Olá e bem-vindo ao Guia Ilustrado de Longa Memória de Curto Prazo (LSTM) e Fechado Recorrente Unidades (GRU). Sou o Michael, e sou engenheiro de aprendizagem de máquinas no espaço de Assistente de voz da IA.neste post, vamos começar com a intuição por trás da LSTM ‘s e da GRU. depois vou explicar os mecanismos internos que permitem que a LSTM e a GRU funcionem tão bem. Se você quer entender o que está acontecendo sob o capô para estas duas redes, então este post é para você.
Você também pode assistir a versão de vídeo deste post no youtube, se preferir.
redes neurais recorrentes sofrem de memória de curto prazo. Se uma sequência for longa o suficiente, eles terão dificuldade em transportar informações de etapas anteriores para etapas posteriores. Então, se você está tentando processar um parágrafo do texto para fazer previsões, RNN’s pode deixar de fora informações importantes desde o início.durante a propagação das costas, as redes neurais recorrentes sofrem do problema do gradiente de desaparecimento. Gradientes são valores usados para atualizar pesos de redes neurais. O problema do gradiente de desaparecimento é quando o gradiente encolhe à medida que se propaga através do tempo. Se um valor gradiente se torna extremamente pequeno, ele não contribui com muita aprendizagem.

Tão recorrente em redes neurais, camadas que tem um pequeno gradiente de atualização para de aprender. Essas são geralmente as camadas anteriores. Então, como essas camadas não aprendem, RNN’s pode esquecer o que viu em sequências mais longas, tendo assim uma memória de curto prazo. Se você quiser saber mais sobre a mecânica das redes neurais recorrentes em geral, você pode ler meu post anterior aqui.
LSTM’s e GRU’s como uma solução
LSTM ‘s e GRU’ s foram criados como a solução para memória de curto prazo. Eles têm mecanismos internos chamados portões que podem regular o fluxo de informação.

Estas portas podem aprender que os dados em uma sequência é importante para manter ou jogar fora. Ao fazer isso, ele pode passar informações relevantes pela longa cadeia de sequências para fazer previsões. Quase todos os resultados de última geração baseados em redes neurais recorrentes são alcançados com essas duas redes. LSTM’s and GRU’s can be found in speech recognition, speech synthesis, and text generation. Você pode até usá-los para gerar legendas para vídeos.
Ok, então no final deste post você deve ter uma compreensão sólida de porque LSTM e GRU são bons no processamento de sequências longas. Vou abordar isso com explicações intuitivas e ilustrações e evitar o máximo de matemática possível.Ok, vamos começar com uma experiência de pensamento. Vamos dizer que você está olhando para comentários on-line para determinar se você quer comprar cereais da vida (não me pergunte por que). Você primeiro vai ler a crítica, em seguida, determinar se alguém pensou que era bom ou se era mau.

Quando você ler a resenha, seu cérebro inconscientemente, só se lembra de palavras-chave importantes. Apanhas palavras como “incrível”e” Pequeno-almoço perfeitamente equilibrado”. Você não se importa muito com palavras como “isto”, “deu”, “tudo”, “deve”, etc. Se um amigo lhe perguntar no dia seguinte o que a crítica disse, você provavelmente não se lembraria dele palavra por palavra. Você pode se lembrar dos pontos principais, embora como “vai definitivamente estar comprando novamente”. Se fores muito parecido comigo, as outras palavras desaparecerão da memória.

E isso é essencialmente o que um LSTM ou GRU faz. Ele pode aprender a manter apenas informações relevantes para fazer previsões, e esquecer dados não relevantes. Neste caso, as palavras que te lembraste fizeram-te julgar que era bom.
revisão das redes neurais recorrentes
para entender como LSTM ou GRU consegue isso, vamos rever a rede neural recorrente. Um RNN funciona assim; as primeiras palavras são transformadas em vetores legíveis por máquina. Em seguida, a RNN processa a sequência de vetores um por um.

