Última actualización el 17 de febrero de 2021
Una predicción desde una perspectiva de aprendizaje automático es un punto único que oculta la incertidumbre de esa predicción.
Los intervalos de predicción proporcionan una forma de cuantificar y comunicar la incertidumbre en una predicción. Son diferentes de los intervalos de confianza que, en cambio, buscan cuantificar la incertidumbre en un parámetro de población, como una media o desviación estándar. Los intervalos de predicción describen la incertidumbre para un único resultado específico.
En este tutorial, descubrirá el intervalo de predicción y cómo calcularlo para un modelo de regresión lineal simple.
Después de completar este tutorial, sabrá:
- Que un intervalo de predicción cuantifica la incertidumbre de una predicción de un solo punto.
- Que los intervalos de predicción se pueden estimar analíticamente para modelos simples, pero son más difíciles para modelos de aprendizaje automático no lineales.
- Cómo calcular el intervalo de predicción para un modelo de regresión lineal simple.
Inicie su proyecto con my new book Statistics for Machine Learning, que incluye tutoriales paso a paso y los archivos de código fuente de Python para todos los ejemplos.
Comencemos.
- Actualizado Jun / 2019: Nivel de significación corregido como fracción de las desviaciones estándar.
- Actualizado en abril de 2020: Error tipográfico corregido en la gráfica del intervalo de predicción.

Intervalos de predicción para Aprendizaje automático
Foto de Jim Bendon, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en 5 partes; son:
- ¿Qué tiene de malo una estimación puntual?
- ¿Qué Es un Intervalo de Predicción?
- Cómo Calcular un Intervalo de Predicción
- Intervalo de Predicción para Regresión Lineal
- Ejemplo trabajado
¿Necesita ayuda con las estadísticas para el Aprendizaje Automático?
Tome mi curso intensivo de correo electrónico gratuito de 7 días ahora (con código de muestra).
Haga clic para inscribirse y también obtenga una versión gratuita en PDF del curso.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict (X)
|
Donde yhat es el resultado estimado o la predicción realizada por el modelo entrenado para los datos de entrada dados X.
Esta es una predicción puntual.
Por definición, es una estimación o una aproximación y contiene cierta incertidumbre.
La incertidumbre proviene de los errores en el propio modelo y del ruido en los datos de entrada. El modelo es una aproximación de la relación entre las variables de entrada y las variables de salida.
Dado el proceso utilizado para elegir y afinar el modelo, será la mejor aproximación dada la información disponible, pero seguirá cometiendo errores. Los datos del dominio ocultarán naturalmente la relación subyacente y desconocida entre las variables de entrada y salida. Esto hará que sea un desafío adaptarse al modelo, y también será un desafío para que un modelo adecuado haga predicciones.
Dadas estas dos fuentes principales de error, su predicción puntual a partir de un modelo predictivo es insuficiente para describir la verdadera incertidumbre de la predicción.
¿Qué es un Intervalo de Predicción?
Un intervalo de predicción es una cuantificación de la incertidumbre en una predicción.
Proporciona límites superiores e inferiores probabilísticos en la estimación de una variable de resultado.
Un intervalo de predicción para una observación futura única es un intervalo que, con un grado de confianza especificado, contendrá una observación futura seleccionada aleatoriamente de una distribución.
– Página 27, Intervalos estadísticos: Una Guía para profesionales e Investigadores, 2017.
Los intervalos de predicción se usan más comúnmente cuando se hacen predicciones o pronósticos con un modelo de regresión, donde se está prediciendo una cantidad.
Un ejemplo de la presentación de un intervalo de predicción es el siguiente:
Dada una predicción de ‘y’ dada ‘x’, hay una probabilidad del 95% de que el rango ‘a’ a ‘b’ cubra el resultado verdadero.
El intervalo de predicción rodea la predicción realizada por el modelo y, con suerte, cubre el rango del resultado real.
