Last Updated on February17,2021
機械学習の観点からの予測は、その予測の不確実性を隠す単一の点です。
予測間隔は、予測の不確実性を定量化して伝達する方法を提供します。 それらは、代わりに平均値や標準偏差などの母集団パラメータの不確実性を定量化しようとする信頼区間とは異なります。 予測区間は、単一の特定の結果の不確実性を記述します。このチュートリアルでは、予測区間と、単純な線形回帰モデルの予測区間の計算方法について説明します。
このチュートリアルでは、単純な線形回帰モデ
このチュートリアルを完了すると、次のことがわかります。
- 予測区間は、単一点予測の不確実性を定量化します。
- 予測区間は、単一点予測の不確実性を定量化します。
- 予測間隔は単純なモデルでは解析的に推定できますが、非線形機械学習モデルではより困難です。
- 単純な線形回帰モデルの予測間隔を計算する方法。私の新しい本Statistics for Machine Learningで、ステップバイステップのチュートリアルやすべての例のPythonソースコードファイルを含めて、プロジェクトを開始します。
始めましょう。
- 2019年6月更新:有意水準を標準偏差の一部として修正しました。
- 更新Apr/2020:予測区間のプロットに誤字を修正しました。

機械学習のための予測間隔
Jim Bendonによる写真、some rights reserved。チュートリアルの概要
このチュートリアルは5つの部分に分かれています。
- ポイント推定の問題は何ですか?
- 予測区間とは何ですか?
- 予測間隔を計算する方法
- 線形回帰の予測間隔
- 働いた例
機械学習のための統計情報の助けが必要ですか?
今私の無料の7日間の電子メールクラッシュコースを取る(サンプルコード付き)。
クリックしてサインアップし、コースの無料のPDF電子ブック版を取得します。
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
1yhat = model.predict(X)ここで、yhatは、指定された入力データXに対して訓練されたモデルによって行われた推定結果または予測です。
これは点定義上、これは推定値または近似値であり、いくつかの不確実性が含まれています。
定義上、これは推定値または近似値です。
不確実性は、モデル自体の誤差と入力データのノイズに起因します。 このモデルは、入力変数と出力変数の間の関係の近似値です。
モデルを選択して調整するために使用されるプロセスを考えると、利用可能な情報を与えられた最良の近似になりますが、それでもエラーが発生します。
モデルを選択して調整するには、 ドメインからのデータは、入力変数と出力変数の間の基礎となる関係と未知の関係を自然にあいまいにします。 これにより、モデルを適合させることが困難になり、適合モデルが予測を行うことも困難になります。
これら二つの主な誤差源を考えると、予測モデルからのそれらの点予測は、予測の真の不確実性を記述するには不十分である。
予測区間とは何ですか?
予測区間は、予測の不確実性を定量化したものです。
予測区間は、予測の不確実性の定量化です。
結果変数の推定値の確率的上限と下限を提供します。
単一の将来の観測値の予測区間は、指定された信頼度で、分布からランダムに選択された将来の観測値を含む区間です。
—ページ27、統計的間隔:実務家と研究者のためのガイド、2017。予測区間は、数量が予測される回帰モデルを使用して予測または予測を行うときに最も一般的に使用されます。
予測区間は、数量が予測されてい
予測区間の提示の例は次のとおりです。
‘x’が与えられた’y’の予測が与えられた場合、’a’から’b’の範囲が真の結果をカバーする95%の尤度が
予測間隔は、モデルによって行われた予測を囲み、うまくいけば、真の結果の範囲をカバーします。
以下の図は、予測、予測間隔、および実際の結果の関係を視覚的に理解するのに役立ちます。
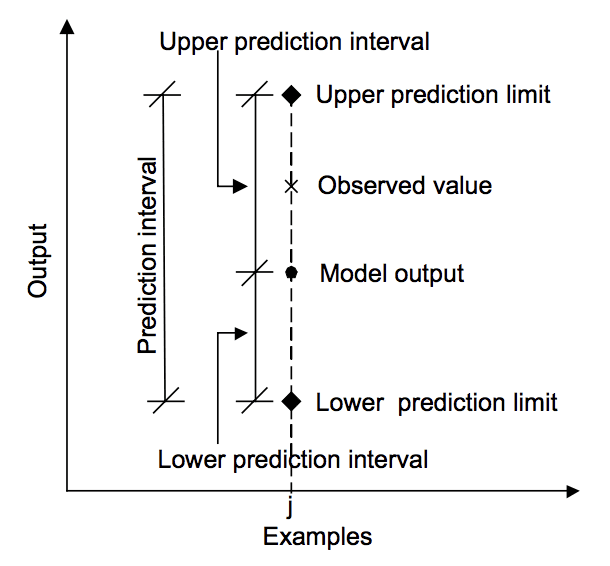
予測、実際の値と予測間隔の関係。
“モデル出力の予測間隔の推定のための機械学習アプローチ”、2006年から取られた。予測区間は信頼区間とは異なります。
信頼区間は、平均値や標準偏差などの推定母集団変数の不確実性を定量化します。
信頼区間は、推定母集団変数の不確実性を定量化します。 一方、予測区間は、母集団から推定された単一の観測値の不確実性を定量化します。
