VMware High Availability (HA) es una utilidad que elimina la necesidad de hardware y software dedicado en espera en un entorno virtualizado. VMware HA se utiliza a menudo para mejorar la fiabilidad, reducir el tiempo de inactividad en entornos virtuales y mejorar la recuperación ante desastres y la continuidad del negocio.
Este extracto de capítulo de VCP4 Exam Cram: VMware Certified Professional, 2a Edición de Elias Khnaser explora las mejores prácticas de VMware HA.
VMware High Availability se ocupa principalmente de los fallos del host ESX / ESXi y de lo que sucede con las máquinas virtuales (VM) que se ejecutan en este host. HA también puede supervisar y reiniciar una máquina virtual comprobando si las herramientas de VMware todavía se están ejecutando. Cuando un host ESX/ESXi falla por cualquier motivo, también fallan todas las máquinas virtuales en ejecución. VMware HA garantiza que las máquinas virtuales del host con error puedan reiniciarse en otros hosts ESX/ESXi.
Muchas personas confunden erróneamente VMware HA con tolerancia a fallos. VMware HA no tolera errores, ya que si un host falla, las máquinas virtuales en él también fallan. HA solo se ocupa de reiniciar esas máquinas virtuales en otros hosts ESX/ESXi con recursos suficientes. La tolerancia a fallos, por otro lado, proporciona acceso ininterrumpido a los recursos en caso de fallo del host.
 Haga clic en la imagen de la portada del libro de arriba para descargar todo el capítulo de Elias Khnaser sobre copias de seguridad y alta disponibilidad.
Haga clic en la imagen de la portada del libro de arriba para descargar todo el capítulo de Elias Khnaser sobre copias de seguridad y alta disponibilidad.VMware HA mantiene un canal de comunicación con todos los demás hosts ESX / ESXi que son miembros del mismo clúster mediante un latido que envía cada 1 segundo en vSphere 4.0 o cada 10 segundos en vSphere 4.1 de forma predeterminada. Cuando un servidor ESX pierde un latido, los otros hosts esperan 15 segundos para que el otro host responda de nuevo. Después de 15 segundos, el clúster inicia el reinicio de las máquinas virtuales en el host ESX/ESXi que falla en los host ESX/ESXi restantes del clúster. VMware HA también supervisa constantemente los hosts ESX/ESXi que son miembros del clúster y garantiza que los recursos estén siempre disponibles para satisfacer los requisitos en caso de fallo del host.
Supervisión de fallos de máquinas virtuales
La supervisión de fallos de máquinas virtuales es una tecnología que está deshabilitada de forma predeterminada. Su función es monitorear máquinas virtuales, a las que consulta cada 20 segundos a través de un latido. Para ello, utiliza las herramientas de VMware que se instalan dentro de la máquina virtual. Cuando una máquina virtual pierde un latido, VMware HA considera que esta máquina virtual ha fallado e intenta restablecerla. Piense en la Supervisión de Fallos de Máquinas Virtuales como una especie de Alta Disponibilidad para máquinas virtuales.
La supervisión de fallos de máquinas virtuales puede detectar si una máquina virtual se apagó, suspendió o migró manualmente y, por lo tanto, no intenta reiniciarla.
Requisitos previos de configuración de VMware HA
HA requiere los siguientes requisitos previos de configuración para que pueda funcionar correctamente:
- vCenter: Debido a que VMware HA es una característica de clase empresarial, requiere vCenter para poder habilitarla.
- Resolución de DNS: Todos los hosts ESX / ESXi que son miembros del clúster de HA deben poder resolverse entre sí mediante DNS.
- Acceso al almacenamiento compartido: Todos los hosts del clúster de HA deben tener acceso y visibilidad al mismo almacenamiento compartido; de lo contrario, no tendrían acceso a las máquinas virtuales.
- Acceso a la misma red: Todos los hosts ESX/ESXi deben tener las mismas redes configuradas en todos los hosts para que, cuando una máquina virtual se reinicie en cualquier host, vuelva a tener acceso a la red correcta.
