活性化関数は、ディープラーニングにおけるニューラルネットワークの最も重要な部分である。 深層学習では、ニューラルネットワークと活性化機能の助けを借りて対処するために必要な画像分類、言語変換、物体検出などが非常に複雑なタスクです。 だから、それがなければ、これらのタスクは処理するのが非常に複雑です。 一言で言えば、ニューラルネットワークは、基本的に脳がどのように理解するか、どのように模倣する機械学習における非常に強力な技術ですか? 脳は、環境からの入力として刺激を受け取り、それを処理し、それに応じて出力を生成します。
はじめに
ニューラルネットワーク活性化関数は、一般的には、深い学習の最も重要なコンポーネントであり、彼らは基本的に深い学習モデルの出力、その精度、および巨大なスケールのニューラルネットワークを設計または分割することができ、トレーニングモデルの性能効率を決定するために使用されます。
活性化関数は、収束するニューラルネットワークの能力と収束速度にかなりの影響を残している、あなたはどのようにしたくありませんか? のは、活性化機能、活性化機能の種類の紹介を続けてみましょう&このブログを通じて、その重要性と制限。
活性化機能とは何ですか?
活性化関数は、入力または入力のセットの出力を定義するか、または他の用語では、入力で与えられたノードの出力のノードを定義します。 彼らは基本的にニューロンを無効にするか、所望の出力を得るためにそれらを活性化することにします。 また、入力に対して非線形変換を実行して、複雑なニューラルネットワークでより良い結果を得ることができます。
活性化機能はまた、1から-1の間の範囲内の任意の入力の出力を正規化するのに役立ちます。 活性化関数は効率的でなければならず,ニューラルネットワークは何百万ものデータポイントで訓練されることがあるため,計算時間を短縮する必要がある。
活性化機能は、基本的に、入力または受信情報が関連しているか、それは無関係であることを任意のニューラルネットワークで決定します。 ニューロンとは何か、そして活性化関数が出力値をいくらかの限界に制限する方法をよりよく理解するための例を見てみましょう。
ニューロンは基本的に入力の加重平均であり、この合計は活性化関数を通過して出力を取得します。P>
Y=∑(weights*input+bias)
ここで、Yは範囲-無限大から+無限大までのニューロンに対して何でもかまいません。 したがって、目的の予測または一般化された結果を得るには、出力をバインドする必要があります。P>
Y=活性化関数(weights(weights*input+bias))
だから、そのニューロンを活性化関数に渡して出力値をバインドします。
なぜ活性化機能が必要なのですか?