El siguiente diagrama ayuda a comprender visualmente la relación entre la predicción, el intervalo de predicción y el resultado real.
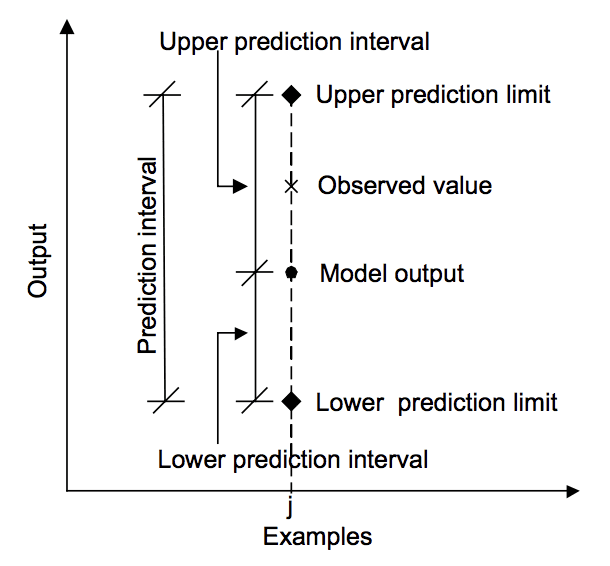
Relación entre predicción, valor real e intervalo de predicción.Tomado de «Machine learning approaches for estimation of prediction interval for the model output», 2006.
Un intervalo de predicción es diferente de un intervalo de confianza.
Un intervalo de confianza cuantifica la incertidumbre en una variable poblacional estimada, como la media o la desviación estándar. Mientras que un intervalo de predicción cuantifica la incertidumbre en una sola observación estimada de la población.
En el modelado predictivo, un intervalo de confianza se puede utilizar para cuantificar la incertidumbre de la habilidad estimada de un modelo, mientras que un intervalo de predicción se puede utilizar para cuantificar la incertidumbre de un pronóstico único.
Un intervalo de predicción a menudo es mayor que el intervalo de confianza, ya que debe tener en cuenta el intervalo de confianza y la varianza en la variable de salida que se está prediciendo.
Los intervalos de predicción siempre serán más amplios que los intervalos de confianza porque tienen en cuenta la incertidumbre asociada con e , el error irreducible.
– Página 103, Una Introducción al Aprendizaje Estadístico: con Aplicaciones en R, 2013.
Cómo calcular un intervalo de predicción
Un intervalo de predicción se calcula como una combinación de la varianza estimada del modelo y la varianza de la variable de resultado.
Los intervalos de predicción son fáciles de describir, pero difíciles de calcular en la práctica.
En casos simples como la regresión lineal, podemos estimar el intervalo de predicción directamente.
En los casos de algoritmos de regresión no lineal, como las redes neuronales artificiales, es mucho más desafiante y requiere la elección e implementación de técnicas especializadas. Se pueden utilizar técnicas generales como el método de remuestreo bootstrap, pero su cálculo es costoso desde el punto de vista computacional.
El artículo «A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances» proporciona un estudio razonablemente reciente de los intervalos de predicción para modelos no lineales en el contexto de las redes neuronales. La siguiente lista resume algunos métodos que se pueden usar para predecir la incertidumbre de los modelos de aprendizaje automático no lineales:
- El método Delta, del campo de regresión no lineal.
- El método bayesiano, de modelado y estadística bayesianos.
- El Método de Estimación de la Varianza Media, utilizando estadísticas estimadas.
- El método Bootstrap, usando remuestreo de datos y desarrollando un conjunto de modelos.
Podemos hacer el cálculo de un intervalo de predicción concreto con un ejemplo trabajado en la siguiente sección.
Intervalo de predicción para Regresión Lineal
Una regresión lineal es un modelo que describe la combinación lineal de entradas para calcular las variables de salida.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
No conocemos los valores verdaderos de los coeficientes b0 y b1. Tampoco conocemos los parámetros de población verdaderos, como la media y la desviación estándar para x o y. Todos estos elementos deben estimarse, lo que introduce incertidumbre en el uso del modelo para hacer predicciones.