予測モデリングでは、信頼区間を使用してモデルの推定スキルの不確実性を定量化することができますが、予測区間を使用して単一の予測の不
予測区間は、信頼区間と予測される出力変数の分散を考慮する必要があるため、多くの場合、信頼区間よりも大きくなります。
予測区間は、信頼区間と、予測される出力変数の分散を考慮しなければなりません。P>
既約誤差であるeに関連する不確実性を考慮しているため、予測区間は常に信頼区間よりも広くなります。p>
—ページ103、統計学習の紹介:R、2013年のアプリケーションで。
予測間隔の計算方法
予測間隔は、モデルの推定分散と結果変数の分散のいくつかの組み合わせとして計算されます。
予測区間は記述するのは簡単ですが、実際には計算するのは困難です。
線形回帰のような単純なケースでは、予測区間を直接推定することができます。
人工ニューラルネットワークなどの非線形回帰アルゴリズムの場合、それははるかに困難であり、特殊な技術の選択と実装が必要です。 ブートストラップリサンプリング法などの一般的な手法を使用できますが、計算には計算コストがかかります。
論文”ニューラルネットワークベースの予測間隔と新しい進歩の包括的なレビュー”は、ニューラルネットワークの文脈における非線形モデルの予測間隔の合理的 次のリストは、非線形機械学習モデルの予測不確実性に使用できるいくつかの方法をまとめたものです。
- 非線形回帰の分野からのデルタ法。
- ベイズモデリングと統計からベイズ法、。
- 推定統計を使用した平均分散推定方法。
- データのリサンプリングとモデルのアンサンブルの開発を使用したブートストラップメソッド。
次のセクションで作業した例で、予測間隔の計算を具体的にすることができます。
線形回帰の予測区間
線形回帰は、出力変数を計算するための入力の線形結合を記述するモデルです。
For example, an estimated linear regression model may be written as:
1yhat = b0 + b1 . xWhere yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.係数b0とb1の真の値はわかりません。
係数b0とb1の真の値はわかりません。
これらの要素はすべて推定されなければならず、予測を行うためにモデルの使用に不確実性を導入する必要があります。xとyの分布や、残差と呼ばれるモデルによって行われた予測誤差がガウス分布であるなど、いくつかの仮定を行うことができます。
残差と呼ばれ
yhatの周りの予測区間は、次のように計算できます。
:
1yhat +/- z * sigmaWhere yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.私たちは、実際には知られていません。
予測された標準偏差の不偏推定値を次のように計算することができます(モデル出力の予測間隔の推定のための機械学習アプローチから取られます)。:
1stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
作業例
作業例で線形回帰予測区間のケースを具体的にしましょう。
まず、出力変数(y)がガウスノイズを持つ入力変数(x)に依存する単純な2変数データセットを定義しましょう。
以下の例では、この例で使用するデータセットを定義しています。
23456789101112131415161718191919191919191919191911121314151617std from numpy.random import randnfrom numpy.random import seedfrom matplotlib import pyplot# seed random number generatorseed(1)# prepare datax = 20 * randn(1000) + 100y = x + (10 * randn(1000) + 50)# summarizeprint(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))# plotpyplot.scatter(x, y)pyplot.show()Running the example first prints the mean and standard deviations of the two variables.