Redundancia de consola de servicio
La práctica recomendada dicta que la Consola de servicio (SC) tenga redundancia. VMware HA se queja y emite una advertencia si detecta que la Consola de servicios está configurada en un vSwitch con solo un vmnic. Como se muestra en la Figura 1, puede configurar la redundancia de la Consola de servicio de dos maneras:
- Crear dos grupos de puertos de la consola de servicio, cada uno en un vSwitch diferente.
- Asigne dos tarjetas de interfaz de red física (NIC) en forma de equipo de NIC a la Consola de servicios vSwitch.
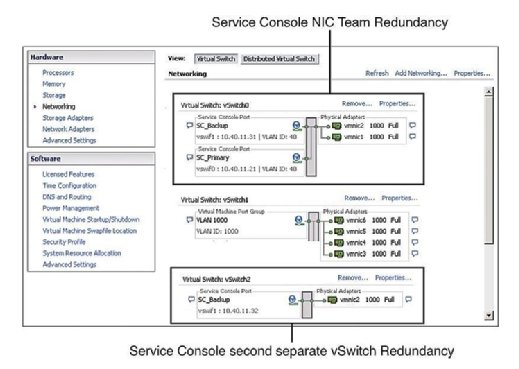
En ambos casos, debe configurar toda la pila de IP con dirección IP, subred y puerta de enlace. Los conmutadores de V de la consola de servicio se utilizan para los latidos del corazón y la sincronización de estado, y utilizan los siguientes puertos:
- Puerto TCP entrante 8042
- Puerto UDP entrante 8045
- Puerto TCP saliente 2050
- Puerto UDP saliente 2250
- Puerto TCP entrante 8042-8045
- Puerto UDP entrante 8042-8045
- Puerto TCP saliente 2050-2250
- Puerto UDP saliente 2050-2250
Si no se configura la redundancia SC, aparece un mensaje de advertencia cuando se habilita HA. Por lo tanto, para evitar ver este mensaje de error y cumplir con las mejores prácticas, configure el SC para que sea redundante.
Planificación de la capacidad de conmutación por error de host
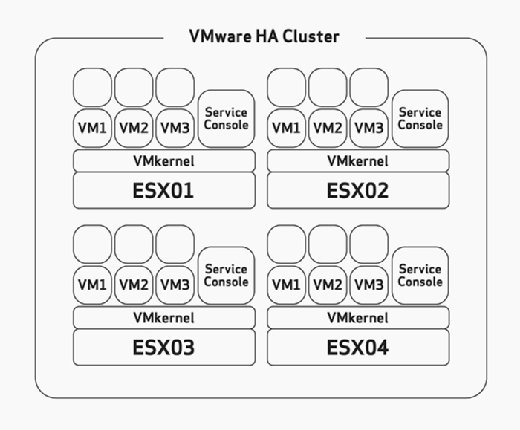
Al configurar HA, debe configurar manualmente la tolerancia máxima de error de host. Esta es una tarea que debe considerar cuidadosamente durante la fase de planificación y dimensionamiento del hardware de su implementación. Esto asumiría que ha creado sus hosts ESX/ESXi con recursos suficientes para ejecutar más máquinas virtuales de las planificadas para poder acomodar HA. Por ejemplo, en la figura 2, observe que el clúster de HA tiene cuatro hosts ESX y que los cuatro hosts tienen capacidad suficiente para ejecutar al menos tres máquinas virtuales más. Debido a que todos ya están ejecutando tres máquinas virtuales, esto significa que este clúster puede permitirse la pérdida de dos hosts ESX/ESXi porque los dos hosts ESX/ESXi restantes pueden encender las seis máquinas virtuales fallidas sin problema si se produce un error.
