強化学習とは何ですか?
強化学習は、ソフトウェアエージェントが環境内でどのように行動すべきかに関する機械学習方法として定義されています。 強化学習は、累積報酬の一部を最大化するのに役立つ深層学習メソッドの一部です。
このニューラルネットワーク学習方法は、複雑な目的を達成したり、多くのステップにわたって特定の次元を最大化する方法を学ぶのに役立ちます。
強化学習チュートリアルでは、次のことを学びます。
- 強化学習とは何ですか?
- 深い強化学習法で使用される重要な用語
- 強化学習はどのように機能しますか?
- 強化学習アルゴリズム
- 強化学習の特性
- 強化学習の種類
- 強化学習の学習モデル
- 強化学習対教師あり学習
- 強化学習のアプ
- 強化学習を使用しない場合は?
- 強化学習の課題
深い強化学習法で使用される重要な用語
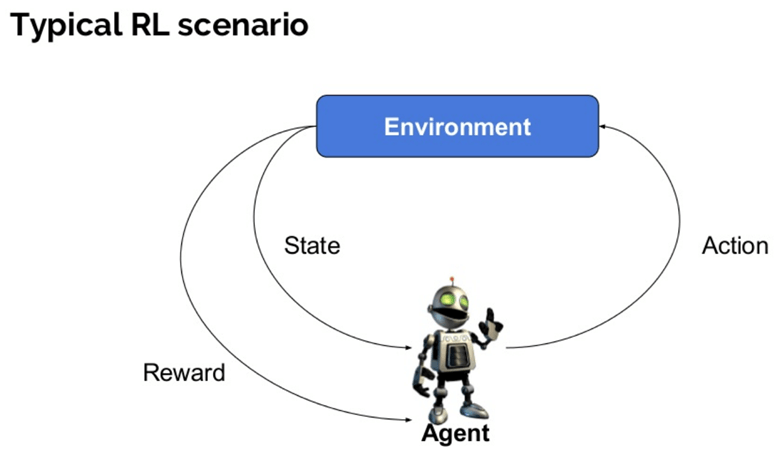
強化AIで使用される重要な用語は次のとおりです。
- エージェント:それはいくつかの報酬を得るために環境でアクションを実行します。
- 環境(e):エージェントが直面しなければならないシナリオ。
- 報酬(R): 彼または彼女は、特定のアクションやタスクを実行するときにエージェントに与えられた即時のリターン。
- State(s):Stateは、環境によって返される現在の状況を指します。
- ポリシー(?):現在の状態に基づいて次のアクションを決定するためにエージェントによって適用される戦略です。
- 値(V):それは短期的な報酬と比較して、割引と長期的なリターンを期待されています。
- 値関数:報酬の合計金額である状態の値を指定します。 それはその状態から始まる期待されるべきエージェントです。
- 環境のモデル:これは環境の動作を模倣します。 これは、推論を行い、環境がどのように動作するかを判断するのに役立ちます。
- モデルベースの方法:モデルベースの方法を使用する強化学習問題を解決するための方法です。 q値またはアクション値(Q):Q値は値と非常によく似ています。
- Q値またはアクション値(Q):Q値は値に非常に似ています。 この2つの唯一の違いは、現在のアクションとして追加のパラメータを取ることです。
強化学習はどのように機能しますか?