12x: mean=100.776 stdv=19.620y: mean=151.050 stdv=22.358データセットのプロットが作成されます。
私たちは、関係のノイズやランダムエラーを強調する点の広がりと変数間の明確な線形関係を見ることができます。
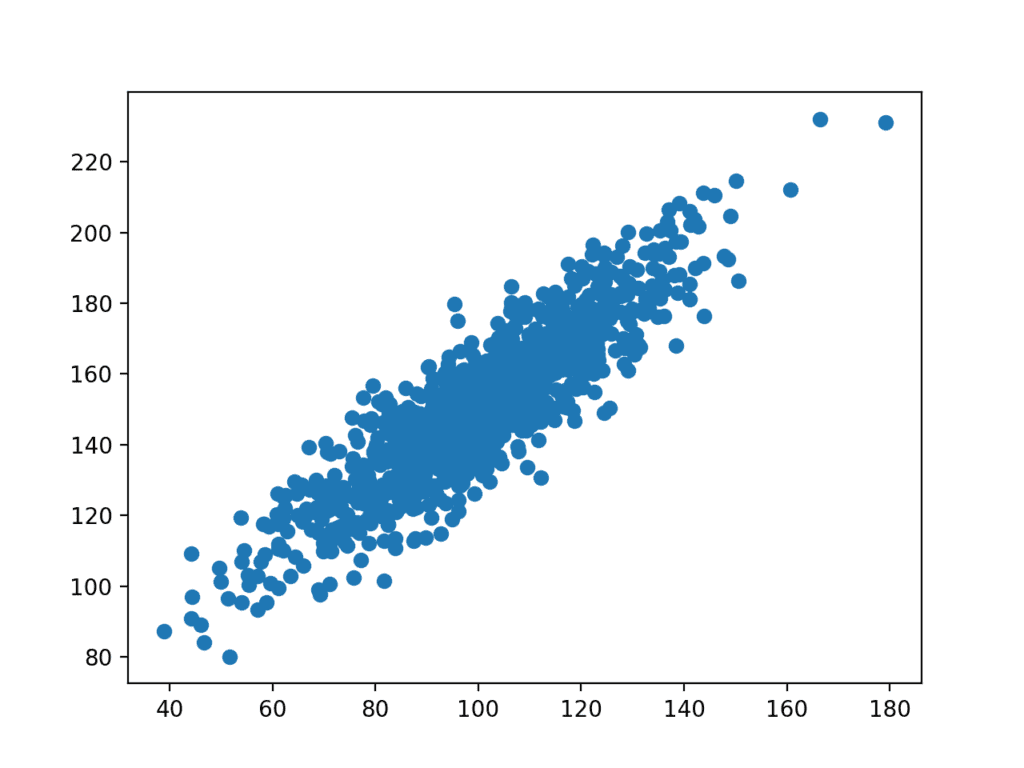
関連変数の散布図
次に、入力変数xが与えられた単純な線形回帰を開発し、y変数を予測 Linregress()SciPy関数を使用してモデルを近似し、モデルのb0係数とb1係数を返すことができます。
12# fit linear regression modelb1, b0, r_value, p_value, std_err = linregress(x, y)We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
12# make predictionyhat = b0 + b1 * xThe complete example is listed below.
