VMware High Availability (HA) is a utility that eliminates the need for dedicated standby hardware and software in a virtualized environment. VMware HA é muitas vezes usado para melhorar a confiabilidade, diminuir o tempo de inatividade em ambientes virtuais e melhorar a recuperação de desastres/continuidade de negócios.este capítulo excerpt do Vcp4 Exam Cram: VMware Certified Professional, 2nd Edition by Elias Khnaser explora as melhores práticas do VMware HA.
VMware a alta disponibilidade lida principalmente com falha de host ESX/ESXi e o que acontece com as máquinas virtuais (VMs) que estão rodando neste host. HA também pode monitorar e reiniciar um VM, verificando se as ferramentas de VMware ainda estão em execução. Quando um host ESX / ESXi falha por qualquer razão, todos os VMs em execução também falham. O VMware HA garante que o VMs da máquina falhada é capaz de ser reiniciado em outras máquinas ESX/ESXi.
muitas pessoas confundem erroneamente VMware HA com tolerância a falhas. VMware HA não é tolerante a falta em que se um host falha, o VMs sobre ele também falhar. HA trata apenas de reiniciar esses VMs em outros hosts ESX/ESXi com recursos suficientes. A tolerância à falha, por outro lado, proporciona acesso ininterrupto aos recursos em caso de falha do hospedeiro.
 clique na imagem da capa do livro acima para baixar o capítulo inteiro de Elias Khnaser sobre backup e alta disponibilidade.
clique na imagem da capa do livro acima para baixar o capítulo inteiro de Elias Khnaser sobre backup e alta disponibilidade.VMware HA mantém um canal de comunicação com todos os outros hospedeiros ESX/ESXi que são membros do mesmo grupo usando um batimento cardíaco que envia a cada 1 segundo em vSphere 4.0 ou a cada 10 segundos em vSphere 4.1 por padrão. Quando um servidor ESX falha um batimento cardíaco, as outras máquinas esperam 15 segundos para a outra máquina responder novamente. Após 15 segundos, o cluster inicia o reinício do VMs no hospedeiro ESX/ESXi falhando nos restantes hosts ESX/ESXi no cluster. VMware HA também monitora constantemente os hosts ESX / ESXi que são membros do cluster e garante que os recursos estão sempre disponíveis para satisfazer os requisitos em caso de falha do host.
A monitorização da falha da máquina Virtual
a monitorização da falha da máquina Virtual é uma tecnologia que está desactivada por omissão. Sua função é monitorar máquinas virtuais, que ele questiona a cada 20 segundos através de um batimento cardíaco. Ele faz isso usando as ferramentas VMware que estão instaladas dentro da VM. Quando um VM falha um batimento cardíaco, o VMware HA considera que este VM falhou e tenta reiniciá-lo. Pense no monitoramento de falhas de máquina Virtual como uma espécie de alta disponibilidade para VMs.
Virtual Machine Failure Monitoring can detect whether a virtual machine was manually powered off, suspended, or migrated, and thereby does not attempt to restart it.
os pré-requisitos de configuração do VMware HA
HA requer os seguintes pré-requisitos de configuração antes de poder funcionar correctamente:
- vCenter: dado que o VMware HA é uma funcionalidade de classe empresarial, necessita do vCenter antes de poder ser activado.resolução DNS: todos os hospedeiros ESX/ESXi que são membros do aglomerado HA devem ser capazes de resolver uns aos outros usando DNS.
- acesso ao armazenamento compartilhado: todos os hosts no aglomerado HA devem ter acesso e visibilidade ao mesmo armazenamento compartilhado; caso contrário, eles não teriam acesso ao VMs.acesso à mesma rede: Todas as máquinas ESX / ESXi devem ter as mesmas redes configuradas em todas as máquinas de modo que quando um VM é reiniciado em qualquer máquina, ele novamente tem acesso à rede correta.
redundância da consola de Serviço
a prática recomendada dita que a consola de Serviço (SC) tem redundância. VMware HA reclama e emite um aviso se detectar que o Console de serviço é configurado em um vSwitch com apenas um vmnic. Como mostra a Figura 1, você pode configurar a redundância da consola de Serviço de uma de duas maneiras:
- crie dois grupos de porta da consola de Serviço, cada um em uma vSwitch diferente.