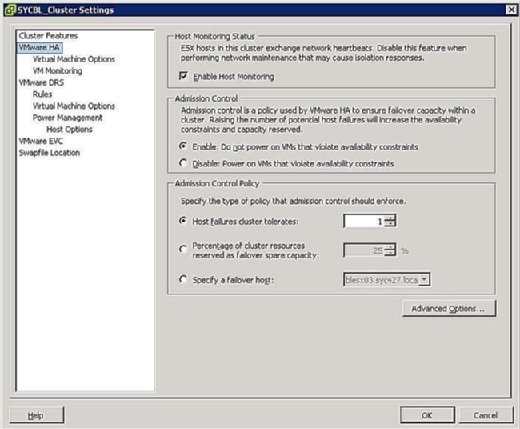
Durante la fase de configuración del clúster de HA, se le presenta una pantalla similar a la que se muestra en la Figura 3 que le pide que defina dos configuraciones de todo el clúster de la siguiente manera:
- Estado de supervisión del host:
- Habilitar supervisión del host: Esta configuración le permite controlar si el clúster de HA debe supervisar los hosts durante un latido. Esta es la forma en que el clúster determina si un host sigue activo. En algunos casos, cuando ejecuta tareas de mantenimiento en hosts ESX/ESXi, puede ser conveniente deshabilitar esta opción para evitar aislar un host.
- Control de admisión:
- Habilitar: No encienda máquinas virtuales que violen las restricciones de disponibilidad: Al seleccionar esta opción, se indica que si no hay recursos disponibles para satisfacer una máquina virtual, no debe estar encendida.
- Deshabilitar: Encender máquinas virtuales que violen las restricciones de disponibilidad: Al seleccionar esta opción, se indica que debe encender una máquina virtual incluso si tiene que comprometer recursos en exceso.
- Directiva de control de admisión:
- Tolera el clúster de errores de host: Esta configuración le permite configurar cuántos errores de host desea tolerar. Los ajustes permitidos son del 1 al 4.
- Porcentaje de recursos de clúster reservados como capacidad sobrante de conmutación por error: Al seleccionar esta opción, se indica que está reservando un porcentaje del total de recursos de clúster en la opción de reserva para conmutación por error. En un clúster de cuatro hosts, una reserva del 25% indica que está reservando un host completo para la conmutación por error. Si desea reservar menos, puede elegir el 10% de los recursos del clúster en su lugar.
- Especificar un host de conmutación por error: Al seleccionar esta opción, se indica que está seleccionando un host en particular como host de conmutación por error en el clúster. Este podría ser el caso si tiene un host de reserva o un host en particular que tiene significativamente más recursos informáticos y de memoria disponibles.
Aislamiento del host
Un fenómeno de red conocido como cerebro dividido se produce cuando el host ESX/ESXi ha dejado de recibir latidos del resto del clúster. Se consulta el latido del corazón por cada segundo en vSphere 4.0 o 10 segundos en vSphere 4.1. Si no se recibe una respuesta, el clúster cree que el host ESX/ESXi ha fallado. Cuando esto ocurre, el host ESX / ESXi ha perdido su conectividad de red en su interfaz de administración. Es posible que el host aún esté en funcionamiento y que las máquinas virtuales ni siquiera se vean afectadas, teniendo en cuenta que podrían estar utilizando una interfaz de red diferente que no se ha visto afectada. Sin embargo, vSphere necesita tomar medidas cuando esto sucede porque cree que un host ha fallado. Para el caso, se creó la respuesta de aislamiento del host. La respuesta de aislamiento de host es la forma de HA de tratar con un host ESX/ESXi que ha perdido su conexión de red.
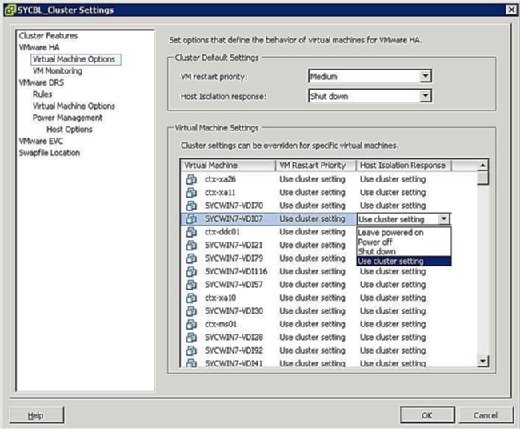
Puede controlar lo que sucede con las máquinas virtuales en caso de aislamiento de host. Para acceder a la pantalla de respuesta de aislamiento de VM, haga clic con el botón secundario en el clúster en cuestión y haga clic en Editar configuración. A continuación, puede hacer clic en Opciones de máquina virtual en el banner de VMware HA en el panel izquierdo. Puede controlar las opciones en todo el clúster configurando la opción de respuesta de aislamiento de host en consecuencia. Esto se aplica a todas las máquinas virtuales del host afectado. Dicho esto, siempre puede anular la configuración del clúster definiendo una respuesta diferente a nivel de máquina virtual.
