VMware High Availability(HA)は、仮想化環境で専用のスタンバイハードウェアとソフトウェアを不要にす VMware HAは、信頼性の向上、仮想環境でのダウンタイムの短縮、および災害復旧/ビジネス継続性の向上によく使用されます。
Vcp4試験塾からのこの章の抜粋:VMware Certified Professional、Elias Khnaserによる第2版は、VMware HAのベストプラクティスを探ります。VMwareの高可用性は、主にESX/ESXiホストの障害と、このホストで実行されている仮想マシンVmに何が起こるかを処理します。
VMwareの高可用性は、主にESX/ESXiホス HAでは、VMware Toolsがまだ実行されているかどうかを確認することで、VMを監視および再起動することもできます。 ESX/ESXiホストに何らかの理由で障害が発生すると、実行中のすべてのVmも障害が発生します。 VMware HAは、障害が発生したホストからのVmが他のESX/ESXiホストで再起動できるようにします。多くの人が誤ってvmware HAをフォールトトレランスと混同しています。 VMware HAは、ホストに障害が発生した場合、そのホスト上のVmにも障害が発生するという点でフォールトトレラントではありません。 HAは、十分なリソースを持つ他のESX/ESXiホスト上のこれらのVmの再起動のみを処理します。 一方、フォールトトレランスは、ホスト障害が発生した場合にリソースへの無停電アクセスを提供します。
 上記のブックカバー画像をクリックして、Elias Khnaserの章全体をダウンロードしてください。
上記のブックカバー画像をクリックして、Elias Khnaserの章全体をダウンロードしてください。バックアップと高可用性に関する。VMware HAは、vSphere4.0では1秒ごと、vSphere4.1では10秒ごとに送信するハートビートを使用して、同じクラスタのメンバーである他のすべてのESX/ESXiホストとの通信チャネ ESXサーバーがハートビートを逃した場合、他のホストは他のホストが再び応答するのを15秒待ちます。 15秒後、クラスターは、クラスター内の残りのESX/ESXiホスト上の障害が発生したESX/ESXiホスト上のVmの再起動を開始します。 また、VMware HAは、クラスタのメンバーであるESX/ESXiホストを常に監視し、ホストに障害が発生した場合に要件を満たすためにリソースが常に使用可能であるこ
仮想マシンの障害監視
仮想マシンの障害監視は、デフォルトで無効になっているテクノロジです。 その機能は、ハートビートを介して20秒ごとにクエリする仮想マシンを監視することです。 これは、VM内にインストールされているVMwareツールを使用して行います。 Vmがハートビートを逃した場合、VMware HAはこのVMを失敗したとみなし、リセットを試みます。 仮想マシンの障害監視は、仮想マシンの高可用性のようなものと考えてください。
仮想マシンの障害監視では、仮想マシンが手動でパワーオフ、一時停止、または移行されたかどうかを検出でき、再起動を試行しません。
VMware HA構成の前提条件
HAが正常に機能するには、次の構成の前提条件が必要です。
- vCenter:VMware HAはエンタープライズクラスの機能であるたDNS解決:HAクラスタのメンバーであるすべてのESX/ESXiホストは、DNSを使用して相互に解決できる必要があります。
- 共有ストレージへのアクセス:HAクラスター内のすべてのホストは、同じ共有ストレージへのアクセスと可視性を持っている必要があります。
- 同じネットワークへのアクセス: すべてのESX/ESXiホストには、すべてのホストで同じネットワークが構成されている必要があるため、VMが任意のホストで再起動されたときに、正しいネッ