強化学習の仕組みを説明するのに役立つ簡単な例を見てみましょう。
あなたの猫に新しいトリックを教えるシナリオを考えてみましょう
- 猫は英語や他の人間の言語を理解していないので、私たちは何をすべきかを直接彼女に伝えることはできません。 代わりに、私たちは別の戦略に従います。
- 私たちは状況をエミュレートし、猫は多くの異なる方法で応答しようとします。 猫の反応が望ましい方法であれば、私たちは彼女の魚を与えるでしょう。
- 今、猫が同じ状況にさらされるたびに、猫はより多くの報酬(食べ物)を得ることを期待して、さらに熱心に同様の行動を実行します。 それは猫が肯定的な経験から”何をすべきか”から取得することを学ぶようなものです。
- 同時に、猫はまた、否定的な経験に直面したときに何をしないかを学びます。
例についての説明:H3>
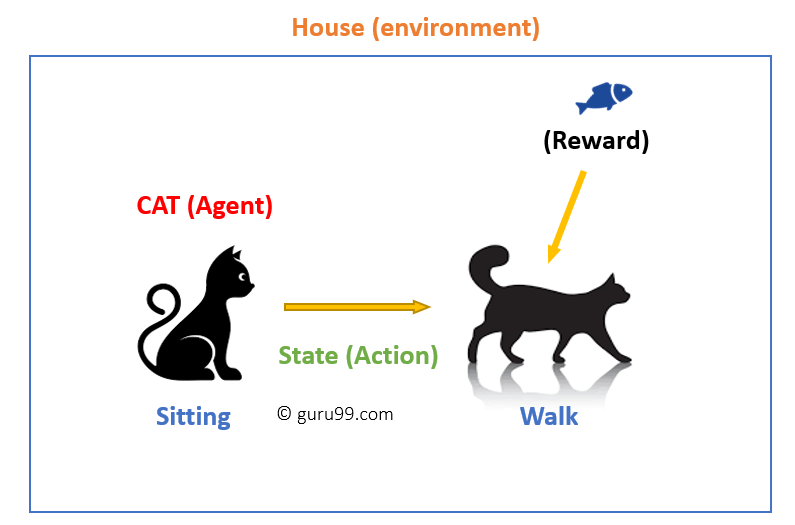
強化学習の仕組み
- あなたの猫は環境にさらされているエージェントです。 この場合、それはあなたの家です。 状態の例は、あなたの猫が座っている可能性があり、あなたは歩くために猫のために特定の単語を使用します。
- 私たちのエージェントは、ある”状態”から別の”状態”へのアクション遷移を実行することによって反応します。”
- たとえば、あなたの猫は座ってから歩くようになります。
- エージェントの反応はアクションであり、ポリシーは、より良い結果を期待して状態を与えられたアクションを選択する方法です。
- 移行後、彼らは見返りに報酬やペナルティを得ることができます。
強化学習アルゴリズム
強化学習アルゴリズムを実装するには三つのアプローチがあります。 値ベースの強化学習法では、値関数V(s)を最大化しようとする必要があります。
値ベースの強化学習法では、値関数V(s)を最大化する必要があります。
値ベースの強化学習法では、値関数V(s)を最大 この方法では、エージェントは、ポリシーの下で現在の状態の長期的なリターンを期待していますか?.
Policy-based:
Policy-based rlメソッドでは、すべての状態で実行されるアクションが将来最大の報酬を得るのに役立つようなポリシーを思い出そうとします。
ポリシーベースの方法の二つのタイプは次のとおりです。
- 決定論的:任意の状態のために、同じアクションがポリシーによって生成されますか?.