- atribuir duas placas de interface de rede física (NICs) na forma de uma equipe NIC para a consola de Serviço vSwitch.
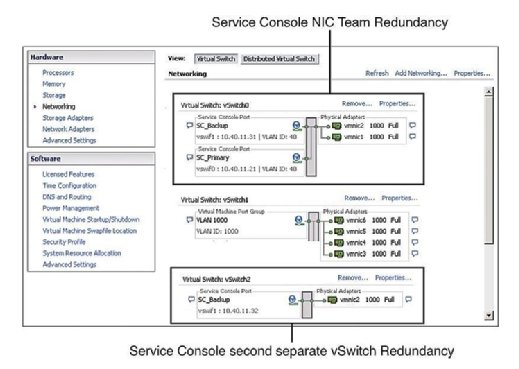
em ambos os casos, você precisa configurar toda a pilha de IP com endereço IP, sub-rede e gateway. Os vSwitches da consola de Serviço são usados para batimentos cardíacos e sincronização de estado e usar as seguintes portas:
- Entrada de porta TCP 8042
- Entrada de porta UDP 8045
- a porta de Saída TCP 2050
- UDP de Saída porta de 2250
- Entrada de porta TCP 8042-8045
- Entrada de porta UDP 8042-8045
- a porta de Saída TCP 2050-2250
- UDP de Saída porta 2050-2250
Falha ao configurar SC redundância resulta em uma mensagem de aviso quando você ativar HA. Assim, para evitar ver esta mensagem de erro e aderir às melhores práticas, configure o SC para ser redundante.
planeamento da capacidade de falha da máquina
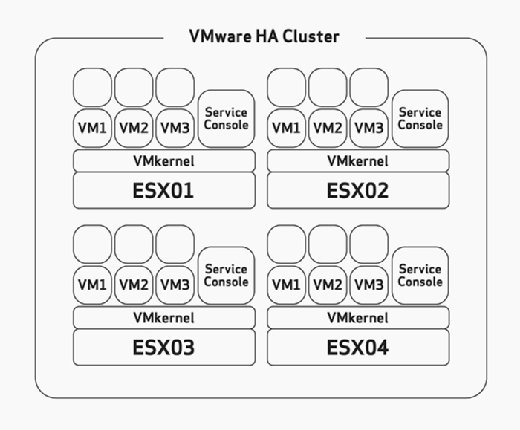
ao configurar o HA, terá de configurar manualmente a tolerância máxima de falha da máquina. Esta é uma tarefa que você deve considerar cuidadosamente durante a fase de dimensionamento de hardware e planejamento de sua implantação. Isto assumiria que você construiu seus hosts ESX/ESXi com recursos suficientes para executar mais VMs do que o planejado para ser capaz de acomodar HA. Por exemplo, na Figura 2, observe que o aglomerado HA tem quatro hosts ESX e que todos esses quatro hosts têm capacidade suficiente para executar pelo menos mais três VMs. Porque eles já estão todos executando três VMs, isso significa que este conjunto pode dar ao luxo da perda de dois hosts ESX/ESXi porque os dois restantes hosts ESX/ESXi pode energia sobre os seis VMs falhados, sem problema se a falha ocorrer.