サービスコンソールの冗長性
推奨されるプラクティスでは、サービスコンソール(SC)に冗長性があることが示されています。 VMware HAは、サービスコンソールが1つのvmnicのみを持つvSwitchで構成されていることを検出した場合、警告を表示して発行します。 図1に示すように、サービスコンソールの冗長性は、次の2つの方法のいずれかで構成できます。
- 2つのサービスコンソールポートグループを作成します。
- NICチームの形式で2つの物理ネットワークインターフェースカード(Nic)をサービスコンソールvSwitchに割り当てます。
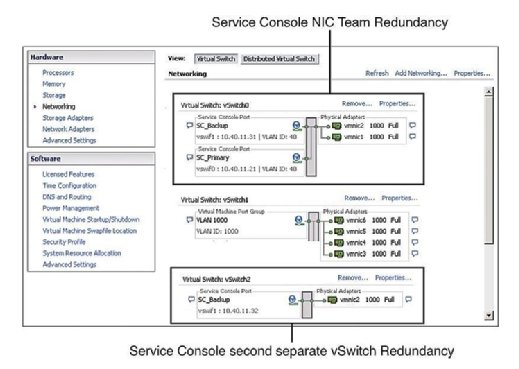
どちらの場合も、IPアドレス、サブネット、およびゲートウェイでIPスタック全体を構成する必要があります。 サービスコンソールのvSwitchは、ハートビートと状態の同期に使用され、次のポートを使用します:
- 着信TCPポート8042
- 着信UDPポート8045
- 発信TCPポート2050
- 発信UDPポート2250
- 着信TCPポート8042-8045
- 着信UDPポート8042-8045
- 発信TCPポート2050-2250
- 発信udpポート2050-2250sc冗長性の設定に失敗すると、haを有効にすると警告メッセージが表示されます。 したがって、このエラーメッセージが表示されないようにし、ベストプラクティスを遵守するには、SCを冗長に設定します。HAを構成する場合は、ホスト障害許容度の最大値を手動で構成する必要があります。 これは、展開のハードウェアのサイジングと計画段階で慎重に検討する必要があるタスクです。 これは、HAに対応できるように計画されているよりも多くのVmを実行するのに十分なリソースを使用してESX/ESXiホストを構築したことを前提としてい たとえば、図2では、HAクラスターには4つのESXホストがあり、これらの4つのホストすべてに、少なくとも3つ以上のVmを実行するのに十分な容量があ これらはすべてすでに3つのVmを実行しているため、残りの2つのESX/ESXiホストは障害が発生しても問題なく6つの障害が発生したVmをパワーオンで
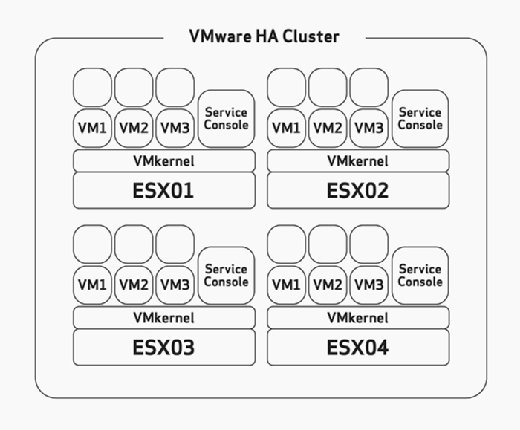
図2。 HA容量計画 HAクラスターの構成フェーズでは、図3に示すような画面が表示され、次のように2つのクラスター全体の構成を定義するよ:
- Host Monitoring Status:
- Enable Host Monitoring:この設定を使用すると、HAクラスターがハートビートのホストを監視するかどうかを制御できます。 これは、ホストがまだアクティブであるかどうかを判断するクラスターの方法です。 場合によっては、ESX/ESXiホストでメンテナンスタスクを実行しているときに、ホストの分離を回避するためにこのオプションを無効にすることが望
- アドミッションコントロール:
- 有効:可用性の制約に違反するVmの電源をオンにしないでください: このオプションを選択すると、VMを満たすために使用できるリソースがない場合は、電源をオンにしないことが示されます。
- Disable:可用性の制約に違反するVmのパワーオン:このオプションを選択すると、リソースをオーバーコミットする必要がある場合でも、VMのパワーオンが必要
- アドミッションコントロールポリシー:
- ホスト障害クラスター許容:この設定を使用すると、許容するホスト障害の数を構成できます。 許可される設定は1~4です。
- フェールオーバーの予備容量として予約されているクラスタリソースの割合: このオプションを選択すると、フェールオーバー用に予備のクラスタリソースの合計の割合が予約されます。 4つのホストクラスターでは、25%の予約は、フェールオーバーのために完全なホストを確保していることを示します。 より少ない量を確保したい場合は、代わりにクラスターリソースの10%を選択できます。