- 確率的:すべてのアクションは、次の式によって決定される一定の確率を持っています。確率的ポリシー:
n{a\s) = P\A, = a\S, =S]
モデルベース: この強化学習法では、環境ごとに仮想モデルを作成する必要があります。 エージェントは、その特定の環境で実行することを学習します。
強化学習の特性
ここでは強化学習の重要な特性があります
- 何のスーパーバイザ、唯一の実数または報酬信号はありません
- シーケンシャルp>強化学習方法の二種類は次のとおりです。
正:
これは、特定の動作のために発生するイベントとして定義されています。 それは行動の強さそして頻度を高め、代理店によって取られる行為で肯定的に影響を与える。 このタイプの補強は、パフォーマンスを最大化し、より長期間にわたって変化を維持するのに役立ちます。
しかし、あまりにも多くの強化は、結果に影響を与える可能性があり、状態の過剰最適化につながる可能性があります。
負:
負の強化は、停止または回避する必要がある負の状態のために発生する行動の強化として定義されます。
負の強化は、負の強化と定義されています。
負の強化 それは性能の最低の立場を定義するのを助ける。 しかし、この方法の欠点は、最小の動作を満たすのに十分なものを提供することです。
強化の学習モデル
強化学習には二つの重要な学習モデルがあります。
- マルコフ決定プロセス
- Q学習
マルコフ決定プロセス
以下のパラメータは、解を得るために使用されます。:
- アクションのセット-a
- 状態のセット-S
- 報酬-R
- ポリシー-n
- 値-V
強化学習における解をマッピングするための数学的アプローチは、マルコフ決定プロセスまたは(MDP)として偵察される。
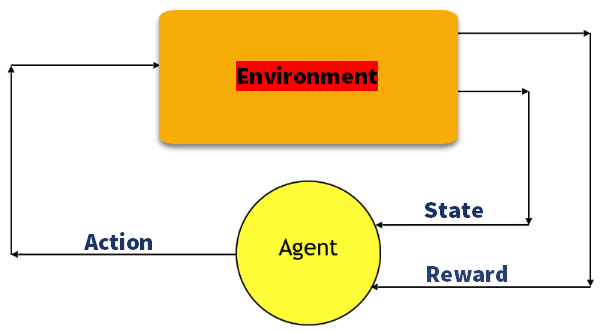
Q学習
Q学習は、エージェントが取るべきアクションを知らせるための情報を提供する値ベースの方法です。
次の例でこの方法を理解しましょう。
- 建物にはドアで結ばれた五つの部屋があります。
- 各部屋は0から4に番号が付けられています
- 建物の外側は一つの大きな外エリア(5)にすることができます
- ドア番号1と4ルーム5から建物:
- 目標に直接つながるドアは100の報酬を持っています
- ターゲットルームに直接接続されていないドアはゼロ報酬を与えます
- ドアは双方向であり、各部屋に二つの矢印が割り当てられています
- 上の画像のすべての矢印にはインスタント報酬値が含まれています
説明:
この画像では、部屋が状態を表していることを見ることができます
エージェントのある部屋から別の部屋への移動はアクションを表します
下の画像では、状態はノードとして記述され、矢印はアクションを示し

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. 教師あり学習
パラメータ
強化学習
教師あり学習
決定スタイル
強化学習は、あなたの決定を順番に取るのに役立
このメソッドでは、最初に指定された入力に対して決定が行われます。
は
で動作し、環境との対話に動作します。
は、例または指定されたサンプルデータで動作します。
決定への依存性
RLメソッドの学習決定に依存しています。 したがって、依存するすべての決定にラベルを付ける必要があります。
教師あり学習お互いに独立している意思決定なので、ラベルはすべての意思決定のために与えられています。
最も適した
人間の相互作用が普及しているAIでサポートし、より良い仕事をしています。
これは、主に対話型ソフトウェアシステムまたはアプリケーションで動作します。
例
チェスゲーム
物体認識
強化学習のアプリケーション
ここでは強化学習のアプリケーションがあります。
- 産業自動化のためのロボット。
- ビジネス戦略計画
- 機械学習とデータ処理
- それはあなたが学生の要件に応じてカスタム命令や材料を提供するトレーニングシステムを作成す
- 航空機制御とロボットの動作制御
なぜ強化学習を使用しますか?
