こんにちは、長い短期記憶(LSTM)とゲーテッこんにちこんにちこんにちこんにちこんにちこんにちこんにちこんにちこんにちこんにちこんにちこんにちこんにちはgru)。 私はマイケルで、AI音声アシスタントスペースの機械学習エンジニアです。この記事では、LSTMとGRUの背後にある直感から始めて、LSTMとGRUがうまく機能するようにする内部メカニズムについて説明します。 これらの2つのネットワークのボンネットの下で何が起こっているのかを理解したい場合は、この投稿はあなたのためです。
ご希望の場合は、この投稿のビデオ版をyoutubeで見ることもできます。
ご希望の場合は、この投稿のビデオ版をご覧ください。
リカレントニューラルネットワークは、短期記憶に苦しみます。 シーケンスが十分に長い場合、以前のタイムステップから後のタイムステップへの情報を運ぶのに苦労します。 したがって、予測を行うためにテキストの段落を処理しようとしている場合、RNNは最初から重要な情報を省略する可能性があります。
逆伝播中に、リカレントニューラルネットワークは消失勾配問題に苦しんでいます。 勾配は、ニューラルネットワークの重みを更新するために使用される値です。 消失勾配の問題は、勾配が時間を経て伝播するにつれて勾配が縮小するときです。 勾配値が非常に小さくなっても、学習にあまり寄与しません。Div>

だから、リカレントニューラルネットワークでは、小さな勾配更新を取得する層は学習を停止します。 これらは通常、以前の層です。 したがって、これらの層は学習しないため、RNNはより長いシーケンスで見られるものを忘れることができ、短期間の記憶を持つことができます。 あなたは一般的にリカレントニューラルネットワークの仕組みについての詳細を知りたい場合は、ここで私の以前の記事を読むことができます。
lstmとGRUのソリューションとして
LSTMとGRUのは、短期記憶のソリューションとして作成されました。 彼らは情報の流れを調節することができるゲートと呼ばれる内部メカニズムを持っています。div>

これらのゲートはシーケンス内のどのデータが保持または破棄することが重要であるかを学びます。 そうすることで、関連する情報を長鎖のシーケンスに渡して予測を行うことができます。 リカレントニューラルネットワークに基づく最新の結果のほぼすべては、これら二つのネットワー LSTMとGRUは、音声認識、音声合成、およびテキスト生成で見つけることができます。 あなたも、ビデオのキャプションを生成するためにそれらを使用することができます。さて、この記事の終わりまでに、LSTMとGRUが長いシーケンスを処理するのに優れている理由をしっかり理解する必要があります。 私は直感的な説明とイラストでこれに近づき、できるだけ多くの数学を避けるつもりです。
直感
さて、思考実験から始めましょう。 生命穀物を買いたいと思うかどうか定めるために検討をオンラインで見ていることを言おう(なぜ私に尋ねてはいけない)。 あなたは最初にレビューを読んで、誰かがそれが良いと思ったか、それが悪いと思ったかどうかを判断します。div>

あなたが読んだときレビュー、あなたの脳は無意識のうちに重要なキーワードだけを記憶しています。 あなたは”素晴らしい”と”完璧にバランスのとれた朝食”のような言葉を拾う。 あなたは”これ”、”与えた”、”すべて”、”すべき”などのような言葉をあまり気にしません。 友人がレビューが言ったことを次の日にあなたに尋ねた場合、あなたはおそらくそれを一語一語覚えていないでしょう。 あなたは”間違いなく再び購入されます”のようなものですが、主なポイントを覚えているかもしれません。 あなたが私によく似ているなら、他の言葉は記憶から消えてしまいます。/div>
基本的にLSTMまたはGRUが行うこと。 予測を行うために関連する情報のみを保持し、関連しないデータを忘れることを学ぶことができます。 この場合、あなたが覚えていた言葉は、あなたがそれが良かったと判断しました。
リカレント-ニューラル-ネットワークのレビュー
LSTMまたはGRUがこれをどのように達成するかを理解するために、リカレント-ニューラル-ネットワー 最初の単語は機械可読ベクトルに変換されます。 次に、RNNは一連のベクトルを1つずつ処理します。div>
処理中に、前の隠し状態をシーケンスの次のステップに渡します。 隠された状態は、ニューラルネットワークのメモリとして機能します。 これは、ネットワークが以前に見た以前のデータに関する情報を保持します。div>