- フェールオーバホストの指定:このオプションを選択すると、クラスタ内のフェールオーバホストとして特定のホストを選択していることを示します。 これは、予備のホストがある場合、または使用可能な計算リソースとメモリリソースが大幅に多い特定のホストがある場合に当てはまります。
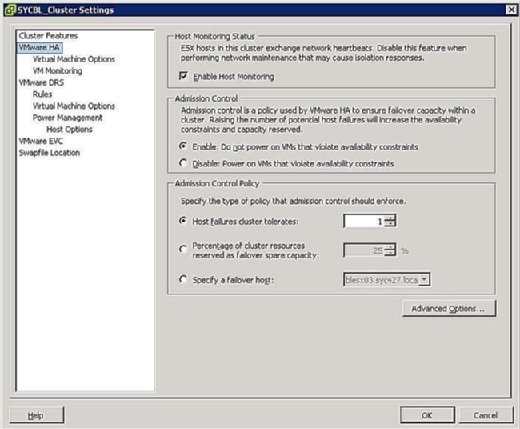
図3。 HAクラスター全体のポリシー ホストの分離
ESX/ESXiホストがクラスタの残りの部分からハートビートの受信を停止したときに、スプリッ ハートビートは、vSphere4.0では1秒ごと、vSphere4.1では10秒ごとに照会されます。 応答が受信されない場合、クラスタはESX/ESXiホストに障害が発生したと判断します。 これが発生すると、ESX/ESXiホストは管理インターフェイス上のネットワーク接続を失いました。 ホストはまだ稼働している可能性があり、影響を受けていない別のネットワークインターフェイスを使用している可能性を考慮すると、Vmは影響を受け ただし、ホストに障害が発生したと考えられているため、vSphereはこの問題が発生した場合に対処する必要があります。 そのことについては、ホスト分離応答が作成されました。 ホスト分離応答は、ネットワーク接続が失われたESX/ESXiホストを処理するHAの方法です。ホストの分離が発生した場合にVmに何が起こるかを制御できます。 VM Isolation Response画面に移動するには、問題のクラスターを右クリックし、Edit Settingsをクリックします。 次に、左側のペインのVMware HAバナーの下にある仮想マシンオプションをクリックします。 それに応じてhost isolation responseオプションを設定することで、クラスタ全体のオプションを制御できます。 これは、影響を受けるホスト上のすべてのVmに適用されます。 そうは言っても、VMレベルで異なる応答を定義することで、クラスター設定を常に上書きすることができます。
図4に示すように、分離応答オプションは次のとおりです。
- Leave Powered On:ラベルが示すように、この設定は、ホスト分離の場合、VMはパワーオンのままで
- 電源オフ:この設定は、分離の場合にVMの電源がオフになることを定義します。 これはハード電源オフです。
- シャットダウン:この設定は、分離が発生した場合に、VMware Toolsを使用してVMが正常にシャットダウンされることを定義します。 このタスクが5分以内に正常に完了しない場合は、すぐに電源オフが実行されます。 VMware Toolsがインストールされていない場合は、代わりに電源オフが実行されます。
- クラスター設定を使用する:この設定は、図4に示したウィンドウで定義されたクラスター全体の設定にタスクを転送します。
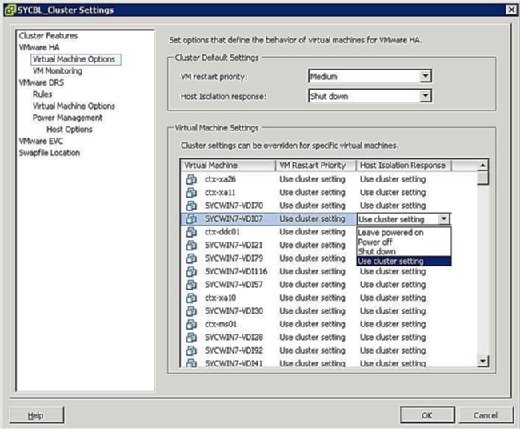
図4。 VM固有の分離ポリシー 分離の場合、これは必ずしもホストがダウンしていることを意味するものではありません。 Vmは異なる物理Nicで構成され、異なるネットワークに接続されている可能性があるため、正常に機能し続ける可能性があるため、分離の優先順位を設 ホストが分離されている場合、これは単に、そのサービスコンソールがクラスタ内の残りのESX/ESXiホストと通信できないことを意味します。
仮想マシンのリカバリ優先順位
