バージョン情報:このページのコードはStata12でテストされました。
ポアソン回帰は、カウント変数をモデル化するために使用されます。ご注意:このページの目的は、さまざまなデータ分析コマンドの使用方法を示すことです。
ご注意ください。
これは、研究者が行うことが期待されている研究プロセスのすべての側面をカバーしていません。 特に、データのクリーニングとチェック、仮定の検証、モデル診断、または潜在的なフォローアップ分析はカバーしていません。
ポアソン回帰の例
例1。 プロイセン軍におけるラバや馬による死亡者の数は、年間である。Ladislaus Bortkiewiczは、preussischen Statistikの20巻からデータを収集しました。 これらのデータは、1800年代後半に20年間にわたってプロイセン軍の10軍団で収集されました。
例2。 食料品店であなたの前に並んでいる人の数。 予測変数には、現在特別割引価格で提供されているアイテムの数と、特別なイベント(休日、大きなスポーツイベントなど)が3日以内であるかどうかが含
例3。 ある高校の生徒が獲得した賞の数。 獲得した賞の数の予測変数には、学生が登録されたプログラムの種類(職業、一般、学術など)と数学の最終試験のスコアが含まれます。
データの説明
説明のために、上記の例3のデータセットをシミュレートしました。 この例では、num_awardsは結果変数であり、高校の学生が1年に獲得した賞の数を示し、mathは連続予測子変数であり、数学の最終試験での学生のスコアを表し、progは
データをロードし、いくつかの記述統計を見てみましょう。各変数には200の有効な観測値があり、その分布は非常に合理的です。 この特定では、無条件の平均と私たちの結果変数の分散は非常に違いはありません。
このデータセット内の変数の説明を続けましょう。 下の表は、プログラムタイプ別の賞の平均数を示しており、結果の平均値がprogによって変化するように見えるので、プログラムタイプが賞の数、私たちの結果変数を予測するための良い候補であることを示唆しているようです。p>
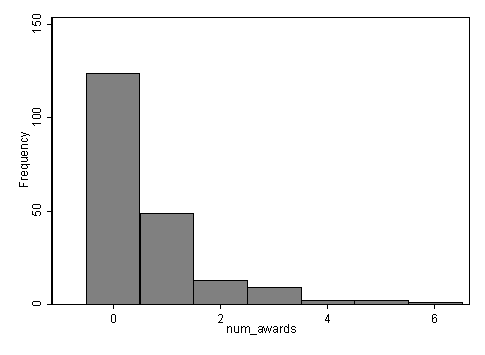
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
分析方法あなたは以下は、あなたが遭遇した可能性のあるいくつかの分析方法のリストです。 リストされている方法のいくつかは非常に合理的ですが、他の方法は賛成から外れているか制限があります。
- ポアソン回帰–ポアソン回帰は、カウントデータのモデリングによく使用されます。 ポアソン回帰には、カウントモデルに有用な拡張がいくつかあります。
- 負の二項回帰–負の二項回帰は、条件付き分散が条件付き平均を超える場合である、過分散カウントデータに使用することができます。 ポアソン回帰と同じ平均構造を持ち、過剰分散をモデル化するための余分なパラメータを持つため、ポアソン回帰の一般化と考えることができます。 結果変数の条件付き分布が過剰分散されている場合、負のbinomialregressionの信頼区間は、ポアソン回帰の信頼区間と比較して狭くなる可能性があります。
- ゼロ膨張回帰モデル-ゼロ膨張モデルは余分なゼロを考慮しようとします。 つまり、データには「真の零点」と「過剰の零点」の2種類の零点が存在すると考えられています。 ゼロ膨張モデルは、2つの方程式を同時に推定し、1つはカウントモデルに対して、もう1つは過剰ゼロに対して推定します。
- OLS回帰–カウント結果変数は、OLS回帰を使用して対数変換および分析されることがあります。 このアプローチでは、ゼロのログ(未定義)を取得することによって生成される未定義の値によるデータの損失や偏った推定など、多くの問題が発生します。
ポアソン回帰
以下では、poissonコマンドを使用してポアソン回帰モデルを推定します。 I.before progは、それが因子変数であることを示します(すなわち の指標変数としてモデルに含まれるべきであることを示している。
基礎となる仮定の軽度の違反を制御するために、Cameron and Trivedi(2009)が推奨するように、vce(robust)オプションを使用して、パラメータ推定値の堅牢な標準誤差を取得します。
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
2自由度カイ二乗検定は、progをまとめると、num_awardsの統計的に有意な予測子であることを示します。
