por William W Wold
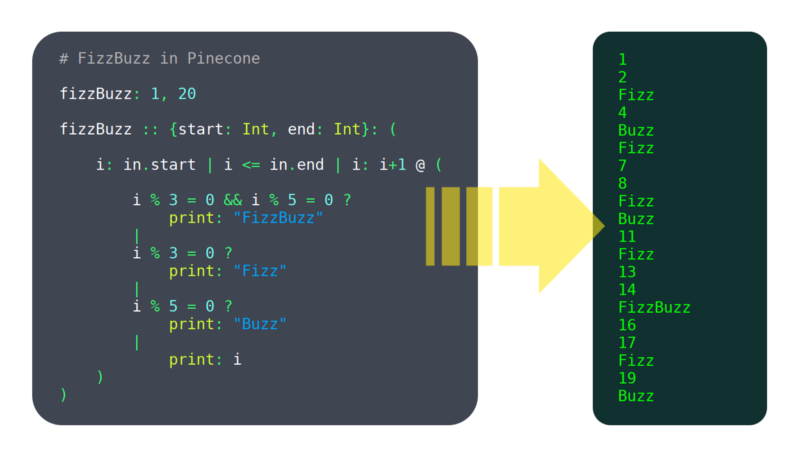
Nos últimos 6 meses, eu estive trabalhando em uma linguagem de programação chamada Pinha. Eu não chamaria de maduro ainda, mas ele já tem recursos suficientes trabalhando para ser utilizável, tais como:
- variáveis
- funções
- estruturas definidas pelo Usuário
Se você estiver interessado nele, confira a página de destino do Pinecone ou o seu acordo com o GitHub.não sou especialista. Quando eu comecei este projeto, Eu não tinha idéia do que eu estava fazendo, e ainda não tenho. eu tive aulas zero sobre criação de linguagem, li apenas um pouco sobre isso on-line, e não segui muito dos conselhos que eu tenho sido dado.
E ainda assim, eu fiz uma linguagem completamente nova. E funciona. Então devo estar a fazer alguma coisa bem.
neste post, vou mergulhar sob o capô e mostrar-lhe o pipeline Pinecone (e outras linguagens de programação) usado para transformar o código fonte em magia.também vou tocar em alguns dos tradeoffs que tive de fazer, e por que tomei as decisões que tomei.
Este não é de forma alguma um tutorial completo sobre a escrita de uma linguagem de programação, mas é um bom ponto de partida se você está curioso sobre o desenvolvimento da linguagem.
começar
“eu não tenho absolutamente nenhuma idéia de onde eu iria começar” é algo que eu ouço muito quando digo a outros desenvolvedores que estou escrevendo uma língua. Caso seja essa a tua reacção, vou agora passar por algumas decisões iniciais que são tomadas e passos que são dados ao iniciar qualquer nova língua.
compilados vs interpretados
Existem dois tipos principais de línguas: compiladas e interpretadas:
- um compilador descobre tudo o que um programa fará, transforma-o em “código de máquina” (um formato que o computador pode executar muito rápido), então guarda isso para ser executado mais tarde.
- um interpretador passa através do código fonte Linha A linha, descobrindo o que ele está fazendo como ele vai.
tecnicamente qualquer língua Pode ser compilada ou interpretada, mas uma ou outra geralmente faz mais sentido para uma língua específica. Geralmente, a interpretação tende a ser mais flexível, enquanto a compilação tende a ter maior desempenho. Mas isso é apenas arranhar a superfície de um tópico muito complexo.
I desempenho de alto valor, e eu vi uma falta de linguagens de programação que são tanto alta performance e simplicidade-orientada, então eu fui com compilado para Pinecone.
esta foi uma decisão importante para tomar no início, porque muitas decisões de design de linguagem são afetadas por ela (por exemplo, a datilografia estática é um grande benefício para as línguas compiladas, mas não tanto para as interpretadas).
apesar do fato de que Pinecone foi projetado com compilação em mente, ele tem um interpretador totalmente funcional que foi a única maneira de executá-lo por um tempo. Há uma série de razões para isso, que explicarei mais tarde.
escolher uma linguagem
eu sei que é um pouco meta, mas uma linguagem de programação é em si um programa, e, portanto, você precisa escrevê-lo em uma linguagem. Eu escolhi C++ por causa de seu desempenho e grande conjunto de recursos. Também gosto de trabalhar em C++.