障害が発生した場合にHAクラスターがすべてのVmに対応できない場合は、Vmに優先順位を付けることが 優先順位によって、どのVmが最初に再起動され、どのVmが緊急時にそれほど重要ではないかが決まります。 これらのオプションは、前のセクションで説明した分離応答と同じ画面で構成されます。 影響を受けるホスト上のすべてのVmに適用されるクラスター全体の設定を構成するか、VMレベルで上書きを構成してクラスター設定を上書きできます。VMの再起動優先度を次のいずれかに設定できます。
- High優先度の高いVmが最初に再起動されます。
- High優先度の高いVmが最初に再起動されます。
- High優先度の高いVmが最初に再
- Medium:これはデフォルトの設定です。
- Low:優先度の低いVmが最後に再起動されます。
- クラスター設定を使用する:次の図に示すウィンドウで定義されたクラスターレベルで定義された設定に基づいてVmが再起動されます。
- 無効:VMの電源がオンになりません。
優先度は、Vmの重要度に基づいて設定する必要があります。 つまり、ドメインコントローラーを再起動し、プリントサーバーを再起動しないようにすることができます。 優先度の高い仮想マシンが最初に再起動されます。 緊急時に電源オフのまま許容できるVMは、リソースを節約するために電源オフのままにするように構成する必要があります。
MSCS clustering
クラスターの主な目的は、重要なシステムがいつでもコストをかけずにオンラインに維持されるようにすることです。 クラスター化できる物理マシンと同様に、仮想マシンをESXでクラスター化することもできます。
- Cluster-in-a-box:このシナリオでは、クラスターの一部であるすべてのVmが同じESX/ESXiホスト上に存在します。 ご想像のとおり、これにより、すぐに単一障害点ESX/ESXiホストが作成されます。 共有記憶域に関しては、このシナリオでは仮想ディスクを共有記憶域として使用するか、仮想互換モードでRawデバイスマッピング(RDM)を使用できます。
- Cluster-across-boxes:このシナリオでは、クラスターノード(クラスターのメンバーであるVm)が複数のESX/ESXiホストに存在し、クラスターを構成する各ノードが同じストレージにア このシナリオでは、単一障害点を排除することにより、理想的なクラスター環境を作成します。 共有ストレージはこの前提条件であり、ファイバチャネルSAN上に存在する必要があります。 また、仮想ディスクは共有記憶域でサポートされている構成ではないため、物理互換モードまたは仮想互換モードでRDMを使用する必要があります。 これにより、クラスターを構成する各ノードは同じストレージにアクセスできるため、一方のVMに障害が発生した場合でも、他方のVMは引き続き機能し、同じデー
- 物理クラスターから仮想クラスターへ: このシナリオでは、クラスターの一方のメンバーが仮想マシンであり、他方のメンバーが物理マシンです。 このシナリオでは、共有記憶域が前提条件であり、物理互換モードのRDMとして構成する必要があります。クラスタリングソリューションを設計するときはいつでも、複数のホストまたはVmが同じデータにアクセスできるようにする共有ストレージの問題に対 vSphereには、次のように共有ストレージをプロビジョニングできるいくつかの方法があります。
- 仮想ディスク: 仮想ディスクを共有ストレージ領域として使用できるのは、ボックス内でクラスタリングを実行している場合、つまり、両方のVmが同じESX/ESXiホスト上にRDM in Physical Compatibility Mode:このモードでは、物理LUNをVMまたは物理マシンに直接接続できます。 このモードでは、スナップショットなどの機能を使用できないため、クラスターの一方のメンバーが物理マシンであり、他方のメンバーがVMである場合に仮想互換モードのRDM:このモードでは、物理LUNをVMまたは物理マシンに直接接続できます。 このモードでは、スナップショットや高度なファイルロックなど、VMFS上で実行されている仮想ディスクのすべての利点を提供します。 ディスクはハイパーバイザーを介してアクセスされ、両方のVmに共有ストレージへのアクセス権を付与する必要があるクラスター間シナリオを構成するこの記事の執筆時点では、VMwareでサポートされているクラスタリングサービスはMicrosoft Clustering Services(MSCS)のみです。 VMwareのホワイトペーパー”フェールオーバークラスタリングとMicrosoftクラスターサービスの設定”を参照してください。”