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
モデルの適合度を評価するために、estat gofコマンドを使用して適合度カイ二乗検定を これはモデル係数(ヘッダー情報で見た)のテストではなく、モデル形式のテストです:ポアソンモデル形式は私たちのデータに適合しますか?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
適合度カイ二乗検定は統計的に有意ではないため、モデルは合理的によく適合すると結論づけています。 検定が統計的に有意であった場合、データがモデルに適切に適合しないことを示します。 そのような状況では、省略された予測子変数があるかどうか、線形性の仮定が成り立つかどうか、および/または過剰分散の問題があるかどうかを判断
場合によっては、回帰結果を入射率比として提示したい場合があります。 これらのIRR値は、累乗した上記の出力からの係数に等しくなります。
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
上記の出力は、2の入射率を示しています。progは、参照グループの入射率の2.96倍である(1.prog)。 同様に、3のための入射率。progは、他の変数を一定に保持している参照グループの入射率の1.45倍です。 Num_awardsの入射率のパーセント変化は、数学の単位増加ごとに7%の増加です。
私たちのモデル方程式の形を思い出してください:ログ(num_awards)=切片+b1(prog=2)+b2(prog=3)+b3math。これは次のことを意味します。
num_awards=exp(Intercept+b1(prog=2)+b2(prog=3)+b3math)=exp(Intercept)*exp(b1(prog=2))*exp(b2(prog=3))*exp(b3math)
num_awards=exp(Intercept+b1(Prog=2)+b2(prog=3)+b3math)
num_awards=exp(Intercept+b1(Prog=2))*exp(b2(prog=3))*exp(b3math)
num_awards=exp(Intercept+b1(Prog=2)+b2(prog=/p>
係数はlog(y)スケールで加法効果を持ち、irrはyスケールで乗法効果を持ちます。
結果を提示できるさまざまなメトリックとその解釈に関する追加情報については、J.Scott Long and Jeremy Freese(2006)によるカテゴリ従属変数の回帰モデルUsing Stata,Second Editionを参照してください。
モデルをよりよく理解するために、marginsコマンドを使用できます。 以下では、marginsコマンドを使用して、progの各レベルで予測カウントを計算し、モデル内の他のすべての変数(この例ではmath)を平均値で保持します。 上記の出力では、progのレベル1のイベントの予測数が約であることがわかります。21、その平均で数学を保持しています。 Progのレベル2のイベントの予測数は、でより高いです。図62に示すように、progのレベル3のイベントの予測数は約である。31. Progのレベル2の予測数は(.6249446/.211411)=progのレベル1の予測カウントより2.96倍高いです。 これは、IRR出力テーブルで見たものと一致します。以下では、35から75の範囲のmathの値の予測カウントを10単位で取得します。
以下では、35から75の範囲のmathの値の予測カウントを取得します。
上の表は、progの観測値とmathがすべての観測値で35に保持されている場合、平均予測数(または平均賞数)が約であることを示しています。
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
上の表は、progの観測値とmathがすべての観測値で35に保持されている場合、平均予測数(または平均賞数)が約であることを示しています。13;math=75の場合、平均予測数は約2.17です。 Math=35とmath=45で予測カウントを比較すると、比率は(。2644714/.1311326) = 2.017. これは、10単位の変更の場合の1.0727のIRRと一致します:1.0727^10=2.017。ユーザーが作成したfitstatコマンド(およびStataのestatコマンド)を使用して、モデルを比較する場合に役立つ追加情報を取得できます。 このプログラムをダウンロードするには、search fitstatと入力します(検索コマンドを使用してプログラムを検索し、追加のヘルプを取得するにはどうすれば 検索の使用の詳細については)。p>