Se você está escrevendo uma linguagem interpretada, faz muito sentido escrevê-la em uma compilada (como C, C++ ou Swift), porque o desempenho perdido na linguagem do seu intérprete e do interpretador que está interpretando seu interpretador irá se agravar.
Se você planeja compilar, uma linguagem mais lenta (como Python ou JavaScript) é mais aceitável. O tempo de compilação pode ser mau, mas na minha opinião isso não é tão importante como o mau tempo de execução.
Design de alto nível
uma linguagem de programação é geralmente estruturada como um gasoduto. Ou seja, tem várias fases. Cada etapa tem dados formatados de uma forma específica e bem definida. Ele também tem funções para transformar dados de cada etapa para a próxima.
a primeira etapa é uma cadeia que contém todo o ficheiro de código de entrada. A fase final é algo que pode ser executado. Tudo isto se tornará claro à medida que atravessamos o gasoduto Pinecone passo a passo.
Análise

O primeiro passo na maioria das linguagens de programação é a análise, ou simbolização. “Lex” é o diminutivo de análise lexical, uma palavra muito chique para dividir um monte de texto em fichas. A palavra “tokenizer” faz muito mais sentido, mas “lexer” é tão divertido dizer que a uso na mesma.
Tokens
um token é uma pequena unidade de uma língua. Um token pode ser uma variável ou nome da função (AKA um identificador), um operador ou um número.
a tarefa do Lexer
o lexer é suposto levar em uma cadeia contendo um arquivo inteiro de valor de código fonte e cuspir para fora uma lista contendo cada token.
as fases futuras do gasoduto não se referirão ao código fonte original, por isso o lexer deve produzir toda a informação necessária por eles. A razão para este formato de pipeline relativamente estrito é que o lexer pode fazer tarefas como remover comentários ou detectar se algo é um número ou identificador. Você quer manter essa lógica trancada dentro do lexer, ambos para que você não tenha que pensar sobre essas regras ao escrever o resto da linguagem, e assim você pode mudar este tipo de sintaxe tudo em um só lugar.
Flex
No dia em que comecei a linguagem, a primeira coisa que escrevi foi um lexer simples. Logo depois, comecei a aprender sobre ferramentas que supostamente tornariam o lexing mais simples, e menos buggy.
a ferramenta predominante é Flex, um programa que gera lexers. Você lhe dá um arquivo que tem uma sintaxe especial para descrever a gramática da linguagem. A partir disso, gera um programa C que Lexa uma cadeia e produz a saída desejada.
a minha decisão
optei por manter o lexer que escrevi por enquanto. No final, eu não vi benefícios significativos de usar o Flex, pelo menos não o suficiente para justificar a adição de uma dependência e complicar o processo de construção.o meu lexer tem apenas algumas centenas de linhas, e raramente me dá problemas. Rolar meu próprio lexer também me dá mais flexibilidade, como a capacidade de adicionar um operador para o idioma sem editar vários arquivos.
de Análise

O segundo estágio do pipeline é o analisador. O analisador transforma uma lista de tokens em uma árvore de nós. Uma árvore usada para armazenar este tipo de dados é conhecida como uma árvore de sintaxe abstrata, ou AST. Pelo menos em Pinecone, o AST não tem nenhuma informação sobre os tipos ou quais identificadores são quais. É simplesmente tokens estruturados.
funções de processamento
o analisador adiciona estrutura à lista ordenada de fichas que o lexer produz. Para acabar com as ambiguidades, o analisador deve levar em conta parênteses e a ordem de operações. Simplesmente processar operadores não é terrivelmente difícil, mas à medida que mais construções de linguagem são adicionadas, o processamento pode se tornar muito complexo.