VMware Fault Tolerance
VMware Fault Tolerance(FT)は、極端な稼働時間を必要とするシステム用にVMwareによって開発されたVMクラスタリングの別の形式です。 FTの最も魅力的な機能の一つは、セットアップの容易さです。 FTは単に有効にできるチェックボックスです。 特定の構成および場合によってはケーブルで通信することを要求する従来の群がらせることと比較されて、FTは簡単強力である。それはどのように動作しますか?
FTでVmを保護する場合、保護されたVMのロックステップである最初のVMにセカンダリVMが作成されます。 FTは、最初のVMと2番目のVMに同時に書き込むことによって機能します。 すべてのタスクは二度書かれています。 最初のVMの[スタート]メニューをクリックすると、2番目のVMの[スタート]メニューもクリックされます。 FTの力は、両方のVmを同期させ続ける能力です。
保護されたVMが何らかの理由でダウンする必要がある場合、セカンダリVMはすぐにその場所を取り、idとIPアドレスを押収し、中断することなくユー 新しく昇格された保護されたVMは、別のホスト上に自分自身のセカンダリを作成し、サイクルを再起動します。明確にするために、例を見てみましょう。 Exchangeサーバーを保護する場合は、FTを有効にすることができます。 何らかの理由で保護されたVMを運ぶESX/ESXiホストに障害が発生した場合、セカンダリVMは起動し、サービスを中断することなくその任務を引き受けます。次の表は、vSphereでアクセスできるさまざまな高可用性およびクラスタリング技術の概要と、それぞれの制限事項を示しています。
次の表は、vSphereでア

フォールトトレランスの要件
フォールトトレランスは、テク これらの要件は、次のリストに概説されており、特定の最小要件を必要とするさまざまなカテゴリに分類されています。
- ホスト要件:
- FT-compatible CPU。 詳細については、このVMware KBの記事を確認してください。
- ハードウェア仮想化はbiosで有効にする必要があります。
- ホストのCPUクロック速度は、互いに400MHz以内でなければなりません。
- VMの要件:
- Vmは、サポートされている共有ストレージ(FC、iSCSI、およびNFS)上に存在する必要があります。
- VmはサポートされているOSを実行する必要があります。Vmは、VMDKまたは仮想RDMのいずれかに格納する必要があります。
- Vmはvmdkをシンプロビジョニングすることはできず、Eagerzeroedthick仮想ディスクを使用している必要があります。
- Vmに複数のvCPUを設定することはできません。
- クラスターの要件:すべてのESX/ESXiホストは、同じバージョンと同じパッチレベルである必要があります。すべてのESX/ESXiホストは、VMデータストアおよびネットワークにアクセスできる必要があります。クラスターでVMware HAを有効にする必要があります。
- 各ホストには、vMotionおよびFT Logging NICが構成されている必要があります。