活性化関数がなければ、重みとバイアスは線形変換しか持たない、またはニューラルネットワークは単なる線形回帰モデルであり、線形方程式は一度の多項式であり、解くのは簡単ですが、複雑な問題や高次多項式を解く能力の点では制限されています。
しかし、それとは反対に、ニューラルネットワークへの活性化関数の追加は、入力への非線形変換を実行し、言語翻訳や画像分類などの複雑な問題を解
それに加えて、活性化関数は、ニューラルネットワークにおける勾配損失関数を測定するために逆伝播を実行しながら、逆伝播、最適化された戦略を容易に実装することができるため、微分可能である。
活性化関数の種類
最も有名な活性化関数は、以下に与えられている、
-
バイナリステップ
-
リニア
-
リークレル
-
シグモイド
-
Tanh
-
ソフトマックス
1. バイナリステップ活性化機能
この活性化機能は非常に基本的な、それは我々が出力をバインドしようとすると、毎回気になります。 これは基本的に閾値ベース分類器であり、この中で、ニューロンが活性化または非活性化されるべき出力を決定するためにいくつかの閾値を決定する。
f(x)=1if x>0else0if x<0
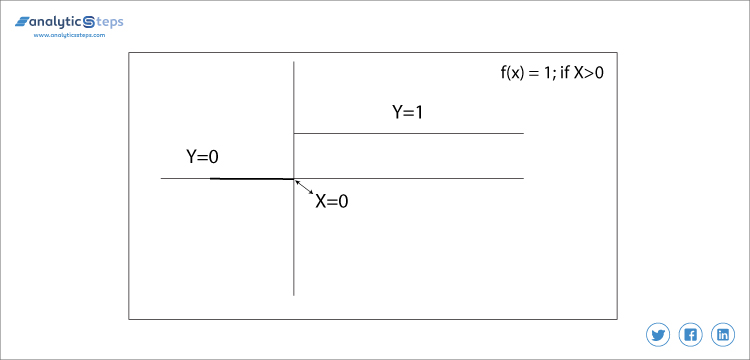
バイナリステップ関数
この中で、我々は0にしきい値を決定します。 バイナリ問題や分類器を分類することは非常に簡単で便利です。
2. 線形活性化関数
これは、私たちの関数は、ニューロンまたは入力の重み付け合計に正比例する単純な直線活性化関数です。 線形活性化関数は広範囲の活性化を与えるのに優れており、正の傾きの線は入力速度が増加するにつれて発射速度を増加させる可能性がある。
バイナリでは、ニューロンが発射されているかどうかのいずれかです。 深い学習で勾配降下法を知っていれば、この関数では微分が一定であることに気付くでしょう。
Y=mZ
ここで、zに関する導関数は定数mです。意味勾配も一定であり、Zとは何の関係もありません。
この中で、私たちの第二の層は、前の層の入力の線形関数の出力です。 ちょっと待って、すべてのレイヤーを比較し、最初と最後を除くすべてのレイヤーを削除すると、最初のレイヤーの線形関数である出力しか得られないこ
3. ReLU(Rectified Linear unit)Activation function
Rectified linear unitまたはReLUは、0から無限大までの範囲で最も広く使用されているactivation functionであり、すべての負の値はゼロに変換され、この変換レートは非常に高速であり、問題を作成するデータに適切にマップしたりフィットしたりすることはできませんが、問題がある場合には解決策があります。