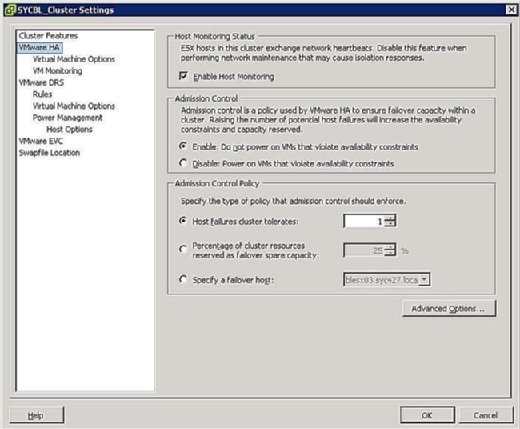
Durante a fase de configuração do cluster HA, você é apresentado com uma tela semelhante à mostrada na Figura 3 que solicita que você defina dois clusterwide configurações da seguinte forma:
- Estado de monitorização da máquina:
- Permite a monitorização da máquina: Esta configuração permite-lhe controlar se o aglomerado HA deve monitorizar as máquinas para um batimento cardíaco. Esta é a maneira do cluster de determinar se um hospedeiro ainda está ativo. Em alguns casos, quando você está executando tarefas de manutenção em máquinas ESX/ESXi, pode ser desejável desativar esta opção para evitar o isolamento de um host.
- controlo de admissão:
- activar: não usar VMs que violem restrições de disponibilidade: A seleção desta opção indica que se não houver recursos disponíveis para satisfazer uma VM, ela não deve ser ligada.
- desactive: potência em VMs que violam as restrições de disponibilidade: Se seleccionar esta opção, indica que deverá usar uma VM mesmo que tenha de usar recursos demasiado avulsos.
- Política de controlo de admissão:
- clusters de falhas da máquina tolera: esta opção permite-lhe configurar quantas falhas da máquina deseja tolerar. As configurações permitidas são de 1 a 4.percentagem de recursos de cluster reservados como capacidade não utilizada: A seleção desta opção indica que você está reservando uma porcentagem do total de recursos do cluster em reserva para failover. Em um grupo de quatro hospedeiros, uma reserva de 25% indica que você está reservando um host completo para failover. Se você quiser deixar de lado menos, você pode escolher 10% dos recursos do cluster em vez disso.
- indique uma máquina de ‘failover’: se seleccionar esta opção, indica que está a Seleccionar uma máquina em particular como a máquina de ‘failover’ no conjunto. Este pode ser o caso se você tem um host sobressalente ou tem um host particular que tem significativamente mais recursos de computação e memória disponíveis.
Host isolamento
Uma rede fenômeno conhecido como split-brain ocorre quando o anfitrião ESX/ESXi parou de receber uma pulsação do resto do cluster. O batimento cardíaco é questionado por cada segundo em vSphere 4.0 ou 10 segundos em vSphere 4.1. Se uma resposta não é recebida, o cluster acha que o hospedeiro ESX/ESXi falhou. Quando isso ocorre, o host ESX/ESXi perdeu sua conectividade de rede em sua interface de gerenciamento. O host pode ainda estar em funcionamento e o VMs pode nem mesmo ser afetado, considerando que eles podem estar usando uma interface de rede diferente que não foi afetado. No entanto, a vSphere precisa tomar medidas quando isso acontece porque acredita que um hospedeiro falhou. Já agora, a resposta de isolamento do hospedeiro foi criada. A resposta de isolamento do Host é a forma de HA lidar com um host ESX/ESXi que perdeu sua conexão de rede.
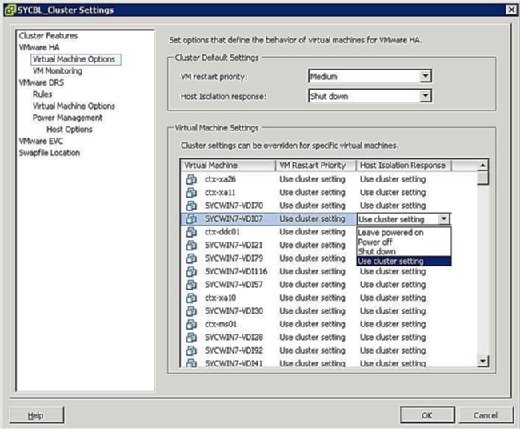
Você pode controlar o que acontece com VMs no caso de um isolamento host. Para chegar à tela de Resposta de isolamento VM, clique com o botão direito no conjunto em questão e clique em Editar Configurações. Você pode então clicar em Opções de máquina Virtual sob o banner VMware HA na área esquerda. Você pode controlar as opções clusterwide definindo a opção de resposta de isolamento do host de acordo. Isto é aplicado a todos os VMs no host afetado. Dito isto, você pode sempre anular as configurações do conjunto definindo uma resposta diferente no nível VM.