Bison
novamente, houve uma decisão de tomar envolvendo uma biblioteca de terceiros. A biblioteca de análise predominante é o Bisonte. O Bison trabalha como o Flex. Você escreve um arquivo em um formato personalizado que armazena a informação da gramática, então Bison usa isso para gerar um programa C que fará o seu processamento. Não escolhi usar Bisonte.
Why Custom Is Better
With The lexer, the decision to use my own code was fairly obvious. Um lexer é um programa tão trivial que não escrever o meu próprio parecia quase tão estúpido como não escrever o meu próprio ‘left-pad’.com o analisador, é uma questão diferente. Meu parser Pinecone tem atualmente 750 linhas de comprimento, e eu escrevi três delas porque as duas primeiras eram lixo.
originalmente tomei a minha decisão por uma série de razões, e embora não tenha corrido completamente sem problemas, a maioria deles se mantém verdadeiro. As principais são as seguintes:
- Minimize a mudança de contexto no fluxo de trabalho: a mudança de contexto entre C++ e Pinecone é ruim o suficiente sem jogar na gramática gramática de Bison
- mantenha a compilação simples: cada vez que a gramática muda Bison tem que ser executado antes da compilação. Isto pode ser automatizado, mas torna-se uma dor quando se muda entre sistemas de construção.eu gosto de construir coisas fixes: Eu não fiz Pinecone porque pensei que seria fácil, então por que eu delegaria um papel central quando eu poderia fazê-lo eu mesmo? Um analisador personalizado pode não ser trivial, mas é completamente realizável.
no início eu não estava completamente certo se eu estava indo para um caminho viável, mas me foi dada confiança Pelo que Walter Bright (um desenvolvedor em uma versão inicial de C++, e o criador da linguagem D) tinha a dizer sobre o tópico:
“um pouco mais controverso, eu não perderia tempo com geradores lexer ou parser e outros chamados “Compiladores”.”São uma perda de tempo. Escrever um lexer e parser é uma pequena porcentagem do trabalho de escrever um compilador. Usando um gerador vai demorar tanto tempo quanto escrever um à mão, e ele vai se casar com o gerador (o que importa quando portando o compilador para uma nova plataforma). E os geradores também têm a infeliz reputação de emitirem péssimas mensagens de erro.”
de Ação de Árvore
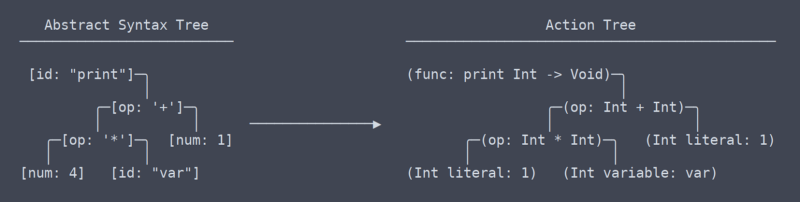
temos, agora, a área comum de termos universais, ou, pelo menos, eu não sei o que os termos são mais. Pelo que sei, o que eu chamo de “árvore de ação” é mais semelhante ao IR da LLVM (representação intermediária).
Há uma diferença sutil mas muito significativa entre a árvore de ação e a árvore de sintaxe abstrata. Levou-me bastante tempo para descobrir que deve haver mesmo uma diferença entre eles (o que contribuiu para a necessidade de reescritas do analisador).
Árvore de Acção vs AST
simplificando, a árvore de acção é a AST com contexto. Esse contexto é info, tal como o tipo a função retorna, ou que dois lugares em que uma variável é usada estão de fato usando a mesma variável. Porque ele precisa descobrir e lembrar de todo esse contexto, o código que gera a árvore de ação precisa de muitas tabelas de pesquisa de espaços de nomes e outros botões de thingam.
executando a árvore de ação
Uma vez que temos a árvore de ação, executar o código é fácil. Cada nó de ação tem uma função ‘Executar’ que recebe alguma entrada, faz o que a ação deve (incluindo possivelmente chamar sub ação) e retorna a saída da ação. Este é o intérprete em acção.
opções de Compilação
” mas espere!”Ouço-te dizer, “a Pinecone não é suposto ser compilada?”Sim, é. Mas compilar é mais difícil do que interpretar. Há algumas abordagens possíveis.