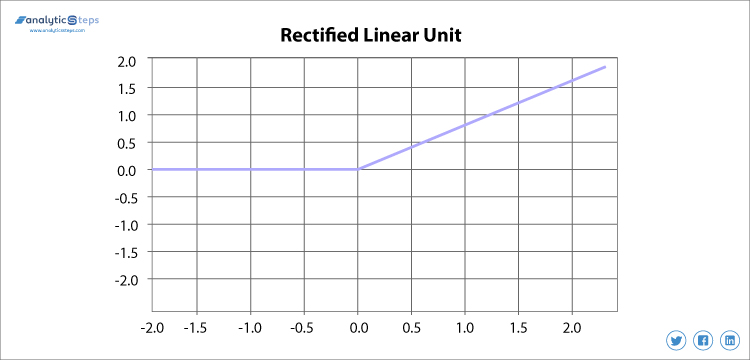
整流線形ユニット活性化関数
私たちは、漏れReLUの範囲で、この不適当を避けるためにReLUの代わりに漏れReLU関数を使用し、パフォーマ
漏れやすいReLU活性化関数
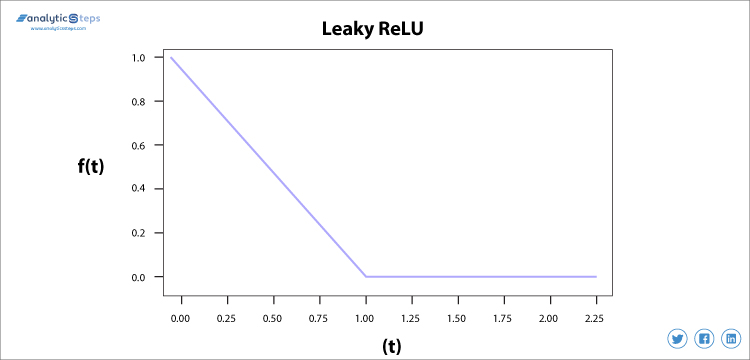
漏れやすいReLU活性化関数
ReLUで説明したように、”死ぬReLU”問題を解決するために漏れやすいReLU活性化関数が必要でした。
シグモイド活性化関数
シグモイド活性化関数は、それが大きな効率でそのタスクを行うように主に使用され、基本的には意思決定に向けた確率論的アプローチであり、0から1の間の範囲であるため、意思決定を行うか、出力を予測する必要があるとき、我々は範囲が最小であるため、この活性化関数を使用するので、予測はより正確であろう。
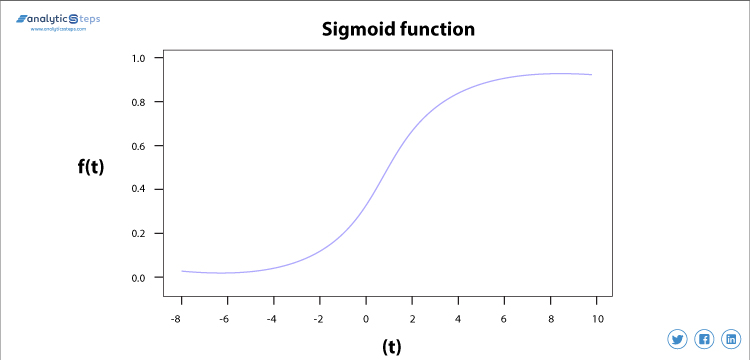
シグモイド活性化関数
シグモイド関数の式は
f(x)=1/(1+e(-x))
f(x)=1/(1+e(-x))
シグモイド関数は、主に0から1の範囲の間で大きな入力を変換するために発生する消失勾配問題と呼ばれる問題を引き起こし、その導関数ははるかに小さくなり、満足のいく出力を与えない。 この問題を解決するために、ReLUのような別の活性化関数が使用され、小さな導関数問題がない場合に使用されます。
双曲線正接活性化関数(Tanh)
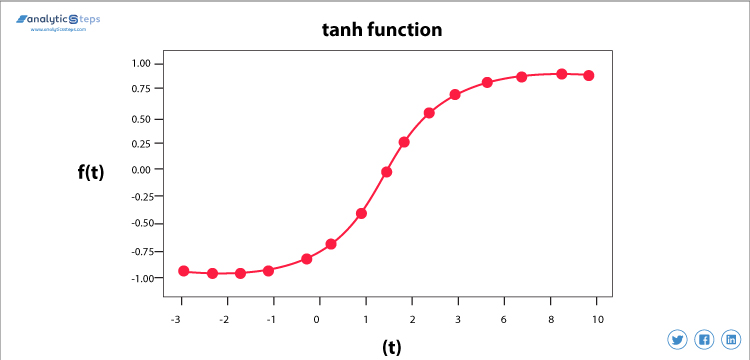
Tanh活性化関数
この活性化関数は、sigmoid関数よりもわずかに優れています。sigmoid関数のように、二つのクラスを予測したり区別したりするためにも使用されますが、負の入力を負の量にマップし、-1から1の間の範囲にマップします。
ソフトマックス活性化機能
ソフトマックスは、主に最後の層iで使用されます。意思決定のための出力層sigmoid活性化と同じように、softmaxは基本的に入力変数に重みに従って値を与え、これらの重みの合計は最終的には1になります。
バイナリ分類のSoftmax
バイナリ分類の場合、sigmoidとsoftmaxの両方が等しく親しみやすいですが、マルチクラス分類問題の場合は、一般的にsoftmaxとcross-entropy
結論
活性化関数は、入力への非線形変換を実行し、より複雑なタスクを理解して実行することを堪能にする重要な関数です。 我々は、それらの制限(もしあれば)と7majorly使用される活性化関数を議論してきた、これらの活性化関数は、同じ目的のために、異なる条件で使用されています。