Podemos hacer algunas suposiciones, como las distribuciones de x e y y los errores de predicción realizados por el modelo, llamados residuos, son gaussianos.
El intervalo de predicción alrededor de yhat se puede calcular de la siguiente manera:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
No lo conocemos en la práctica. Podemos calcular una estimación imparcial de la desviación estándar prevista de la siguiente manera (tomada de enfoques de aprendizaje automático para la estimación del intervalo de predicción para la salida del modelo):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
Ejemplo trabajado
Hagamos concreto el caso de los intervalos de predicción de regresión lineal con un ejemplo trabajado.
Primero, definamos un conjunto de datos simple de dos variables donde la variable de salida (y) depende de la variable de entrada (x) con algún ruido gaussiano.
El siguiente ejemplo define el conjunto de datos que usaremos para este ejemplo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# generar variables relacionadas con el
from numpy import media
from numpy import std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
Una parcela del conjunto de datos a continuación, se crea.
Podemos ver la clara relación lineal entre las variables con la dispersión de los puntos resaltando el ruido o error aleatorio en la relación.
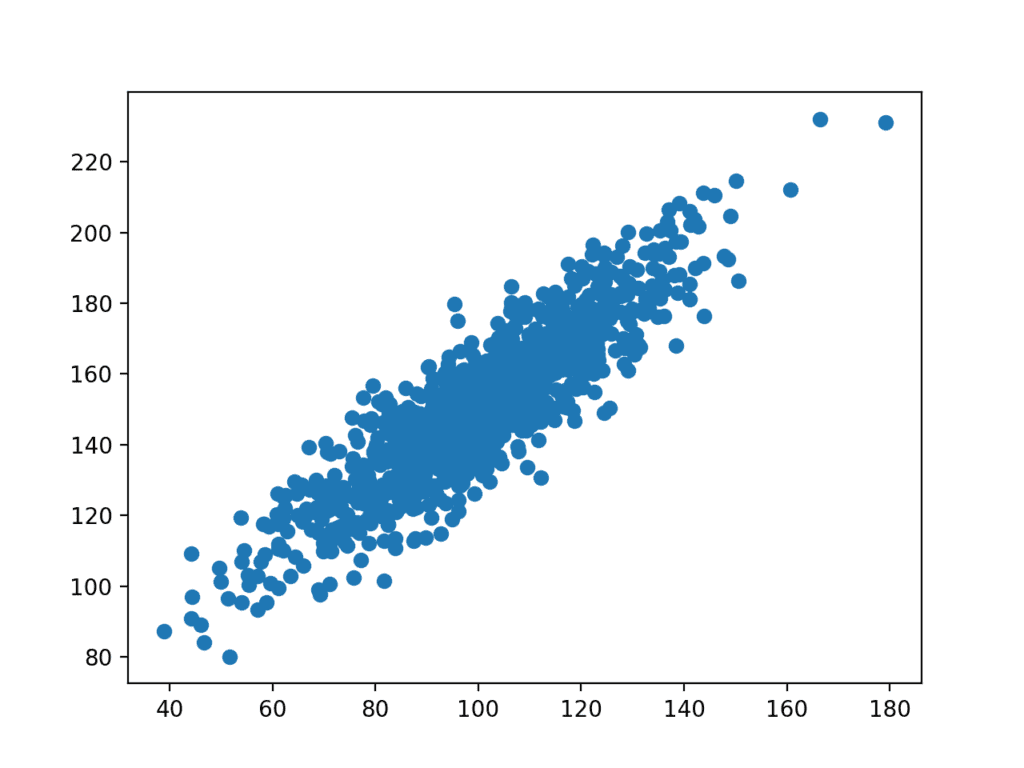
Gráfico de dispersión de Variables Relacionadas
A continuación, podemos desarrollar una regresión lineal simple que dada la variable de entrada x, predecirá la variable y. Podemos usar la función linregress() SciPy para ajustar el modelo y devolver los coeficientes b0 y b1 para el modelo.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# simple de regresión no lineal modelo
de numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‘b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
b0=1.011, b1=49.117
|
Los coeficientes se utiliza con las entradas del conjunto de datos para hacer una predicción. Las entradas resultantes y los valores y previstos se representan como una línea en la parte superior del gráfico de dispersión para el conjunto de datos.