Como se muestra en la Figura 4, las opciones de respuesta de aislamiento son las siguientes:
- Dejar encendido: Como indica la etiqueta, esta configuración significa que, en caso de aislamiento del host, la máquina virtual permanece encendida.
- Apagado: Esta configuración define que, en caso de aislamiento, la máquina virtual se apaga. Esto es un apagón duro.
- Apagar: Esta configuración define que, en caso de aislamiento, la máquina virtual se apaga correctamente utilizando VMware Tools. Si esta tarea no se completa con éxito en cinco minutos, se ejecuta inmediatamente un apagado. Si VMware Tools no está instalado, en su lugar se ejecuta un apagado.
- Usar configuración de clúster: Esta configuración reenvía la tarea a la configuración de todo el clúster definida en la ventana que se muestra anteriormente en la Figura 4.
En el caso de un aislamiento, esto no significa necesariamente que el host esté inactivo. Debido a que las máquinas virtuales pueden estar configuradas con diferentes NIC físicas y conectadas a diferentes redes, es posible que sigan funcionando correctamente; por lo tanto, debe tener en cuenta esto al establecer la prioridad para el aislamiento. Cuando se aísla un host, esto simplemente significa que su Consola de servicio no puede comunicarse con el resto de los hosts ESX/ESXi del clúster.
Prioridad de recuperación de máquinas virtuales
Si su clúster de HA no puede acomodar todas las máquinas virtuales en caso de que se produzca un error, puede priorizar en las máquinas virtuales. Las prioridades determinan qué máquinas virtuales se reinician primero y qué máquinas virtuales no son tan importantes en caso de emergencia. Estas opciones se configuran en la misma pantalla que la Respuesta de aislamiento cubierta en la sección anterior. Puede configurar la configuración de todo el clúster que se aplicará a todas las máquinas virtuales del host afectado, o puede anular la configuración del clúster configurando una anulación a nivel de máquina virtual.
Puede establecer la prioridad de reinicio de una máquina virtual en una de las siguientes:
- Alta: las máquinas virtuales con una prioridad alta se reinician primero.
- Medium: Esta es la configuración predeterminada.
- Baja: las máquinas virtuales con una prioridad baja se reinician en último lugar.
- Usar configuración de clúster: Las máquinas virtuales se reinician en función de la configuración definida en el nivel de clúster definido en la ventana que se muestra en la siguiente figura.
- Desactivado: La máquina virtual no se enciende.
La prioridad debe establecerse en función de la importancia de las máquinas virtuales. En otras palabras, es posible que desee reiniciar los controladores de dominio y no reiniciar los servidores de impresión. Las máquinas virtuales de mayor prioridad se reinician primero. Las máquinas virtuales que pueden tolerar permanecer apagadas en caso de emergencia deben configurarse para permanecer apagadas para conservar los recursos.
Clustering de MSCS
El propósito principal de un clúster es garantizar que los sistemas críticos permanezcan en línea a cualquier costo y en todo momento. De forma similar a las máquinas físicas que se pueden agrupar en clúster, las máquinas virtuales también se pueden agrupar con ESX mediante tres escenarios diferentes:
- Clúster en una caja: En este escenario, todas las máquinas virtuales que forman parte del clúster residen en el mismo host ESX/ESXi. Como puede haber adivinado, esto crea inmediatamente un único punto de error: el host ESX / ESXi. En lo que respecta al almacenamiento compartido, puede usar discos virtuales como almacenamiento compartido en este escenario, o puede usar Asignación de dispositivos sin procesar (RDM) en modo de compatibilidad virtual.