- ホスト証明書のチェックも有効にする必要があります。FTとのプロセッサの互換性を確認することに加えて、VMware Hardware Compatibility List(HCL)に対してサーバーのメーカーとモデルの互換性をFTと確認することを強くお勧めします。
FTは優れたクラスタリングソリューションですが、特定の制限もあることに注意することが重要です。 たとえば、FT Vmはスナップショットできず、ストレージvmもスナップショットできません。 実際、これらのVmは自動的にDRS無効にフラグが設定され、動的なリソース負荷分散には参加しません。
FTを有効にする方法
FTを有効にすることは難しいことではありませんが、いくつかの異なる設定を構成する必要があります。 FTが機能するには、次の設定を適切に構成する必要があります。
- ホスト証明書チェックを有効にする: この設定を有効にするには、vCenter serverにログオンし、[ファイルFile]メニューから[管理Administration]をクリックし、[vCenter Server Settings]をクリックします。 左側のペインで、[SSL設定]をクリックし、[vCenterが検証済みホストSSL証明書を必要とする]ボックスをオンにします。
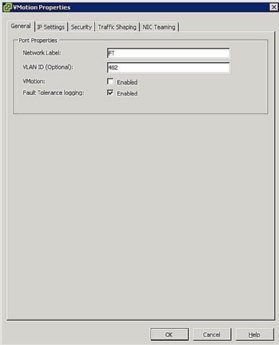
図5。 FTポートグループ設定 - ホストネットワークの設定: FTのネットワーク構成は簡単で、vMotionと同じ手順に従いますが、vMotionボックスをチェックする代わりに、図5に示すようにFault Tolerance Loggingボックスをチェックします。FTのオンとオフの切り替え:前述の要件を満たしたら、VmのFTのオンとオフを切り替えることができるようになりました。 保護するVMを見つけて右クリックし、Fault Toleranceを選択します。>Fault Toleranceをオンにします。
FTは第一世代のクラスタリング技術ですが、印象的にうまく機能し、クラスターの構築、構成、および保守の複雑すぎる従来の方法を簡素化します。 FTは、稼働時間の観点とシームレスなフェールオーバーの観点から優れた技術です。
- ホスト証明書チェックを有効にする: この設定を有効にするには、vCenter serverにログオンし、[ファイルFile]メニューから[管理Administration]をクリックし、[vCenter Server Settings]をクリックします。 左側のペインで、[SSL設定]をクリックし、[vCenterが検証済みホストSSL証明書を必要とする]ボックスをオンにします。
- 仮想ディスク: 仮想ディスクを共有ストレージ領域として使用できるのは、ボックス内でクラスタリングを実行している場合、つまり、両方のVmが同じESX/ESXiホスト上にRDM in Physical Compatibility Mode:このモードでは、物理LUNをVMまたは物理マシンに直接接続できます。 このモードでは、スナップショットなどの機能を使用できないため、クラスターの一方のメンバーが物理マシンであり、他方のメンバーがVMである場合に仮想互換モードのRDM:このモードでは、物理LUNをVMまたは物理マシンに直接接続できます。 このモードでは、スナップショットや高度なファイルロックなど、VMFS上で実行されている仮想ディスクのすべての利点を提供します。 ディスクはハイパーバイザーを介してアクセスされ、両方のVmに共有ストレージへのアクセス権を付与する必要があるクラスター間シナリオを構成するこの記事の執筆時点では、VMwareでサポートされているクラスタリングサービスはMicrosoft Clustering Services(MSCS)のみです。 VMwareのホワイトペーパー”フェールオーバークラスタリングとMicrosoftクラスターサービスの設定”を参照してください。”
- High優先度の高いVmが最初に再起動されます。