Durante o processamento, ele passa o anterior estado de oculto para o próximo passo da seqüência. O estado oculto age como a memória das redes neurais. Ele contém informações sobre dados anteriores que a rede já viu antes.

Vamos olhar para uma célula da RNN para ver como você faria para calcular o estado de oculto. Primeiro, a entrada e o estado oculto anterior são combinados para formar um vetor. Esse vetor agora tem informações sobre a entrada atual e as entradas anteriores. O vetor passa pela ativação tanh, e a saída é o novo estado oculto, ou a memória da rede.

Tanh de ativação
O tanh de ativação é usado para ajudar a regular os valores fluindo através da rede. A função tanh squishes valores para estar sempre entre -1 e 1.

Quando os vetores são flui através de uma rede neural, ele passa por muitas transformações, devido às diversas operações matemáticas. Então imagine um valor que continua a ser multiplicado por digamos 3. Você pode ver como alguns valores podem explodir e se tornar astronômicos, fazendo com que outros valores pareçam insignificantes.

Uma função tanh garante que os valores manter-se entre -1 e 1, regulando, assim, a saída da rede neural. Você pode ver como os mesmos valores de cima permanecem entre os limites permitidos pela função tanh.

Para que um RNN. Tem muito poucas operações internamente, mas funciona muito bem dadas as circunstâncias certas (como sequências curtas). RNN’s uses a lot less computational resources than it’s evolved variants, LSTM’s and GRU’S.
LSTM
An LSTM has a similar control flow as a recurrent neural network. Processa dados que passam informação à medida que se propaga para a frente. As diferenças são as operações dentro das células do LSTM.

