lépésekben.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
a fenti táblázat azt mutatja, hogy a prog a megfigyelt értékek és a matematika tartott 35 minden megfigyelések, az átlagos becsült száma (vagy átlagos száma díjat) szól .13; amikor math = 75, Az átlagos becsült szám körülbelül 2,17. Ha összehasonlítjuk az előrejelzett számokat math = 35 és math = 45, láthatjuk, hogy az arány (.2644714/.1311326) = 2.017. Ez megegyezik az 1,0727 IRR-jével 10 egységcsere esetén: 1,0727^10 = 2,017.
a felhasználó által írt fitstat parancs (valamint a Stata estat parancsai) további információk beszerzésére használható, amelyek hasznosak lehetnek a modellek összehasonlításában. Beírhatja a search fitstat parancsot a program letöltéséhez (lásd: Hogyan használhatom a search paranccsal programokat keresni és további segítséget kapni? További információ a keresés használatáról).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
az alábbi parancsokkal ábrázolhatja az előre jelzett események számát. A grafikon azt jelzi, hogy a legtöbb díjat az akadémiai programban résztvevők számára jósolják (prog = 2), különösen, ha a hallgató magas matematikai pontszámmal rendelkezik. A legkevesebb előre jelzett díjat azok a diákok az általános program (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
A megfontolandó dolgok
- Ha a túlzott diszperzió problémának tűnik, meg kell vizsgálnunk a először ellenőrizze, hogy a modellünk megfelelően van-e megadva, például kihagyott változók és funkcionális formák. Például, ha elhagytuk a prediktor változót progin a fenti példában úgy tűnik, hogy modellünknek problémája van a túlzott diszperzióval. Más szavakkal, egy rosszul meghatározott modell olyan tünetet mutathat, mint egy túlzott diszperziós probléma.
- feltételezve, hogy a modell helyesen van megadva, érdemes ellenőrizni a foroverdispersion-t. Ennek többféle módja van, beleértve a túl-diszperziós paraméter valószínűségi arányának tesztjét alfa ugyanazon regressziós modell futtatásával negatív binomiális eloszlás (nbreg).
- a túlzott diszperzió egyik gyakori oka a felesleges nullák, amelyeket viszont egy további adatgeneráló folyamat generál. Ebben a helyzetben figyelembe kell venni a nulla felfújt modellt.
- Ha az adatgeneráló folyamat nem tesz lehetővé semmilyen 0s – t (például a kórházban töltött napok számát), akkor a nulla csonka modell megfelelőbb lehet.
- a számlálási adatoknak gyakran van expozíciós változója, amely azt jelzi, hogy az esemény hányszor történhetett meg. Ezt a változót be kell építeni egy Poisson modellbe az exp() opció használatával.
- a Poisson regresszióban az eredményváltozónak nem lehetnek negatív számai, és az expozíciónak sem lehet 0S értéke.
- a Stata-ban a Poisson-modell a glm paranccsal becsülhető meg a log hivatkozással és a Poisson-családdal.
- a glm paranccsal szerezheti be a maradványokat a Poisson-modell Egyéb feltételezéseinek ellenőrzéséhez (lásd Cameron and Trivedi (1998) és Dupont (2002) további információkért).
- a pszeudo-R-négyzet sok különböző mértéke létezik. Mindannyian megpróbálnak hasonló információkat szolgáltatni, mint az R-négyzet az OLS regresszióban, annak ellenére, hogy egyikük sem értelmezhető pontosan úgy, ahogy az R-négyzet az OLS regresszióban értelmezhető. A különböző pszeudo-R-négyzetek megvitatását lásd Long and Freese (2006) vagy a GYIK oldalunkmilyen ál-r-négyzetek?.
- a Poisson regressziót a maximális valószínűség becslésével becsüljük meg. Általában nagy mintaméretet igényel.
Lásd még
- megjegyzésekkel ellátott kimenet a poisson parancshoz
- Stata GYIK: Hogyan használhatom a countfit-et a count modell kiválasztásakor?
- Stata Online kézikönyv
- poisson
- Stata GYIK
- hogyan számítják ki poisson és nbreg a standard hibákat és konfidencia intervallumokat az incidencia-Arány arányok (IRR) tekintetében?
- Cameron, A. C. és Trivedi, P. K. (2009). Mikroökonometria Stata Használatával. Főiskolai állomás, TX: Stata Press.
- Cameron, A. C. és Trivedi, P. K. (1998). A számlálási adatok regressziós elemzése. New York: Cambridge Press.
- Cameron, A. C. előlegek száma adatok regressziós Talk az alkalmazott statisztika Workshop, március 28, 2009.http://cameron.econ.ucdavis.edu/racd/count.html.
- Dupont, W. D. (2002). Statisztikai modellezés Orvosbiológiai kutatók számára: egyszerű bevezetés a komplex adatok elemzéséhez. New York: Cambridge Press.
- Long, J. S. (1997). Regressziós modellek kategorikus és korlátozott függő változókhoz.Thousand Oaks, hogy: Sage Publications.
- Long, J. S. és Freese, J. (2006). Regressziós modellek kategorikus függő változókhoz Stata, második kiadás. Főiskolai állomás, TX: Stata Press.