234567891011121314151617181919191919191919191919111213141516171819#単純な非線形回帰モデル からnumpy。random import randn from numpy.random import seedfrom scipy.stats import linregressfrom matplotlib import pyplot# seed random number generatorseed(1)# prepare datax = 20 * randn(1000) + 100y = x + (10 * randn(1000) + 50)# fit linear regression modelb1, b0, r_value, p_value, std_err = linregress(x, y)print(‘b0=%.3f, b1=%.3f’ % (b1, b0))# make predictionyhat = b0 + b1 * x# plot data and predictionspyplot.scatter(x, y)pyplot.plot(x, yhat, color=’r’)pyplot.show()Running the example fits the model and prints the coefficients.
係数は、予測を行うためにデータセットからの入力と一緒に使用されます。 結果の入力と予測されたy値は、データセットの散布図の上に線としてプロットされます。
モデルがデータセット内の基礎となる関係を学習したことがはっきりとわかります。
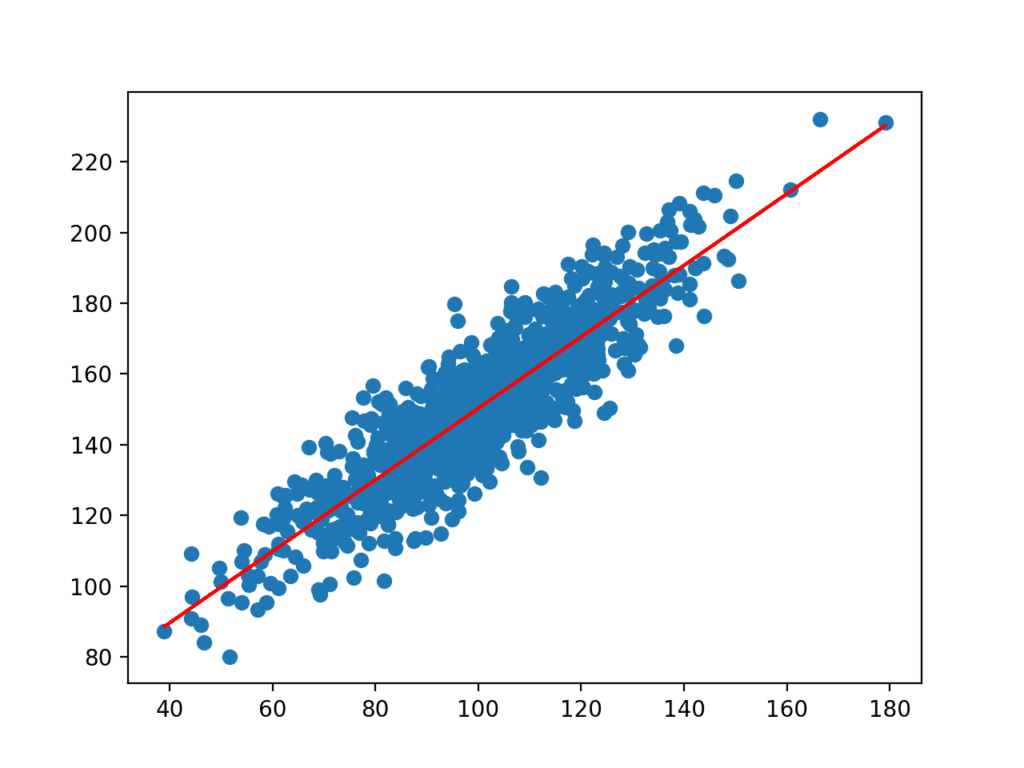
単純な線形回帰モデルのための線とデータセットの散布図
私たちは今、私たちの単純な線形回帰モデルで予測を行い、予測区間を追加する準備ができています。
以前と同じようにモデルを適合させます。 今回は、予測間隔を示すために、データセットから一つのサンプルを取ります。 入力を使用して予測を作成し、予測の予測間隔を計算し、予測と間隔を既知の期待値と比較します。
まず、入力、予測、および期待値を定義しましょう。
yhat_out=yhat 次に、予測方向の標準曲率を推定することができます。
1SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)We can calculate this directly using the NumPy arrays as follows:
123# estimate stdev of yhatsum_errs = arraysum((y – yhat)**2)stdev = sqrt(1/(len(y)-2) * sum_errs)Next, we can calculate the prediction interval for our chosen input:
1interval = z . stdevWe will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
123# calculate prediction intervalinterval = 1.96 * stdevlower, upper = yhat_out – interval, yhat_out + intervalWe can tie all of this together. The complete example is listed below.
