você não pode usar prontamente variáveis categóricas como predictores na regressão linear: você precisa dividi-las em variáveis dicotômicas conhecidas como variáveis fictícias.
a maneira ideal de criar estas é a nossa ferramenta de variáveis fictícias. Se você não quiser usar esta ferramenta, então este tutorial mostra a maneira certa de fazê-lo manualmente.
- Exemplo I – Qualquer Variável Numérica
- Exemplo II – Variável Numérica Adjacente com números Inteiros
- Exemplo III – Variável de Seqüência de caracteres com a Conversão
- Exemplo IV – Variável de Seqüência de caracteres sem Conversão
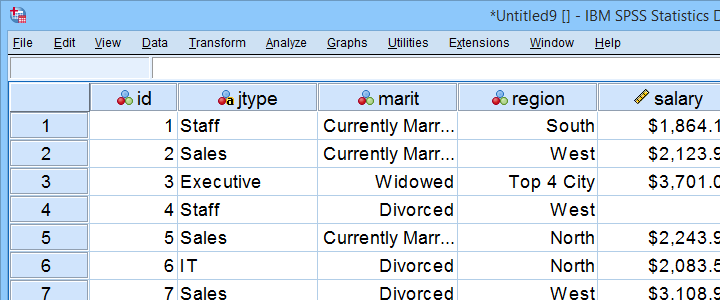
Exemplo de Arquivo de Dados
Este tutorial usa a equipe.sav por todo o lado. Parte deste arquivo de dados é mostrado abaixo.
exemplo I – any Numeric Variable
Let’s first create dummy variables for marit, short for marital status. O nosso primeiro passo é executar uma tabela básica de frequências com frequência marit.O quadro abaixo mostra o quadro resultante.
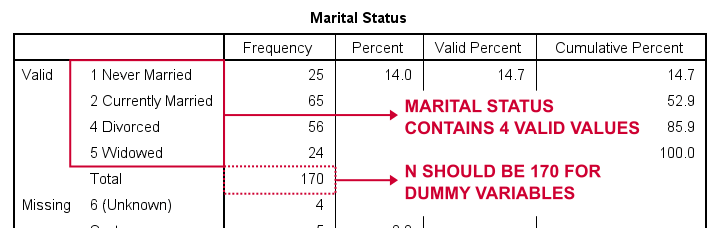
então como dividir o estado civil em variáveis fictícias? Em primeiro lugar, omitimos sempre uma categoria, A categoria de referência. Você pode escolher qualquer categoria como a categoria de referência.
assim, para este exemplo, escolhemos 5 (viúvo). Isto implica que vamos criar 3 variáveis fictícias representando as categorias 1, 2 e 4 (note que 3 não ocorre nesta variável).
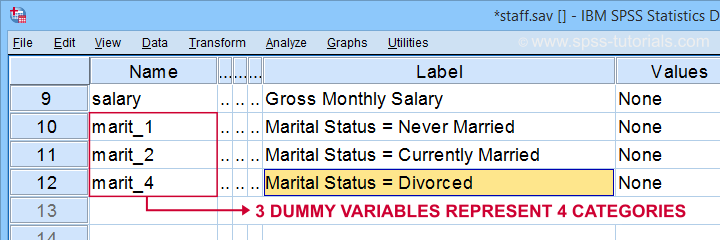
a sintaxe abaixo mostra como criar e rotular as nossas 3 variáveis fictícias. Vamos a isso.
compute marit_1 = (marit = 1).
compute marit_2 = (marit = 2).
compute marit_4 = (marit = 4).
*Apply variable labels to dummy variables.
variável labels
marit_1 ‘Marital Status = Never Married’
marit_2 ‘Marital Status = Currently Married’
marit_4 ‘Marital Status = Divorched’.
*Quick check first dummy variable
frequencies marit_1.
resultados
em primeiro lugar, note que criamos 3 variáveis fictícias bem rotuladas no nosso conjunto de dados activo.
a tabela abaixo mostra a distribuição de frequência para a nossa primeira variável fictícia.

Note que a nossa variável dummy tem 3 valores distintos:
- entrevistados cujo estado civil é não “que nunca se casou” pontuação 0;
- entrevistados cujo estado civil é “nunca se casou” pontuação 1;
- entrevistados cujo estado civil é um valor em falta (e, portanto, desconhecido) ter um sistema de valor em falta.
podemos agora verificar os resultados mais detalhadamente, executandocrosstabs marit por marit_1 a marit_4.Fazendo isso cria 3 tabelas de contingência, a primeira das quais é mostrada abaixo.