強化学習を使用する主な理由は次のとおりです。
- どの状況がアクションを必要としているかを見つけるのに役立ちます
- どのアクショ
- 強化学習はまた、学習エージェントに報酬機能を提供します。
- また、大きな報酬を得るための最良の方法を見つけ出すこともできます。
強化学習を使用しない場合は?あなたは強化学習モデルを適用することはできませんが、すべての状況です。
あなたは、強化学習モデルを適用することはできません。 ここでは、強化学習モデルを使用すべきではないいくつかの条件があります。 教師あり学習法で問題を解決するのに十分なデータがある場合
- 強化学習は計算が重く時間がかかることを覚えておく必要があります。 特に、アクションスペースが大きい場合。
強化学習の課題
ここでは、強化収益をやっている間に直面する主要な課題があります:
- 非常に関与する必要があります機能/報酬の設計
- パラメータは、学習の速度に影響を与える可能性があります。
- 現実的な環境では、部分的な可観測性を持つことができます。
- あまりにも多くの強化は、結果を減少させることができる状態の過負荷につながる可能性があります。
- 現実的な環境は非定常である可能性があります。 強化学習は機械学習方法です。
- どのアクションがより長い期間にわたって最高の報酬をもたらすかを発見するのに役立ちます。
- あなたの猫は環境にさらされているエージェントです。 この場合、それはあなたの家です。 状態の例は、あなたの猫が座っている可能性があり、あなたは歩くために猫のために特定の単語を使用します。
- 私たちのエージェントは、ある”状態”から別の”状態”へのアクション遷移を実行することによって反応します。”
- たとえば、あなたの猫は座ってから歩くようになります。
- エージェントの反応はアクションであり、ポリシーは、より良い結果を期待して状態を与えられたアクションを選択する方法です。
- 移行後、彼らは見返りに報酬やペナルティを得ることができます。
強化学習アルゴリズム
強化学習アルゴリズムを実装するには三つのアプローチがあります。 値ベースの強化学習法では、値関数V(s)を最大化しようとする必要があります。
値ベースの強化学習法では、値関数V(s)を最大化する必要があります。
値ベースの強化学習法では、値関数V(s)を最大 この方法では、エージェントは、ポリシーの下で現在の状態の長期的なリターンを期待していますか?.
Policy-based:
Policy-based rlメソッドでは、すべての状態で実行されるアクションが将来最大の報酬を得るのに役立つようなポリシーを思い出そうとします。
ポリシーベースの方法の二つのタイプは次のとおりです。
- 決定論的:任意の状態のために、同じアクションがポリシーによって生成されますか?.
- 確率的:すべてのアクションは、次の式によって決定される一定の確率を持っています。確率的ポリシー:
n{a\s) = P\A, = a\S, =S]
モデルベース: この強化学習法では、環境ごとに仮想モデルを作成する必要があります。 エージェントは、その特定の環境で実行することを学習します。
強化学習の特性
ここでは強化学習の重要な特性があります
- 何のスーパーバイザ、唯一の実数または報酬信号はありません
- シーケンシャルp>強化学習方法の二種類は次のとおりです。
正:
これは、特定の動作のために発生するイベントとして定義されています。 それは行動の強さそして頻度を高め、代理店によって取られる行為で肯定的に影響を与える。 このタイプの補強は、パフォーマンスを最大化し、より長期間にわたって変化を維持するのに役立ちます。
しかし、あまりにも多くの強化は、結果に影響を与える可能性があり、状態の過剰最適化につながる可能性があります。
負:
負の強化は、停止または回避する必要がある負の状態のために発生する行動の強化として定義されます。
負の強化は、負の強化と定義されています。
負の強化 それは性能の最低の立場を定義するのを助ける。 しかし、この方法の欠点は、最小の動作を満たすのに十分なものを提供することです。
強化の学習モデル
強化学習には二つの重要な学習モデルがあります。
- マルコフ決定プロセス
- Q学習
マルコフ決定プロセス
以下のパラメータは、解を得るために使用されます。:
- アクションのセット-a
- 状態のセット-S
- 報酬-R
- ポリシー-n
- 値-V
強化学習における解をマッピングするための数学的アプローチは、マルコフ決定プロセスまたは(MDP)として偵察される。