23456789101112131415161718191919191919191919191911121314151617181920212223242526272829292929292929292929295262728293031323334353637# linear regression prediction with prediction intervalfrom numpy.random import randnfrom numpy.random import seedfrom numpy import powerfrom numpy import sqrtfrom numpy import meanfrom numpy import stdfrom numpy import sum as arraysumfrom scipy.統計import linregressfrom matplotlib import pyplot#シード乱数ジェネレータseed(1)#データを準備するx=20*randn(1000)+100y=x+(10*randn(1000)+50)#非線形回帰モデルを近似する#b1,b0,r_value,p_value,std_err=linregress(x,y)#予測をマークyhat=b0+b1*x#新しい入力、期待値、予測を定義x_in=xy_out=yyhat_out=yhat#yhatのstdevを推定#yhatのstdevを推定#yhatのstdevを推定#yhatのstdevを推定#yhatのstdevを推定#yhatのstdevを推定#yhatのstdevを推定#yhatのstdevを推定/div>==========================================#################3f’%interval)lower,upper=yhat_out-interval,yhat_out+intervalprint(‘95%%真の値が%の間にある可能性があります。3fと%。3f’%(lower,upper))print(‘真の値:%.3f’%y_out)#間隔でデータセットと予測をプロットpyplot。scatter(x,y)pyplot.plot(x,yhat,color=’red’)pyplot.errorbar(x_in,yhat_out,yerr=interval,color=’black’,fmt=’o’)pyplot.show()この例を実行すると、yhat標準偏差が推定され、予測間隔が計算されます。
計算されると、指定された入力変数の予測間隔がユーザーに提示されます。
計算されると、予測間隔がユーザーに提示されます。 私たちはこの例を考案したので、私たちはまた、表示される真の結果を知っています。 この場合、95%の予測間隔が真の期待値をカバーしていることがわかります。
123Prediction Interval: 20.20495% likelihood that the true value is between 160.750 and 201.159True value: 183.124生のデータセットを散布図として、データセットの予測を赤い線として、予測と予測間隔をそれぞれ黒い点と線として