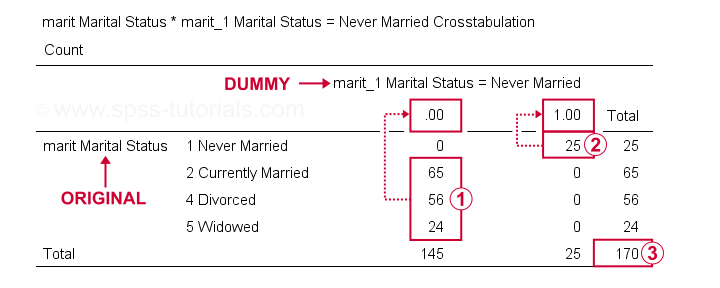
No nosso variável dummy, inquiridos ter outros marital status de “nunca se casou” todos pontuação 0;
inquiridos ter outros marital status de “nunca se casou” todos pontuação 0; inquiridos que nunca se casou” todos pontuação 1;
inquiridos que nunca se casou” todos pontuação 1;
 we’ve a sample size of N = 170 (this table only includes inquiries without missing values on either variable).opcionalmente, uma verificação final-muito completa – é comparar os resultados de ANOVA para a variável original com os resultados de regressão usando as nossas variáveis fictícias. A sintaxe abaixo faz exatamente isso, usando salário mensal como variável dependente.
we’ve a sample size of N = 170 (this table only includes inquiries without missing values on either variable).opcionalmente, uma verificação final-muito completa – é comparar os resultados de ANOVA para a variável original com os resultados de regressão usando as nossas variáveis fictícias. A sintaxe abaixo faz exatamente isso, usando salário mensal como variável dependente.
regression
/ dependent salary
/ method enter marit_1 to marit_4.
*ANOVA mínima usando a variável original.= = ligações externas = =
Note que ambas as análises resultam em tabelas ANOVA idênticas. Vamos discutir mais detalhadamente a regressão variável ANOVA versus simulada num tutorial futuro.
exemplo II-variável numérica com inteiros adjacentes
vamos agora criar variáveis fictícias para a região. Mais uma vez, começamos por inspecionar uma tabela de frequência mínima que vamos criar pela região de freqüências running.Isto resulta na tabela abaixo.
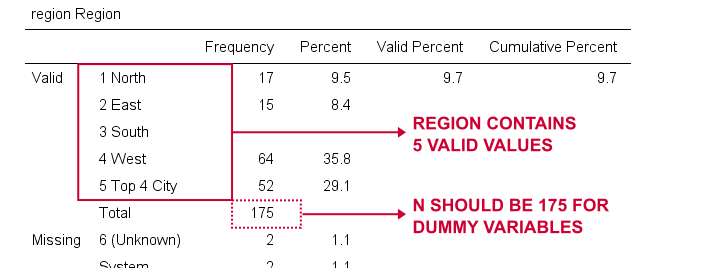
escolheremos 1 (“Norte”) como a nossa categoria de referência. Vamos, portanto, criar variáveis fictícias para as Categorias 2 a 5. Como estes são inteiros adjacentes, podemos acelerar as coisas usando fazer repetir como mostrado abaixo.
do repeat #vals = 2 to 5 / # vars = region_2 to region_5.
recode region (#vals = 1) (lo thru hi = 0) into # vars.end repeat print.
*aplicar etiquetas de variáveis a novas variáveis.
variable labels
region_2 ‘Region = East’
region_3 ‘Region = South’
region_4 ‘Region = West’
region_5 ‘Region = Top 4 City’.
*Quick check.
crosstabs região por region_2 a region_5.
uma inspecção cuidadosa dos quadros resultantes confirma que todos os resultados estão correctos.
exemplo III – String variável com conversão
infelizmente, os nossos primeiros 2 métodos não funcionam para variáveis de cadeia de caracteres como jtype-short para “tipo de trabalho”). A solução mais fácil é convertê-lo em uma variável numérica como discutido em SPSS converter String para variável numérica. A sintaxe abaixo usa AUTORECODE para fazer o trabalho.
autorrecode jtype
/para njtype.
*Check result.frequencies njtype.
*definir valores em falta.valores em falta njtype (1,2).
*verifique novamente o resultado.frequencies njtype.
Result

Uma vez que njtype-short for “numeric job type”- is a numeric variable, we can now use method I or method II for breaking it up into dummy variables.
exemplo variável IV-String sem conversão
Converter variáveis string em variáveis numéricas é fácil criar variáveis fictícias para elas. Sem esta conversão, o processo é complicado porque o SPSS não lida com valores em falta para variáveis de cadeia corretamente. No entanto, a sintaxe abaixo obtém o trabalho feito corretamente.
*Chance’ (desconhecido) ‘em’NA’.
recode jtype (‘(desconhecido) ‘ = ‘NA’).
*definir os valores em falta do utilizador.valores em falta jtype ( ” , ‘na’).
*Reinspecciona frequências.frequencies jtype.
*Create dummy variables for string variable.
if (not missing (jtype)) jtype_1 = (jtype = ‘IT’).
if (not missing (jtype)) jtype_2 = (jtype = ‘Management’).
if (not missing (jtype)) jtype_3 = (jtype = “Sales”).
if (not missing (jtype)) jtype_4 = (jtype = ‘Staff’).
*Apply variable labels to dummy variables.
variable labels
jtype_1 ‘Job type = IT’
jtype_2 ‘Job type = Management’
jtype_3 ‘Job type = Sales’
jtype_4 ‘Job type = Staff’.
*Check results.
crosstabs jtype by jtype_1 to jtype_4.
notas finais
a criação de variáveis fictícias para variáveis numéricas pode ser feita rápida e facilmente. A definição de etiquetas variáveis adequadas, no entanto, sempre leva um pouco de trabalho. As variáveis de String necessitam de alguns passos extras, mas também são bastante realizáveis.
no entanto, a opção mais fácil é o nosso SPSS criar Ferramenta de variáveis fictícias, uma vez que ele cuida perfeitamente de tudo.