Como mostrado na Figura 4, as suas opções de Resposta de isolamento são as seguintes:
- deixar ligado: como o rótulo implica, esta opção significa que, em caso de isolamento da máquina, o VM permanece ligado.
- potência desligada: esta configuração define que, em caso de isolamento, a VM é desligada. Isto é uma falha de energia.
- desligar: esta configuração define que, no caso de um isolamento, a VM é desligada graciosamente usando ferramentas VMware. Se esta tarefa não for concluída com sucesso dentro de cinco minutos, a energia é imediatamente executada. Se as ferramentas de VMware não estiverem instaladas, será executado um desligamento de energia.
- usar a configuração de aglomerado: esta configuração encaminha a tarefa para a configuração de conjunto definida na janela mostrada anteriormente na Figura 4.
In the event of an isolation, this does not necessarily mean that the host is down. Como o VMs pode ser configurado com diferentes NICs físicos e conectado a diferentes redes, eles podem continuar a funcionar corretamente; você, portanto, tem que considerar isso ao definir a prioridade para o isolamento. Quando um host é isolado, isso simplesmente significa que seu Console de Serviço não pode se comunicar com o resto dos hosts ESX/ESXi no cluster.
virtual machine recovery priority
Should your HA cluster not be able to accommodate all the VMs in the event of a failure, you have the ability to priorize on VMs. As prioridades determinam quais VMs são reiniciados em primeiro lugar e quais VMs não são tão importantes em caso de emergência. Estas opções são configuradas na mesma tela que a resposta de isolamento coberta na seção anterior. Poderá configurar as opções de clusterwide que serão aplicadas a todos os VMs da máquina afectada, ou poderá substituir as opções do conjunto configurando uma substituição ao nível VM.
pode definir a prioridade de reinício de uma VM como uma das seguintes:
- alta: os VMs com alta prioridade são reiniciados primeiro.
- Médio: esta é a configuração padrão.
- baixo: VMs com baixa prioridade são reiniciados por último.
- usar a configuração de aglomerado: os VMs são reiniciados com base na configuração definida no nível de aglomerado definido na janela mostrada na figura abaixo.
- desactivado: a VM não está ligada.
a prioridade deve ser definida com base na importância do VMs. Por outras palavras, poderá querer reiniciar os controladores de domínio e não reiniciar os servidores de impressão. As máquinas virtuais de maior prioridade são reiniciadas primeiro. O VMs que pode tolerar o desligamento em caso de emergência deve ser configurado para permanecer desligado para conservar os recursos.
clustering MSCS
o principal objectivo de um cluster é garantir que os sistemas críticos permaneçam online A qualquer custo e a qualquer momento. Semelhantes a máquinas físicas que podem ser agrupados, máquinas virtuais também podem ser agrupados com ESX usando três diferentes cenários:
- Cluster-in-a-box: neste cenário, todas as VMs que fazem parte do cluster residem no mesmo anfitrião ESX/ESXi. Como você deve ter adivinhado, isso imediatamente cria um único ponto de falha: o host ESX/ESXi. No que diz respeito ao armazenamento compartilhado, você pode usar discos virtuais como armazenamento compartilhado neste cenário, ou você pode usar o mapeamento de dispositivos Raw (RDM) no modo de compatibilidade virtual.