Podemos ver claramente que el modelo ha aprendido la relación subyacente en el conjunto de datos.
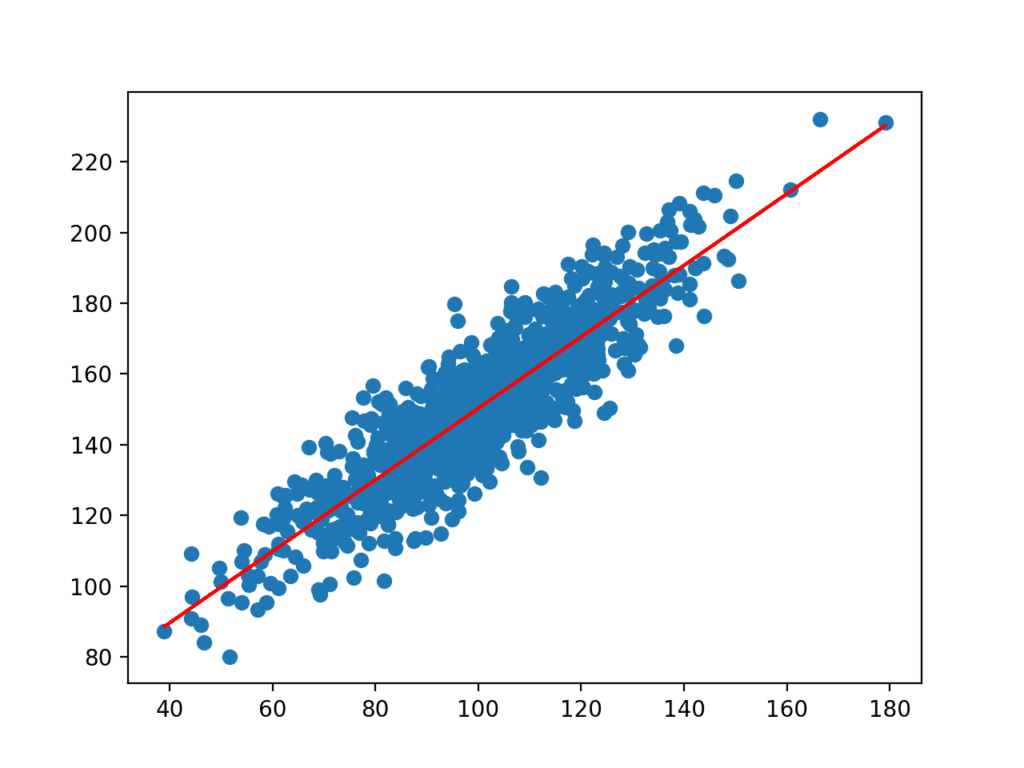
Gráfico de Dispersión de Conjunto de Datos con Línea para Modelo de Regresión Lineal Simple
Ahora estamos listos para hacer una predicción con nuestro modelo de regresión lineal simple y agregar un intervalo de predicción.
Ajustaremos el modelo como antes. Esta vez tomaremos una muestra del conjunto de datos para demostrar el intervalo de predicción. Usaremos la entrada para hacer una predicción, calcular el intervalo de predicción para la predicción y comparar la predicción y el intervalo con el valor esperado conocido.