- Cluster-across-boxes: En este escenario, los nodos del clúster (máquinas virtuales que son miembros del clúster) residen en varios hosts ESX/ESXi, por lo que cada uno de los nodos que componen el clúster puede acceder al mismo almacenamiento para que, si una máquina virtual falla, la otra pueda continuar funcionando y acceder a los mismos datos. Este escenario crea un entorno de clúster ideal al eliminar un único punto de fallo. El almacenamiento compartido es un requisito previo en esto y debe residir en SAN de canal de fibra. También debe usar un RDM en Modo de Compatibilidad Física o Virtual, ya que los discos virtuales no son una configuración compatible para el almacenamiento compartido. Por lo que cada uno de los nodos que componen el clúster puede acceder al mismo almacenamiento, de modo que si una máquina virtual falla, la otra puede continuar funcionando y acceder a los mismos datos.
- Clúster físico a virtual: En este escenario, un miembro del clúster es una máquina virtual, mientras que el otro miembro es una máquina física. El almacenamiento compartido es un requisito previo en este escenario y debe configurarse como RDM en Modo de Compatibilidad Física.
Siempre que diseñe una solución de agrupación en clústeres, debe abordar el problema del almacenamiento compartido, que permitiría el acceso de varios hosts o máquinas virtuales a los mismos datos. vSphere ofrece varios métodos mediante los cuales puede aprovisionar almacenamiento compartido de la siguiente manera:
- Discos virtuales: Puede usar un disco virtual como área de almacenamiento compartida solo si está realizando la agrupación en clúster en un cuadro, en otras palabras, solo si ambas máquinas virtuales residen en el mismo host ESX/ESXi.
- RDM en Modo de compatibilidad física: Este modo le permite conectar un LUN físico directamente a una máquina virtual o máquina física. Este modo le impide usar funciones como instantáneas y se usa idealmente cuando un miembro del clúster es una máquina física mientras que el otro es una máquina virtual.
- RDM en Modo de compatibilidad Virtual: Este modo le permite conectar un LUN físico directamente a una máquina virtual o máquina física. Este modo le ofrece todas las ventajas de los discos virtuales que se ejecutan en VMFS, incluidas las instantáneas y el bloqueo avanzado de archivos. Se accede al disco a través del hipervisor y es ideal cuando se configura un escenario de clúster entre cajas en el que debe dar acceso a ambas máquinas virtuales al almacenamiento compartido.
En el momento de escribir este artículo, el único servicio de agrupación en clústeres compatible con VMware es Microsoft Clustering Services (MSCS). Puede consultar el informe técnico de VMware » Configuración de clústeres de conmutación por error y Servicio de clústeres de Microsoft.»
Tolerancia a fallos de VMware
La tolerancia a fallos de VMware (FT) es otra forma de agrupación en clústeres de máquinas virtuales desarrollada por VMware para sistemas que requieren un tiempo de actividad extremo. Una de las características más atractivas de FT es su facilidad de configuración. FT es simplemente una casilla de verificación que se puede activar. En comparación con la agrupación en clústeres tradicional que requiere configuraciones específicas y, en algunos casos, cableado, FT es simple pero potente.
¿Cómo funciona?
Al proteger máquinas virtuales con FT, se crea una máquina virtual secundaria al mismo paso que la máquina virtual protegida, la primera máquina virtual. FT funciona escribiendo simultáneamente en la primera VM y la segunda VM al mismo tiempo. Cada tarea se escribe dos veces. Si hace clic en el menú Inicio de la primera máquina virtual, también se hará clic en el menú Inicio de la segunda máquina virtual. El poder de FT es su capacidad para mantener ambas máquinas virtuales sincronizadas.
Si la máquina virtual protegida se cae por cualquier motivo, la máquina virtual secundaria toma su lugar de inmediato, apoderándose de su identidad y su dirección IP, y continúa prestando servicios a los usuarios sin interrupción. La máquina virtual protegida recién promocionada crea un secundario para sí misma en otro host y el ciclo se reinicia.
Para aclarar, veamos un ejemplo. Si desea proteger un servidor de Exchange, puede habilitar FT. Si por alguna razón falla el host ESX/ESXi que lleva la máquina virtual protegida, la máquina virtual secundaria se inicia y asume sus funciones sin interrupción en el servicio.