- Cluster-em-caixas: neste cenário, os nós de cluster (VMs que são membros do cluster), residir em vários ESX/ESXi exércitos, segundo a qual cada um de nós que compõem o cluster pode acessar o mesmo armazenamento, de modo que se uma VM falhar, o outro pode continuar a funcionar e acessar os mesmos dados. Este cenário cria um ambiente de cluster ideal, eliminando um único ponto de falha. O armazenamento compartilhado é um pré-requisito e deve residir no Fibre Channel SAN. Você também deve usar um RDM em Modo de compatibilidade física ou Virtual como os discos virtuais não são uma configuração suportada para armazenamento compartilhado. Em que cada um dos nós que compõem o conjunto pode acessar o mesmo armazenamento de modo que, se um VM falhar, o outro pode continuar a funcionar e acessar os mesmos dados.cluster físico-virtual: Neste cenário, um membro do cluster é uma máquina virtual, enquanto o outro membro é uma máquina física. O armazenamento compartilhado é um pré-requisito neste cenário e deve ser configurado como um RDM em Modo de compatibilidade física.
sempre que estiver a desenhar uma solução de agrupamento, terá de abordar a questão do armazenamento partilhado, o que permitiria a vários servidores ou VMs aceder aos mesmos dados. vSphere oferece vários métodos pelos quais você pode fornecer armazenamento compartilhado da seguinte forma:
- discos virtuais: Você pode usar um disco virtual como uma área de armazenamento compartilhada apenas se você estiver fazendo agrupamento em uma caixa — em outras palavras, apenas se ambos VMs residem na mesma máquina ESX/ESXi.
- RDM no modo de compatibilidade física: este modo permite-lhe ligar um LUN físico directamente a uma VM ou máquina física. Este modo impede que você use funcionalidades como instantâneos e é idealmente usado quando um membro do cluster é uma máquina física, enquanto o outro é um VM.
- RDM no modo de compatibilidade Virtual: este modo permite-lhe anexar um LUN físico directamente a uma VM ou máquina física. Este modo dá-lhe todos os benefícios dos discos virtuais em execução em VMFS, incluindo instantâneos e bloqueio avançado de ficheiros. O disco é acessado através do hypervisor e é ideal ao configurar um cenário de cluster-across-boxes onde você precisa dar a ambos VMs acesso ao armazenamento compartilhado.
na altura desta escrita, o único serviço de clustering suportado pelo VMware é o Microsoft Clustering Services (MSCS). Você pode consultar o VMware white paper ” Setup for Failover Clustering and Microsoft Cluster Service.”
VMware Fault Tolerance
VMware Fault Tolerance (FT) é outra forma de clustering VM desenvolvido pela VMware para sistemas que requerem tempo de funcionamento extremo. Uma das características mais convincentes da FT é a sua facilidade de instalação. FT é simplesmente uma opção que pode ser ativada. Em comparação com o clustering tradicional que requer configurações específicas e, em alguns casos, cabeamento, FT é simples, mas poderoso.como funciona?
ao proteger VMs com FT, um VM secundário é criado em lockstep do VM protegido, o primeiro VM. A FT trabalha escrevendo simultaneamente para a primeira VM e a segunda VM ao mesmo tempo. Cada tarefa é escrita duas vezes. Se você clicar no menu Iniciar no primeiro VM, o menu Iniciar no segundo VM também será clicado. O poder do FT é a sua capacidade de manter ambos os VMs em sincronia.
Se a VM protegida deve ir para baixo por qualquer razão, a VM secundária imediatamente toma seu lugar, confiscando sua identidade e seu endereço IP, continuando a usuários de serviço sem uma interrupção. A recém-promovida VM protegida, em seguida, cria um secundário para si em outro hospedeiro e o ciclo recomeça.
para clarificar, vamos ver um exemplo. Se quisesse proteger um servidor de troca, podia activar o FT. Se, por qualquer razão, o hospedeiro ESX/ESXi que transporta o VM protegido falhar, o VM secundário entra em acção e assume as suas funções sem interrupção de serviço.