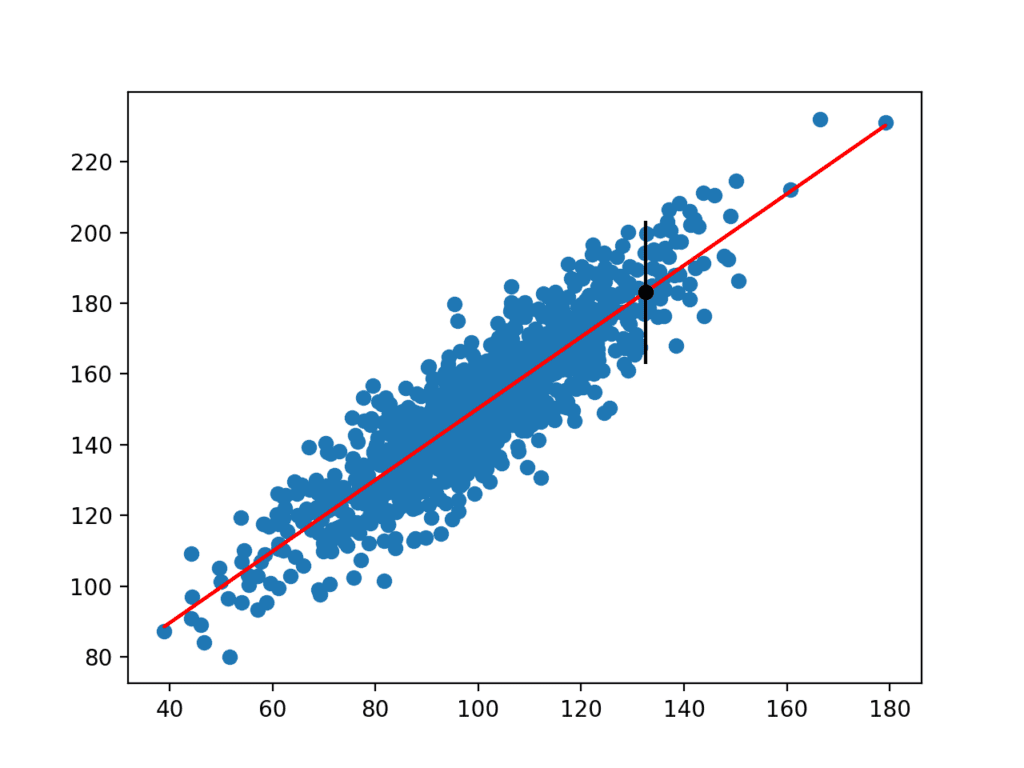
線形モデルと予測区間を持つデータセットの散布図
拡張
このセクションでは、チュートリアルを拡張するためのいくつかのアイデアを示しています。
- 許容誤差、信頼区間、および予測区間の差を要約します。
- 標準の機械学習データセットの線形回帰モデルを開発し、小さなテストセットの予測間隔を計算します。
- 一つの非線形予測区間法がどのように機能するかを詳細に説明します。これらの拡張機能のいずれかを探索する場合、私は知りたいと思います。
さらに読む
このセクションでは、より深く行くために探している場合は、トピックに関するより多くのリソースを提供します。
Posts
- 信頼区間を使用して分類器のパフォーマンスを報告する方法
- Pythonで機械学習結果のブートストラップ信頼区間を計算する方法
- Pythonで信頼区間を使用して時系列予測の不確実性を理解する
- 確率的機械学習アルゴリズムの実験繰り返し数を推定する
Books
- 新しい統計を理解する:効果サイズ、信頼区間、メタ分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析、統計分析2017年。統計的間隔:実務家と研究者のためのガイド、2017。
- 統計的間隔:実務家と研究者のためのガイド、2017。
- 統計学習の紹介:R、2013年のアプリケーションで。
- 新しい統計の紹介:推定、オープンサイエンス、およびそれ以降、2016。
- 予測:原則と実践、2013。
論文
- ニューラルネットワークモデルのいくつかの誤差推定値の比較、1995。
- モデル出力の予測間隔の推定のための機械学習アプローチ,2006.
- ニューラルネットワークベースの予測間隔と新しい進歩の包括的なレビュー、2010。
API
- scipy。統計。linregress()API
- matplotlib。ピプロットscatter()API
- matplotlib。ピプロットerrorbar()API
Articles
- Wikipediaの予測間隔
- クロス検証のブートストラップ予測間隔
概要
このチュートリアルでは、単純な線形回帰モデルの予測間隔とそれを計算する方法を発見しました。具体的には、次のことを学びました。
- 予測区間は、単一点予測の不確実性を定量化します。
- 予測区間は、単一点予測の不確実性を定量化します。
- 予測間隔は単純なモデルでは解析的に推定できますが、非線形機械学習モデルではより困難です。
- 単純な線形回帰モデルの予測間隔を計算する方法。
何か質問がありますか?
質問がありますか?
以下のコメントであなたの質問をすると、私は答えるために最善を尽くします。機械学習のための統計のハンドルを取得します!

統計の実用的な理解を開発
。..pythonでコード行を書くことによって
私の新しい電子ブックでどのように発見:
機械学習のための統計的方法それはのようなトピックに関する自..
データを知識に変換する方法を発見
学者をスキップします。 ちょうど結果。
- 予測区間は、単一点予測の不確実性を定量化します。