rnnのセルを見て、非表示の状態をどのように計算するかを見てみましょう。 最初に、入力と前の非表示状態が結合されてベクトルが形成されます。 そのベクトルは現在の入力と以前の入力に関する情報を持っています。 ベクトルはtanh活性化を通過し、出力は新しい隠された状態、またはネットワークのメモリです。div>

tanh活性化
tanh活性化は、ネットワークを流れる値を調整するために使用されます。 関数tanhは、値を常に-1と1の間にスクイッシュします。div>
ベクトルがニューラルネットワークを流れているとき、さまざまな数学演算のために多くの変換が行われます。 だから、3を掛け続けている値を想像してみましょう。 いくつかの値がどのように爆発して天文学的になり、他の値が重要ではないように見えるかを見ることができます。div>

tanh関数は、値が-1と1の間にとどまることを保証し、ニューラルネットワークの出力を調整します。 上からの同じ値がtanh関数で許可されている境界の間にどのように残っているかを見ることができます。div>

それはrnnです。 内部的には操作はほとんどありませんが、適切な状況(短いシーケンスのような)を考えるとかなりうまく機能します。 RNNは、lstmやGRUの進化した変種よりもはるかに少ない計算リソースを使用します。
LSTM
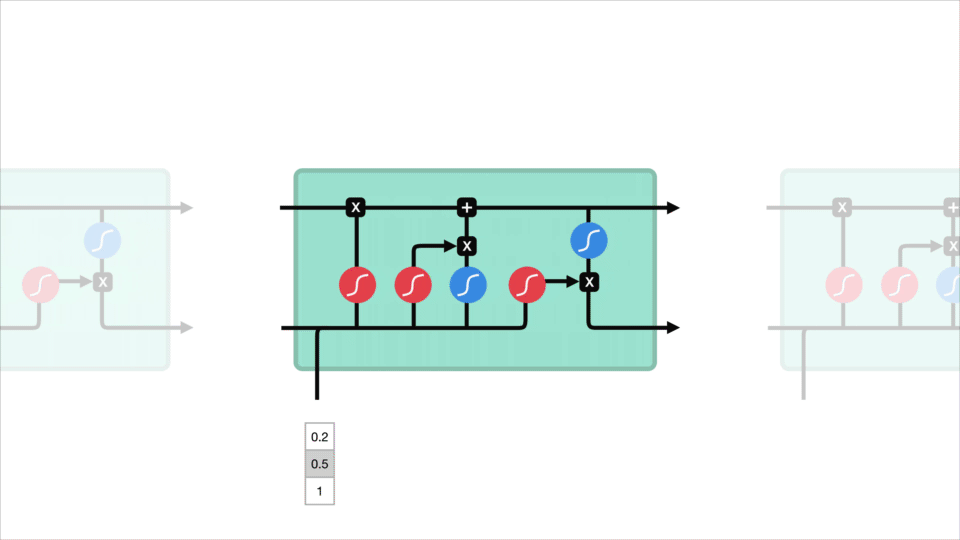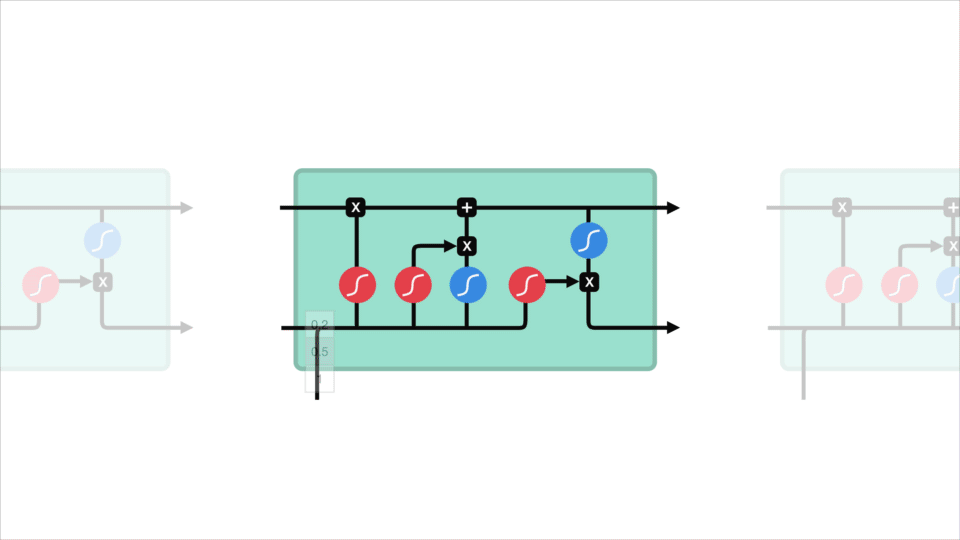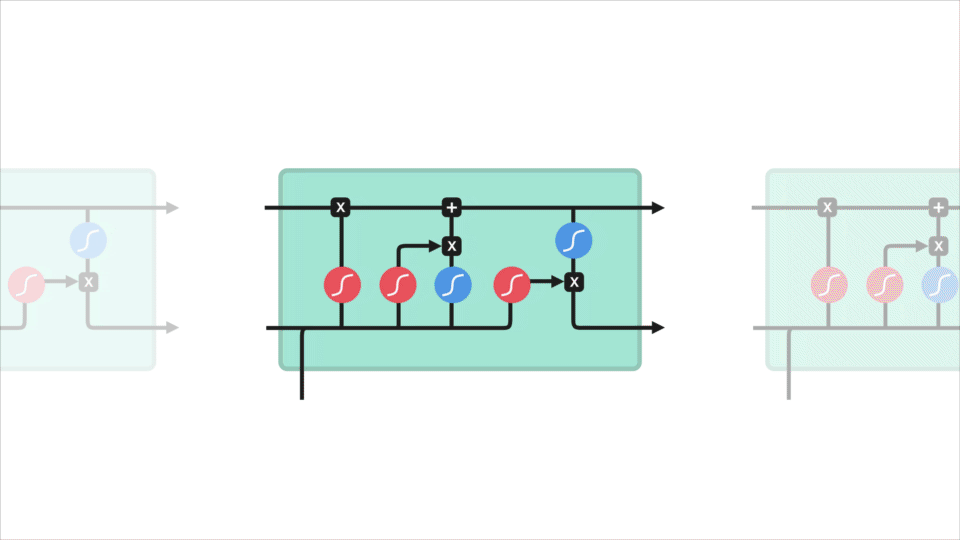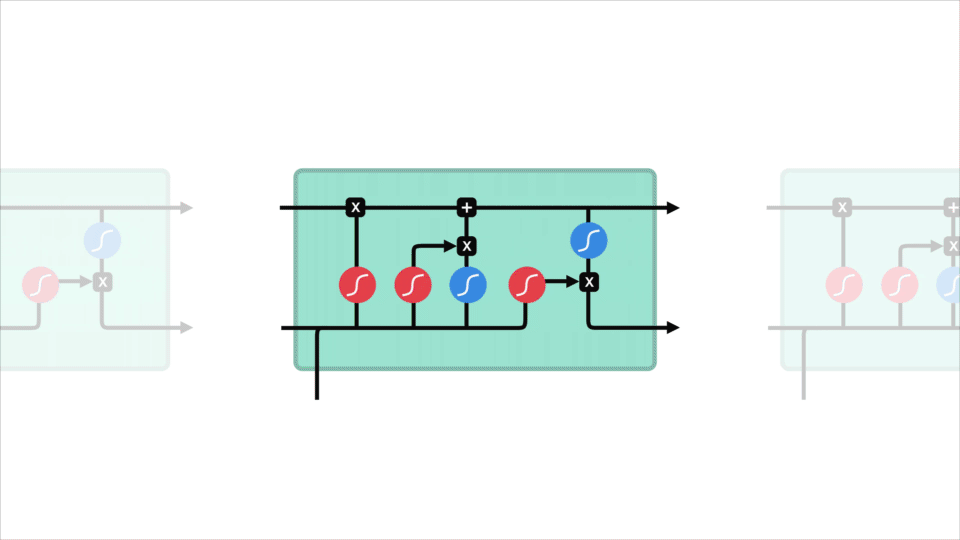
LSTMは、リカレントニューラルネットワークと同様の制御フローを持っています。 それは前方に伝播するように情報を渡すデータを処理します。 違いは、LSTMのセル内の操作です。div>