Estas operações são utilizadas para permitir que o LSTM para manter ou esquecer informações. Agora, olhando para estas operações pode ficar um pouco esmagador, então vamos rever este passo a passo.
conceito principal
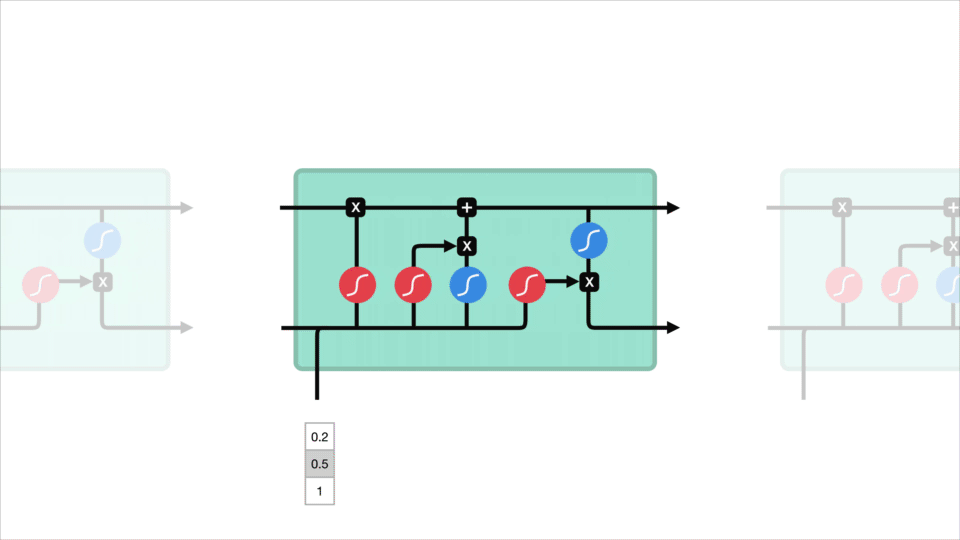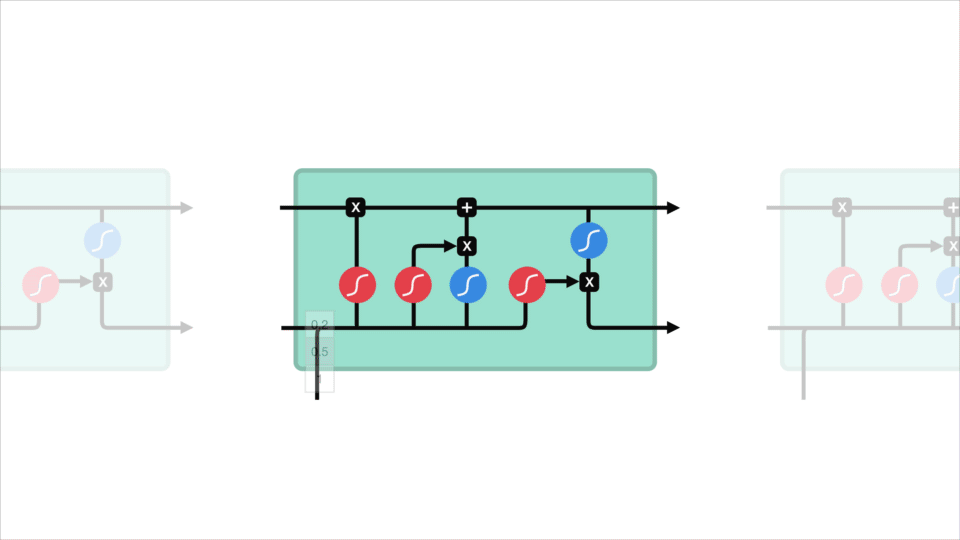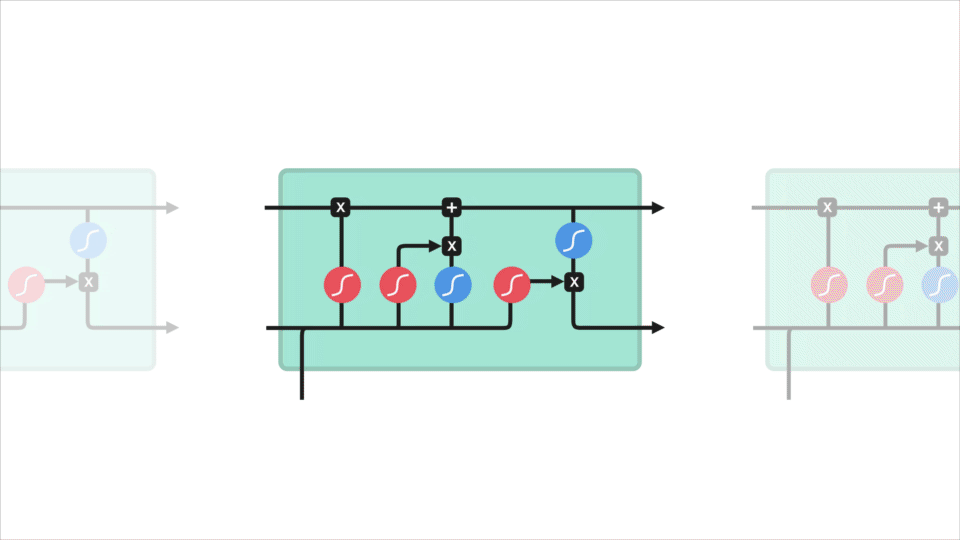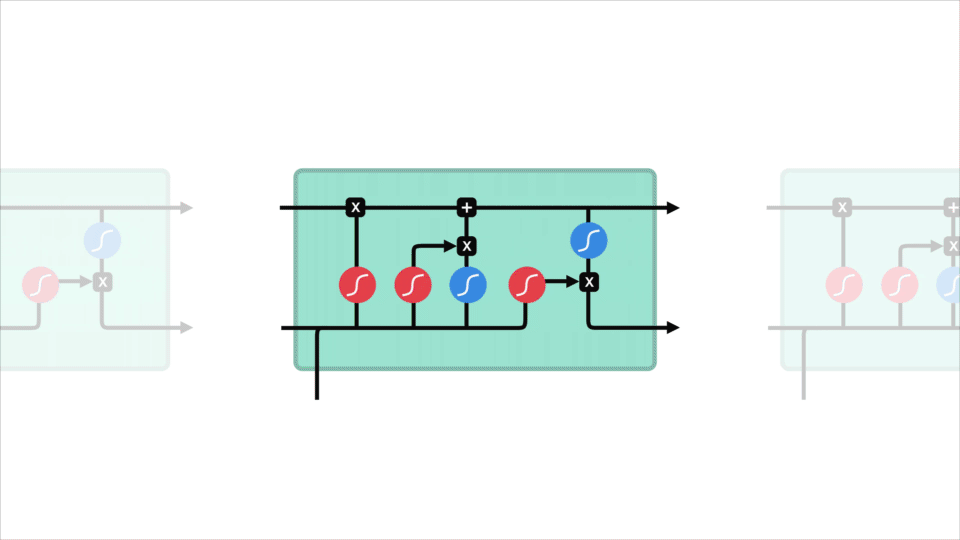
o conceito principal do LSTM é o estado celular, e são vários portões. O estado celular atua como uma rodovia de transporte que transfere informações relativas ao longo de toda a cadeia sequencial. Você pode pensar nisso como a” memória ” da rede. O estado celular, em teoria, pode transportar informações relevantes ao longo do processamento da sequência. Assim, mesmo a informação dos primeiros passos de tempo pode fazer com que seja o caminho para passos de tempo posteriores, reduzindo os efeitos da memória de curto prazo. À medida que o estado celular vai em sua jornada, informações são adicionadas ou removidas para o estado celular via gates. As portas são diferentes redes neurais que decidem quais informações são permitidas no estado celular. Os portões podem aprender Que informações são relevantes para manter ou esquecer durante o treinamento.
Sigmoid
Gates contém activações sigmoid. Uma ativação sigmóide é semelhante à ativação tanh. Em vez de esborrachar valores entre -1 e 1, esmaga valores entre 0 e 1. Isso é útil para atualizar ou esquecer os dados porque qualquer número que se multiplica por 0 é 0, fazendo com que os valores desapareçam ou sejam “esquecidos”.”Qualquer número multiplicado por 1 é o mesmo valor, portanto esse valor permanece o mesmo ou é mantido.”A rede pode aprender quais dados não são importantes, portanto, pode ser esquecido ou quais dados são importantes para manter.