Primero, definamos los valores de entrada, predicción y esperados.
|
1
2
3
|
x_in = x
y_out = y
yhat_out = yhat
|
a continuación, se puede estimar el estándar de la curvatura en la predicción de la dirección.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.estadísticas importar linregress
de matplotlib importar piplot
# generador de números aleatorios de semilla
seed(1)
# preparar los datos
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# ajustar el modelo de regresión no lineal
b1, b0, r_value, p_value, std_err = linregress(x, y)
# marcar predicciones
yhat = b0 + b1 * x
# definir nueva entrada, valor esperado y predicción
x_in = x
y_out = y
yhat_out = yhat
# stdev estimado de yhat
sum_errs = arraysum ((y-yhat) * * 2)
stdev = sqrt(1/(len(y) -2) * sum_errs)
# calcular intervalo de predicción
intervalo = 1.96 * stdev
print(‘Intervalo de predicción: %.intervalo 3f’%)
lower, upper = intervalo yhat_out, intervalo yhat_out +
print (‘95% % de probabilidad de que el valor verdadero esté entre %.3f y %.3f’ % (inferior, superior))
print (‘Valor verdadero: %.3f ‘ % y_out)
# conjunto de datos de trazado y predicción con intervalo
pyplot.dispersión (x, y)
pyplot.plot (x, yhat, color=’red’)
pyplot.errorbar (x_in, yhat_out, yerr=intervalo, color=’negro’, fmt=’o’)
pyplot.show()
|
Al ejecutar el ejemplo, se estima la desviación estándar yhat y, a continuación, se calcula el intervalo de predicción.
Una vez calculado, el intervalo de predicción se presenta al usuario para la variable de entrada dada. Debido a que inventamos este ejemplo, conocemos el verdadero resultado, que también mostramos. Podemos ver que en este caso, el intervalo de predicción del 95% cubre el valor esperado verdadero.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
También se crea un gráfico que muestra el conjunto de datos sin procesar como un gráfico de dispersión, las predicciones para el conjunto de datos como una línea roja y la predicción y el intervalo de predicción como un punto negro y una línea, respectivamente.
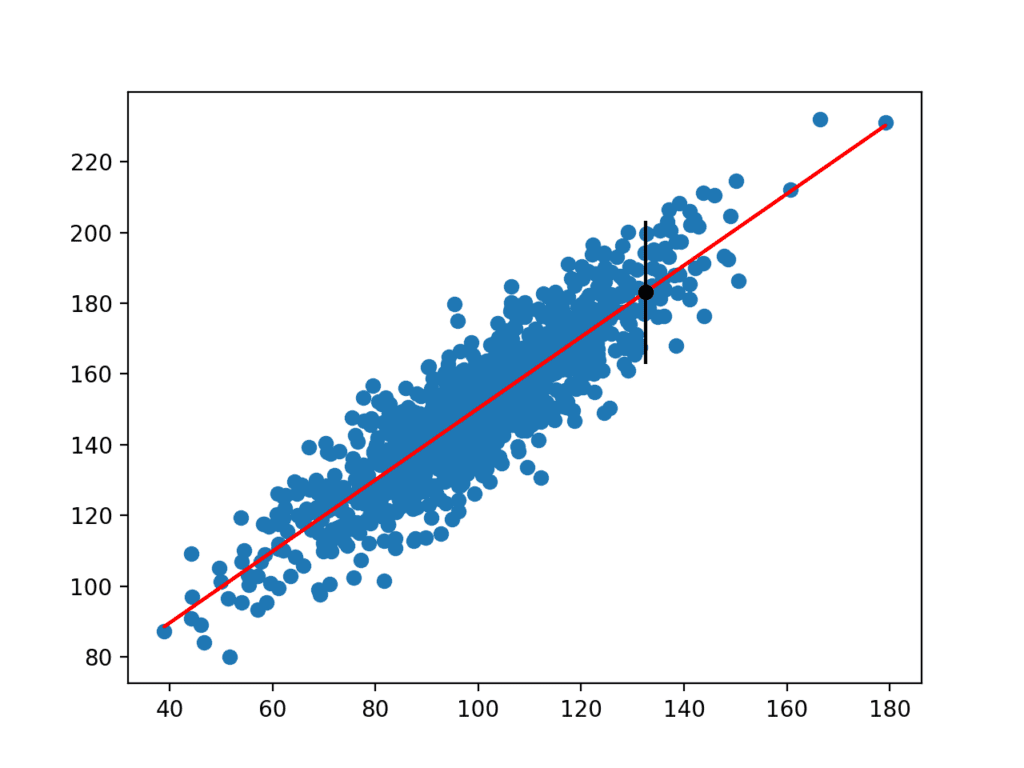
Gráfico de Dispersión de Conjunto de Datos Con Modelo Lineal e Intervalo de Predicción
Extensiones
Esta sección enumera algunas ideas para ampliar el tutorial que tal vez desee explorar.