Construa o meu próprio compilador
isto pareceu-me uma boa ideia no início. Adoro fazer as coisas sozinha, e tenho andado ansiosa por uma desculpa para ser boa na montagem.
infelizmente, escrever um compilador portátil não é tão fácil como escrever algum código de máquina para cada elemento de linguagem. Devido ao número de arquiteturas e sistemas operacionais, é impraticável para qualquer indivíduo escrever uma infra-estrutura de compilador de plataforma cruzada.
mesmo as equipes por trás Swift, Rust e Clang não querem se preocupar com tudo por conta própria, então em vez disso, todos eles usam…
LLVM
LLVM é uma coleção de ferramentas de compilador. É basicamente uma biblioteca que vai transformar sua linguagem em um executável binário compilado. Pareceu-me a escolha perfeita, por isso entrei logo. Infelizmente, não verifiquei a profundidade da água e afoguei-me imediatamente.
LLVM, embora não seja uma linguagem de montagem dura, é uma biblioteca complexa gigantesca dura. Não é impossível de usar, e eles têm bons tutoriais, mas eu percebi que eu teria que obter alguma prática antes de eu estava pronto para implementar totalmente um compilador Pinecone com ele.
Transpiling
i wanted some sort of compiled Pinecone and I wanted it fast, so I turned to one method I knew I could make work: transpiling.
I wrote a Pinecone to C++ transpiler, and added the ability to automatically compile the output source with GCC. Isso atualmente funciona para quase todos os programas Pinecone (embora haja alguns casos de borda que quebram). Não é uma solução particularmente portátil ou escalável, mas funciona por enquanto.
Future
assumindo que eu continuo a desenvolver Pinecone, ele vai obter suporte de compilação LLVM mais cedo ou mais tarde. Eu suspeito que nenhum mater quanto eu trabalho nele, o transpiler nunca será completamente estável e os benefícios da LLVM são numerosos. É só uma questão de quando eu tenho tempo para fazer alguns projetos de amostra em LLVM e obter o jeito dele.
até então, o interpretador é ótimo para programas triviais e transpiling c++ funciona para a maioria das coisas que precisam de mais desempenho.
conclusão
espero ter tornado as linguagens de programação um pouco menos misteriosas para ti. Se você quiser fazer um, eu recomendo. Há uma tonelada de detalhes de implementação para descobrir, mas o esboço aqui deve ser suficiente para levá-lo a ir.
aqui está meu conselho de alto nível para começar (lembre-se, eu realmente não sei o que estou fazendo, então tome com um grão de sal):
- se em dúvida, vá interpretado. As linguagens interpretadas são geralmente mais fáceis de desenhar, construir e aprender. Não te estou a desencorajar de escrever um compilado, se sabes que é isso que queres fazer, mas se estás indeciso, eu iria interpretar.quando se trata de lexers e parsers, faz o que quiseres. Há argumentos válidos a favor e contra escrever o seu próprio. No final, se você pensar em seu projeto e implementar tudo de uma forma sensata, isso realmente não importa.Aprenda com o oleoduto com que acabei. Muitas tentativas e erros foram para projetar o oleoduto que eu tenho agora. Eu tentei eliminar as ASTs, ASTs que se transformam em ações árvores no lugar, e outras idéias terríveis. Este oleoduto funciona, por isso não o mudes a menos que tenhas uma boa ideia.se você não tem tempo ou motivação para implementar uma linguagem complexa de propósito geral, tente implementar uma linguagem esotérica como Brainfuck. Estes intérpretes podem ser tão curtos quanto algumas centenas de linhas.tenho muito poucos arrependimentos quando se trata de desenvolvimento de Pinecone. Fiz uma série de más escolhas ao longo do caminho, mas reescrevi a maior parte do Código afetado por tais erros.
neste momento, a Pinecone está num estado suficientemente bom para funcionar bem e poder ser facilmente melhorada. Escrever Pinecone tem sido uma experiência extremamente educacional e agradável para mim, e está apenas começando.