これらの操作は、lstmが情報を保持または忘れることを可能にするために使用されます。 今、これらの操作を見て少し圧倒的な得ることができますので、我々はステップバイステップで、このステップ上に行きます。
コアコンセプト
LSTMのコアコンセプトは、セルの状態であり、それは様々なゲートです。 セル状態は、シーケンスチェーンの下のすべての方法を相対的な情報を転送する輸送高速道路として機能します。 あなたはそれをネットワークの”メモリ”と考えることができます。 細胞状態は、理論的には、配列の処理全体を通して関連情報を運ぶことができる。 したがって、以前のタイムステップからの情報でさえ、後のタイムステップへの道を作ることができ、短期記憶の影響を減らすことができます。 セルの状態がその旅に行くと、情報はgatesを介してセルの状態に追加または削除されます。 ゲートは、セル状態でどの情報が許可されるかを決定する異なるニューラルネットワークです。 ゲートは訓練の間に保つか、または忘れるためにどんな情報が関連しているか学ぶことができる。
シグモイド
ゲートにはシグモイド活性化が含まれています。 S状結腸活性化は、tanh活性化に類似している。 -1と1の間の値をスクイッシュする代わりに、0と1の間の値をスクイッシュします。 これは、0で乗算される数値が0であるため、値が消えたり”忘れられたりするため、データを更新または忘れると便利です。「1を乗算した数値は同じ値であるため、その値は同じままであるか、保持されます」。「ネットワークは重要でないデータを知ることができるため、忘れたり、どのデータを保持することが重要であるかを知ることができます。Div>
さまざまなゲートが何をしているのかを少し深く掘り下げましょうか? したがって、LSTMセル内の情報の流れを調節する3つの異なるゲートがあります。 忘れゲート、入力ゲート、および出力ゲート。
忘れてゲート
まず、忘れてゲートを持っています。 このゲートは、どのような情報を捨てたり保管したりするかを決定します。 前の非表示状態からの情報と現在の入力からの情報は、関数sigmoidを介して渡されます。 値は0と1の間に出てきます。 0に近いと忘れることを意味し、1に近いと保つことを意味します。div>

入力ゲート
セルの状態を更新するには、入力ゲートがあります。 まず、前の隠し状態と現在の入力をシグモイド関数に渡します。 これは、値を0と1の間に変換することによって、どの値が更新されるかを決定します。 0は重要ではないことを意味し、1は重要を意味します。 また、隠れた状態と現在の入力を関数tanhに渡して、ネットワークを調整するために-1と1の間の値をスキッシュします。 次に、tanh出力にシグモイド出力を掛けます。 シグモイド出力は、tanh出力からどの情報を保持することが重要かを決定します。Div>