A tabela abaixo descreve as diferentes tecnologias de alta disponibilidade e agrupamento a que você tem acesso com vSphere e destaca as limitações de cada uma.

Tolerância a Falhas requisitos
a Tolerância a Falhas não é diferente de qualquer outro recurso empresarial que requer alguns pré-requisitos para ser atendidos antes que a tecnologia pode funcionar corretamente e de forma eficiente. Estes requisitos são descritos na seguinte lista e desagregados pelas diferentes categorias que exigem requisitos mínimos específicos:
- requisitos do hospedeiro:
- FT CPU compatível. Assinale este artigo do VMware KB para mais informações.
- a virtualização do Hardware deve ser ativada na bios.as velocidades do relógio do CPU da máquina devem estar a 400 MHz umas das outras.
- requisitos VM:
- VMs deve residir no armazenamento partilhado suportado (FC, iSCSI e NFS).
- VMs deve executar um SO suportado.
- VMs deve ser armazenado em um VMDK ou um RDM virtual.
- VMs não pode ter provisionado VMDK e deve estar usando um disco virtual Eagerzeroedthick.
- VMs não pode ter mais do que um vCPU configurado.Requisitos de Cluster:
- Todas as máquinas ESX / ESXi devem ser a mesma versão e o mesmo nível de patch.todas as máquinas ESX / ESXi devem ter acesso aos datastores e redes VM.
- VMware HA deve ser ativado no conjunto.
- Cada máquina deve ter um NIC de Registo vMotion E FT configurado.a verificação do certificado da máquina
- também deve estar activa.
- activar a verificação do certificado da máquina: Para activar esta opção, ligue-se ao seu servidor de vCenter e carregue na administração do menu ficheiro e carregue na configuração do servidor de vCenter. Na área esquerda, carregue em configuração do SSL e assinale a opção vCenter necessita de Certificados SSL da máquina verificada.
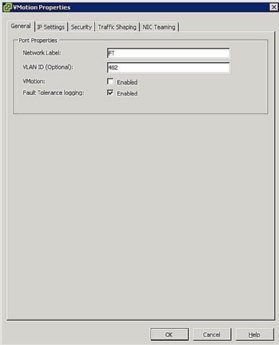
Figure 5. FT Port group settings - Configure Host Networking: A configuração de rede para FT é fácil e segue os mesmos passos e procedimentos que o vMotion, exceto em vez de verificar a caixa de vMotion, assinale a caixa de Registo de tolerância de falhas como mostrado na Figura 5.
- ligando FT e desligando: uma vez que você tenha cumprido os requisitos anteriores, você pode agora ligar FT e desligar para VMs. Este processo também é simples: Encontre o VM que deseja proteger, clique com o botão direito e selecione tolerância de falha>ligue a tolerância de falha.
é altamente aconselhável que, além de verificar a compatibilidade do processador com FT, verifique a compatibilidade do seu servidor com FT com a lista de Compatibilidade de Hardware VMware (HCL).
embora FT seja uma grande solução de agrupamento, é importante notar que ele também tem certas limitações. Por exemplo, FT VMs não pode ser snapshoted, e eles não podem ser armazenados vMotioned. Na verdade, estes VMs serão automaticamente sinalizados DRS-desativados e não participarão de qualquer balanceamento dinâmico de carga de recursos.
como activar o FT
activar o FT não é difícil, mas envolve a configuração de algumas configurações diferentes. A seguinte configuração precisa de ser configurada correctamente para o FT funcionar:
embora FT seja uma tecnologia de clustering de primeira geração, ele funciona de forma impressionante bem e simplifica os métodos tradicionais de construção, configuração e manutenção de clusters. FT é uma tecnologia impressionante para um ponto de vista de tempo de funcionamento e de um ponto de vista de failover sem descontinuidades.