Q学習
Q学習は、エージェントが取るべきアクションを知らせるための情報を提供する値ベースの方法です。
次の例でこの方法を理解しましょう。
- 建物にはドアで結ばれた五つの部屋があります。
- 各部屋は0から4に番号が付けられています
- 建物の外側は一つの大きな外エリア(5)にすることができます
- ドア番号1と4ルーム5から建物:
- 目標に直接つながるドアは100の報酬を持っています
- ターゲットルームに直接接続されていないドアはゼロ報酬を与えます
- ドアは双方向であり、各部屋に二つの矢印が割り当てられています
- 上の画像のすべての矢印にはインスタント報酬値が含まれています
説明:
この画像では、部屋が状態を表していることを見ることができます
エージェントのある部屋から別の部屋への移動はアクションを表します
下の画像では、状態はノードとして記述され、矢印はアクションを示し
For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. 教師あり学習
パラメータ 強化学習 教師あり学習 決定スタイル 強化学習は、あなたの決定を順番に取るのに役立 このメソッドでは、最初に指定された入力に対して決定が行われます。 は で動作し、環境との対話に動作します。 は、例または指定されたサンプルデータで動作します。 決定への依存性 RLメソッドの学習決定に依存しています。 したがって、依存するすべての決定にラベルを付ける必要があります。 教師あり学習お互いに独立している意思決定なので、ラベルはすべての意思決定のために与えられています。 最も適した 人間の相互作用が普及しているAIでサポートし、より良い仕事をしています。 これは、主に対話型ソフトウェアシステムまたはアプリケーションで動作します。 例 チェスゲーム 物体認識 強化学習のアプリケーション
ここでは強化学習のアプリケーションがあります。
- 産業自動化のためのロボット。
- ビジネス戦略計画
- 機械学習とデータ処理
- それはあなたが学生の要件に応じてカスタム命令や材料を提供するトレーニングシステムを作成す
- 航空機制御とロボットの動作制御
なぜ強化学習を使用しますか?
強化学習を使用する主な理由は次のとおりです。
- どの状況がアクションを必要としているかを見つけるのに役立ちます
- どのアクショ
- 強化学習はまた、学習エージェントに報酬機能を提供します。
- また、大きな報酬を得るための最良の方法を見つけ出すこともできます。
強化学習を使用しない場合は?あなたは強化学習モデルを適用することはできませんが、すべての状況です。
あなたは、強化学習モデルを適用することはできません。 ここでは、強化学習モデルを使用すべきではないいくつかの条件があります。 教師あり学習法で問題を解決するのに十分なデータがある場合
- 強化学習は計算が重く時間がかかることを覚えておく必要があります。 特に、アクションスペースが大きい場合。
強化学習の課題
ここでは、強化収益をやっている間に直面する主要な課題があります:
- 非常に関与する必要があります機能/報酬の設計
- パラメータは、学習の速度に影響を与える可能性があります。
- 現実的な環境では、部分的な可観測性を持つことができます。
- あまりにも多くの強化は、結果を減少させることができる状態の過負荷につながる可能性があります。
- 現実的な環境は非定常である可能性があります。 強化学習は機械学習方法です。
- どのアクションがより長い期間にわたって最高の報酬をもたらすかを発見するのに役立ちます。
- 強化学習のための三つの方法は、1)価値ベース2)政策ベースとモデルベースの学習です。
- エージェント、状態、報酬、環境、環境の値関数モデル、モデルベースの方法は、RL学習法で使用していくつかの重要な用語です
- 強化学習の例は、あなたの猫
- この方法の最大の特徴は、スーパーバイザがなく、実数または報酬信号のみであることです
- 強化学習の二つのタイプは、1)正2)負
- 広く使用されている二つの学習モデルは、1)マルコフ決定プロセス2)Q学習
- 強化学習法は環境との相互作用に作用し、教師あり学習法は与えられたサンプルデータまたは例に作用する。
- アプリケーションまたは強化学習方法は次のとおりです: 産業自動化とビジネス戦略計画のためのロボット
- あなたが問題を解決するのに十分なデータを持っているときは、この方法を使用しないでくださ