- Resuma la diferencia entre los intervalos de tolerancia, confianza e predicción.
- Desarrolle un modelo de regresión lineal para un conjunto de datos de aprendizaje automático estándar y calcule los intervalos de predicción para un conjunto de pruebas pequeño.
- Describa en detalle cómo funciona un método de intervalo de predicción no lineal.
Si explora alguna de estas extensiones, me encantaría saberlo.
Lectura adicional
Esta sección proporciona más recursos sobre el tema si desea profundizar más.
Publicaciones
- Cómo Informar el Rendimiento del Clasificador con Intervalos de Confianza
- Cómo Calcular los Intervalos de Confianza de Arranque Para los Resultados de Aprendizaje Automático en Python
- Comprender la Incertidumbre de Pronóstico de Series Temporales Utilizando Intervalos de Confianza con Python
- Estimar el Número de Repeticiones de Experimentos para Algoritmos Estocásticos de Aprendizaje Automático
Libros
- Comprender Las Nuevas Estadísticas: Tamaños de Efectos, Intervalos de Confianza y Meta-Análisis, 2017.
- Intervalos estadísticos: Una Guía para Profesionales e Investigadores, 2017.
- Una Introducción al Aprendizaje Estadístico: con Aplicaciones en R, 2013.
- Introducción a las Nuevas Estadísticas: Estimación, Ciencia Abierta y Más allá, 2016.
- Pronóstico: principios y práctica, 2013.
Artículos
- Comparación de algunas estimaciones de errores para modelos de redes neuronales, 1995.
- Enfoques de aprendizaje automático para la estimación del intervalo de predicción para la salida del modelo, 2006.
- A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances, 2010.
API
- scipy.estadísticas.API linregress ()
- matplotlib.pyplot.API de dispersión ()
- matplotlib.pyplot.API de errorbar ()
Artículos
- Intervalo de predicción en Wikipedia
- Intervalo de predicción de arranque en Validación cruzada
Resumen
En este tutorial, descubrió el intervalo de predicción y cómo calcularlo para un modelo de regresión lineal simple.
Específicamente, aprendiste:
- Que un intervalo de predicción cuantifica la incertidumbre de una predicción de un solo punto.
- Que los intervalos de predicción se pueden estimar analíticamente para modelos simples, pero son más difíciles para modelos de aprendizaje automático no lineales.
- Cómo calcular el intervalo de predicción para un modelo de regresión lineal simple.
¿Tiene alguna pregunta?Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.
Conseguir una Manija en las Estadísticas para el Aprendizaje de Máquina!

Desarrolle una comprensión práctica de las estadísticas
…escribiendo líneas de código en python
Descubre cómo en mi nuevo libro electrónico:
Métodos estadísticos para Aprendizaje automático
Proporciona tutoriales de autoaprendizaje sobre temas como:
Pruebas de hipótesis, Correlación, Estadísticas no Paramétricas, Remuestreo y mucho más…
Descubra cómo Transformar los Datos en Conocimiento
Omita los aspectos académicos. Sólo Resultados.
Ver Lo que está Dentro de