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
以下のコマンドを使用して、予測されたイベント数をグラフ化できます。 グラフは、特に学生が高い数学のスコアを持っている場合、ほとんどの賞は、学術プログラム(prog=2)のもののために予測されていることを示しています。 予測された賞の最低数は、一般的なプログラム(prog=1)の学生のためのものです。
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
考慮すべきこと
- 過分散が問題であると思われる場合は、まずモデルが適切に指定されているかどうかを確認する必要があります。省略された変数や関数形式など。 たとえば、上記の例で予測子変数proginを省略した場合、モデルには過剰分散に問題があるように見えます。 言い換えれば、誤って指定されたモデルは、過分散問題のような症状を示す可能性があります。
- モデルが正しく指定されていると仮定すると、foroverdispersionを確認することができます。 これを行うには、負の二項分布(nbreg)を使用して同じ回帰モデルを実行することによる過分散パラメーター alphaの尤度比検定など、いくつかの方法があります。
- 過分散の一般的な原因の一つは、余分なゼロであり、これは追加のデータ生成プロセスによって生成されます。 このような状況では、ゼロ膨張モデルを考慮する必要があります。
- データ生成プロセスで0が許可されていない場合(病院で費やされた日数など)、ゼロ切り捨てモデルがより適切である可能性があります。
- カウントデータには、多くの場合、イベントが発生した可能性のある回数を示す露出変数があります。 この変数は、exp()オプションを使用してポアソンモデルに組み込む必要があります。
- ポアソン回帰の結果変数は負の数を持つことはできず、露出は0を持つことはできません。
- Stataでは、ログリンクとポアソン族を使用してglmコポアソンモデルの他の仮定を確認するには、glmコマンドを使用して残差を取得する必要があります(詳細については、Cameron and Trivedi(1998)およびDupont(2002)を参照)。
- 擬似R二乗の多くの異なる測度が存在する。 それらはすべて、OLS回帰のR-squaredが解釈されるように正確に解釈できないにもかかわらず、OLS回帰のR-squaredが提供する情報と同様の情報を提供しようと さまざまな擬似R二乗の議論については、Long and Freese(2006)またはFAQページを参照してください。.
- ポアソン回帰は最尤推定によって推定されます。 通常、大きなサンプルサイズが必要です。 poissonコマンドの注釈付き出力を参照してください。
- Stata FAQ:count fitを使用してカウントモデルを選択するにはどうすればよいですか?
- Stataオンラインマニュアル
- ポアソン
- Stata Faq
- ポアソンとnbregによって発生率比(IRRs)の標準誤差と信頼区間はどのように計算されますか?
- Cameron、A.C.およびTrivedi、P.K.(1998)。 カウントデータの回帰分析。 ニューヨーク:ケンブリッジプレス。
- Cameron,A.C.Advances in Count Data Regression Talk for The Applied Statistics Workshop,March28,2009.http://cameron.econ.ucdavis.edu/racd/count.html。
- Dupont,W.D.(2002). 生物医学研究者のための統計モデリング:複雑なデータの分析への簡単な紹介。 ニューヨーク:ケンブリッジプレス。
- Long,J.S.(1997). カテゴリ従属変数および限定従属変数の回帰モデル。サウザンドオークス、カリフォルニア州:セージ出版物。
- Long,J.S.And Freese,J.(2006). Stataを使用したカテゴリ従属変数の回帰モデル、第二版。 カレッジステーション、テキサス州:スタタプレス。
- Stataを使用したミクロ経済学。 カレッジステーション、テキサス州:スタタプレス。