Vamos aprofundar um pouco o que os vários portões estão fazendo, vamos? Então temos três portas diferentes que regulam o fluxo de informação em uma célula LSTM. Um portão esquecido, entrada de entrada e saída de saída.
esqueça a porta
primeiro, temos a porta esquecida. Este portão decide que informações devem ser jogadas fora ou mantidas. A informação do estado oculto anterior e a informação da entrada atual é passada através da função sigmoid. Os valores saem entre 0 e 1. Mais perto de 0 significa esquecer, e mais perto de 1 significa manter.

Portão de entrada
Para atualizar a célula estado, temos o portão de entrada. Primeiro, passamos o estado oculto anterior e a entrada atual para uma função sigmoid. Que decide quais os valores que serão atualizados transformando os valores entre 0 e 1. 0 significa não importante, e 1 significa importante. Você também passa o estado oculto e a entrada atual na função tanh para esmagar valores entre -1 e 1 para ajudar a regular a rede. Então você multiplica a saída de tanh com a saída de sigmoid. A saída sigmoid irá decidir que informação é importante para manter a partir da saída tanh.

Célula de Estado
Agora, vamos ter informação suficiente para calcular a célula estado. Primeiro, o estado celular fica pontualmente multiplicado pelo vetor esquecer. Isto tem a possibilidade de baixar valores no estado da célula se for multiplicado por valores próximos a 0. Então nós pegamos a saída do portal de entrada e fazemos uma adição pontualmente que atualiza o estado da célula para novos valores que a rede neural acha relevantes. Isso dá-nos o nosso novo estado celular.

Saída do Portão
por Último, temos o portão de saída. O portal de saída decide qual deve ser o próximo estado escondido. Lembre-se que o estado escondido contém informações sobre entradas anteriores. O estado oculto também é usado para previsões. Primeiro, passamos o estado oculto anterior e a entrada atual para uma função sigmoid. Depois passamos o estado celular recentemente modificado para a função tanh. Multiplicamos a saída de tanh com a saída de sigmoid para decidir que informação o estado oculto deve levar. A saída é o estado oculto. O novo estado da célula e o novo escondido são então levados para o próximo passo da vez.

Para rever, Esquecer-se do portão decide o que é relevante para manter-se de etapas anteriores. O portal de entrada decide que informações são relevantes para adicionar a partir da etapa atual. O portal de saída determina qual deve ser o próximo estado escondido.
Demo de código
para aqueles de vocês que entendem melhor ao ver o código, aqui está um exemplo usando o pseudo código python.

1. Primeiro, o estado oculto anterior e a entrada atual ficam concatenados. Vamos chamar-lhe combine.
2. O combine get é alimentado na camada de esquecimento. Esta camada remove dados não relevantes.
4. Uma camada candidata é criada usando o combine. O candidato possui valores possíveis para adicionar ao estado da célula.
3. Combinar também o get é alimentado na camada de entrada. Esta camada decide que dados do candidato devem ser adicionados ao novo estado da célula.
5. Depois de computar a camada esquecida, a camada candidata e a camada de entrada, o estado celular é calculado usando esses vetores e o estado celular anterior.
6. A saída é então computada.
7. Multiplicando pontualmente a saída e o novo estado da célula nos dá o novo estado oculto.é isso! O fluxo de controle de uma rede LSTM são algumas operações tensoras e um para loop. Você pode usar os Estados escondidos para previsões. Combinando todos esses mecanismos, um LSTM pode escolher qual a informação relevante para lembrar ou esquecer durante o processamento sequencial.
GRU
então agora sabemos como um LSTM funciona, vamos olhar brevemente para o GRU. O GRU é a nova geração de redes neurais recorrentes e é muito semelhante a um LSTM. O GRU livrou-se do estado da célula e usou o estado escondido para transferir informações. Ele também tem apenas dois portões, um portão de reset e Portão de atualização.

Atualização de Gate
A atualização portão de atos semelhantes a esquecer e portão de entrada de uma LSTM. Decide que informações deitar fora e que novas informações acrescentar.
Reset Gate
The reset gate is another gate is used to decide how much past information to forget.e isso é um GRU. A GRU tem menos operações tensoras.; portanto, eles são um pouco mais rápidos para treinar então LSTM’s. Não há um vencedor claro qual é melhor. Pesquisadores e engenheiros geralmente tentam determinar qual trabalha melhor para o seu caso de uso.
de modo que é isso
para resumir isso, RNN’s são bons para o processamento de dados de sequência para previsões, mas sofre de memória de curto prazo. LSTM’s e GRU’s foram criados como um método para mitigar memória de curto prazo usando mecanismos chamados gates. Os portões são apenas redes neurais que regulam o fluxo de informação que flui através da cadeia de sequência. LSTM’s e GRU’s são usados em aplicações de aprendizagem profunda de última geração como reconhecimento de fala, síntese de fala, compreensão de linguagem natural, etc.
Se você está interessado em ir mais fundo, Aqui estão links de alguns recursos fantásticos que podem dar-lhe uma perspectiva diferente na compreensão do LSTM e do GRU. este post foi fortemente inspirado por eles.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/