セルの状態
今、私たちは、セルの状態を計算するのに十分な情報を持っている必要があります。 まず、セルの状態は、forgetベクトルによってポイントごとに乗算されます。 これは、0の近くの値で乗算されると、セル状態の値をドロップする可能性があります。 次に、入力ゲートからの出力を取得し、ニューラルネットワークが関連する新しい値にセル状態を更新するポイントワイズ加算を行います。 それは私たちに私たちの新しい細胞状態を与えます。div>

出力ゲート
最後に出力ゲートがあります。 出力ゲートは、次の非表示状態がどうあるべきかを決定します。 非表示状態には、以前の入力に関する情報が含まれていることに注意してください。 非表示状態は予測にも使用されます。 まず、前の隠し状態と現在の入力をシグモイド関数に渡します。 次に、新しく変更されたセル状態をtanh関数に渡します。 Tanh出力にシグモイド出力を掛けて、隠された状態がどのような情報を運ぶべきかを決定します。 出力は非表示状態です。 新しいセルの状態と新しい非表示は、次のタイムステップに引き継がれます。div>

確認するには、忘れゲートは、前のステップから維持するために関連するものを決定します。 入力ゲートは、現在のステップから追加するのに関連する情報を決定します。 出力ゲートは、次の非表示状態が何であるかを決定します。
コードデモ
コードを見てよりよく理解している人のために、ここではpython擬似コードを使用した例です。p>

1. まず、前の非表示状態と現在の入力が連結されます。 それを結合と呼びます。
2. Getのフィードを忘れ層に結合します。 このレイヤーは、関連性のないデータを削除します。
4. 候補レイヤーは、combineを使用して作成されます。 候補には、セルの状態に追加する可能性のある値が保持されます。
3. Combineはまた、入力層に供給されたのを取得します。 この層は、候補からのデータを新しいセル状態に追加する必要があるかどうかを決定します。
5. 忘却層、候補層、および入力層を計算した後、これらのベクトルと前のセル状態を使用してセル状態が計算されます。
6. その後、出力が計算されます。
7. 出力と新しいセルの状態をポイントごとに乗算すると、新しい非表示の状態が得られます。
これで終わりです! LSTMネットワークの制御フローは、数テンソル演算とforループです。 予測には非表示の状態を使用できます。 これらすべてのメカニズムを組み合わせることで、LSTMは、シーケンス処理中に覚えたり忘れたりするのに関連する情報を選択することができます。
GRU
LSTMがどのように機能するかを知ったので、GRUを簡単に見てみましょう。 GRUは新しい世代のリカレントニューラルネットワークであり、LSTMに非常に似ています。 GRUはセルの状態を取り除き、隠された状態を使用して情報を転送しました。 また、リセットゲートと更新ゲートの二つのゲートしかありません。DIV>

update gate
update gateはlstmの忘却ゲートと入力ゲートと同様に動作します。 どのような情報を捨てるか、どのような新しい情報を追加するかを決定します。
リセットゲート
リセットゲートは、忘れてどのくらいの過去の情報を決定するために使用される別のゲートです。そして、それはGRUです。
そして、それはGRUです。 GRUのテンソル演算は少なくなります; したがって、彼らはLSTMのを訓練するために少しスピードアップしています。 研究者とエンジニアは、通常、どちらがユースケースに適しているかを判断するために両方を試します。これを要約すると、RNNは予測のシーケンスデータを処理するのに適していますが、短期記憶に苦しんでいます。 LSTMとGRUは、ゲートと呼ばれるメカニズムを使用して短期記憶を軽減する方法として作成されました。 ゲートは、シーケンスチェーンを流れる情報の流れを調節する単なるニューラルネットワークです。 LSTMとGRUは、音声認識、音声合成、自然言語理解などの最先端の深層学習アプリケーションで使用されています。あなたがより深く行くことに興味があるなら、ここではLSTMとGRUのを理解する上であなたに別の視点を与えることができるいくつかの素晴らしいリソーp>
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/