La siguiente tabla describe las diferentes tecnologías de alta disponibilidad y agrupación a las que tiene acceso con vSphere y destaca las limitaciones de cada una de ellas.

Requisitos de tolerancia a fallos
La tolerancia a fallos no es diferente de cualquier otra característica empresarial, ya que requiere que se cumplan ciertos requisitos previos antes de que la tecnología pueda funcionar de manera adecuada y eficiente. Estos requisitos se describen en la siguiente lista y se desglosan en las diferentes categorías que requieren requisitos mínimos específicos:
- Requisitos de host:
- CPU compatible con FT. Consulte este artículo de VMware KB para obtener más información.
- La virtualización de hardware debe estar habilitada en el bios.
- Las velocidades de reloj de la CPU del HOST deben estar a una distancia de 400 MHz entre sí.
- Requisitos de VM:
- Las VM deben residir en almacenamiento compartido compatible (FC, iSCSI y NFS).
- Las máquinas virtuales deben ejecutar un sistema operativo compatible.
- Las máquinas virtuales deben almacenarse en un VMDK o en un RDM virtual.
- Las máquinas virtuales no pueden tener VMDK de aprovisionamiento limitado y deben usar un disco virtual Eagerzeroedthick.
- Las máquinas virtuales no pueden tener más de una vCPU configurada.
- requisitos del Clúster:
- Todos los hosts ESX/ESXi deben tener la misma versión y el mismo nivel de parche.
- Todos los hosts ESX/ESXi deben tener acceso a los almacenes de datos y redes de VM.
- VMware HA debe estar habilitado en el clúster.
- Cada host debe tener configurada una NIC de registro vMotion y FT.
- La comprobación de certificados de host también debe estar habilitada.
Es muy recomendable que, además de comprobar la compatibilidad del procesador con FT, compruebe la marca y el modelo de su servidor con FT en la Lista de Compatibilidad de hardware de VMware (HCL).
Aunque FT es una gran solución de agrupación en clústeres, es importante tener en cuenta que también tiene ciertas limitaciones. Por ejemplo, las máquinas virtuales FT no se pueden snapshotear ni se pueden vMotionar de almacenamiento. De hecho, estas máquinas virtuales se marcarán automáticamente con DRS desactivado y no participarán en ningún equilibrio de carga de recursos dinámicos.
Cómo habilitar FT
Habilitar FT no es difícil, pero implica configurar algunas configuraciones diferentes. Las siguientes configuraciones deben configurarse correctamente para que FT funcione:
- Habilitar la comprobación de certificados de Host: Para habilitar esta configuración, inicie sesión en vCenter server y haga clic en Administración en el menú Archivo y haga clic en Configuración de vCenter Server. En el panel izquierdo, haga clic en Configuración de SSL y marque la casilla vCenter Requiere certificados SSL de Host verificado.
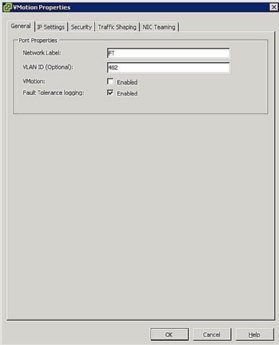
Figura 5. Configuración de grupo de puertos FT - Configurar redes de host: La configuración de red para FT es sencilla y sigue los mismos pasos y procedimientos que vMotion, excepto que en lugar de marcar la casilla vMotion, marque la casilla de registro de tolerancia a fallos, como se muestra en la Figura 5.
- Activar y desactivar FT: Una vez que haya cumplido con los requisitos anteriores, ahora puede activar y desactivar FT para máquinas virtuales. Este proceso también es sencillo: Encuentre la máquina virtual que desea proteger, haga clic con el botón derecho en ella y seleccione Tolerancia a fallos>Activar la tolerancia a fallos.
Aunque FT es una tecnología de agrupación en clústeres de primera generación, funciona de manera impresionante y simplifica los métodos tradicionales complicados de creación, configuración y mantenimiento de clústeres. FT es una tecnología impresionante para un punto de vista de tiempo de actividad y desde un punto de vista de conmutación por error sin interrupciones.