Version info: Code for this page was tested in Stata 12.
Poisson regressão é usada para modelar variáveis de contagem.
Por Favor note: o objetivo desta página é mostrar como usar vários comandos de análise de dados. Não abrange todos os aspectos do processo de investigação que se espera que os investigadores façam. Em especial, não abrange a limpeza e verificação de dados, a verificação de pressupostos, diagnósticos de modelos ou potenciais análises de acompanhamento.
exemplos de regressão de Poisson
exemplo 1. O número de pessoas mortas por mulas ou chutes de cavalo no exército prussiano por ano.Ladislaus Bortkiewicz coletou dados de 20 volumes depreussischen Statistik. Estes dados foram coletados em 10 corpos do exército prussiano no final de 1800 ao longo de 20 anos.Exemplo 2. O número de pessoas na fila à tua frente na mercearia. Os predictores podem incluir o número de itens atualmente oferecidos a um preço especial com desconto e se um evento especial (por exemplo, um feriado, um grande evento esportivo) está a três ou menos dias de distância.exemplo 3. O número de prêmios conquistados pelos alunos de uma escola secundária. Preditors of the number of awards earned include the type of program in which the student was registrated (e.g., vocational, general or academic) and the score on their final exam in math.
descrição dos dados
para fins de ilustração, simulámos um conjunto de dados para o exemplo 3 acima. Neste exemplo, num_awards é a variável resultado e indica o número de prêmios ganhos por alunos de uma escola secundária em um ano, Matemática é uma variável de previsão contínua e representa as pontuações dos alunos em seu exame final de matemática, e prog é uma variável de predictor categórico com três níveis indicando o tipo de programa em que os alunos foram matriculados.
vamos começar por carregar os dados e olhar para algumas estatísticas descritivas.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
Cada variável tem 200 observações válidas e suas distribuições parece bastante razoável. Neste particular, a média incondicional e variância de nossa variável resultado não são extremamente diferentes.
vamos continuar com a nossa descrição das variáveis neste conjunto de dados. A tabela abaixo mostra o número médio de prêmios por tipo de programa e parece sugerir que o tipo de programa é um bom candidato para prever o número de prêmios, nossa variável resultado, porque o valor médio do resultado parece variar por prog.
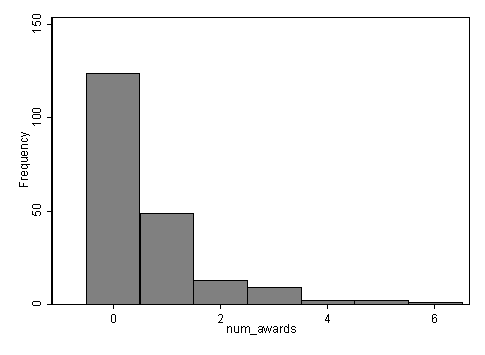
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
métodos de Análise que você pode considerar
Abaixo, está uma lista de alguns métodos de análise que você pode ter encontrado. Alguns dos métodos listados são bastante razoáveis, enquanto outros caíram em favor ou têm limitações.
- Poisson regression-Poisson regression is often used for modeling count data. A regressão de Poisson tem uma série de extensões úteis para modelos de contagem.
- regressão binomial negativa-regressão binomial negativa pode ser usada para dados de contagem sobre-dispersos, ou seja, quando a variância condicional excede a média condicional. Pode ser considerado como uma generalização da regressão de Poisson uma vez que tem a mesma estrutura média que a regressão de Poisson e tem um parâmetro extra para modelar a dispersão excessiva. Se a distribuição condicional da variável resultado for excessivamente dispersa, é provável que os intervalos de confiança para a regressão binomial negativa sejam mais estreitos em comparação com os de uma regressão de Poisson.
- modelo de regressão inflacionado a Zero-modelos inflacionados a Zero tentam explicar o excesso de zeros. Em outras palavras, pensa-se que existem dois tipos de zeros nos dados, “zeros verdadeiros” e “zeros excessivos”. Modelos de inflação Zero estimam duas equações simultaneamente, uma para o modelo de contagem e uma para os zeros em excesso.
- OLS regression – Count outcome variables are sometimes log-transformed and analyzed using OLS regression. Muitas questões surgem com esta abordagem, incluindo a perda de dados devido a valores indefinidos gerados pela tomada do log de zero (que é indefinido) e estimativas tendenciosas.
regressão de Poisson
abaixo usamos o comando de poisson para estimar um modelo de regressão de Poisson. O I. before prog indica que é um fator variável (i.e., variável categórica), e que deve ser incluído no modelo como uma série de variáveis indicadoras.
usamos a opção vce (robusta) para obter erros padrão robustos para as estimativas de parâmetros, como recomendado por Cameron e Trivedi (2009) para controlar a leve violação dos pressupostos subjacentes.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
o teste Qui-quadrado de dois graus de liberdade indica que o prog, tomado em conjunto, é um preditor estatisticamente significativo de num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
Para ajudar a avaliar o ajuste do modelo, o estat gof comando pode ser usado para obter o goodness-of-fit teste qui-quadrado. Este não é um teste dos coeficientes do modelo (que vimos na informação do cabeçalho), mas um teste do formulário do modelo: o formulário do modelo poisson se encaixa em nossos dados?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
Podemos concluir que o modelo se ajusta razoavelmente bem, porque a bondade de ajuste teste qui-quadrado não é estatisticamente significativa. Se o teste tivesse sido estatisticamente significativo, indicaria que os dados não se encaixam bem com o modelo. Nessa situação, podemos tentar determinar se há variáveis predictor omitidas, se a nossa hipótese de linearidade se mantém e/ou se há uma questão de dispersão excessiva. por vezes, podemos querer apresentar os resultados de regressão como rácios de taxa de incidentes, podemos usar a opção deles. Estes valores de IRR são iguais aos nossos coeficientes a partir da saída acima exponenciada.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
A saída acima indica que o incidente taxa para 2.o prog é 2,96 vezes a taxa de incidentes para o grupo de referência (1.programa). Da mesma forma, a taxa de incidentes para 3.prog é 1,45 vezes a taxa de incidente para o grupo de referência que mantém as outras variáveis constantes. A variação percentual na taxa de incidente de num_awards é um aumento de 7% para cada aumento de unidade em matemática.Recall the form of our model equation:
log(num_awards) = Intercept + b1(prog=2) + b2(prog=3) + b3math.
Isto implica:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
Os coeficientes de ter um efeito aditivo no log(y) escala e a TIR tem um efeito multiplicativo na y escala.
para informações adicionais sobre as várias métricas em que os resultados podem ser apresentados, e a interpretação de tais, Por favor, Veja Modelos de regressão para variáveis categóricas dependentes usando Stata, Segunda Edição por J. Scott Long e Jeremy Freese (2006).
para entender melhor o modelo, Podemos usar o comando margens. Abaixo, usamos o comando margens para calcular as contagens previstas em cada nível deprog, mantendo todas as outras variáveis (neste exemplo, matemática) no modelo em seus valores médios.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
na saída acima, vemos que o número previsto de eventos para o Nível 1 de prog é cerca de .21, mantendo a matemática à sua média. O número previsto de eventos para o Nível 2 de prog é maior em .62, e o número previsto de eventos para o Nível 3 de prog é de cerca de .31. Note que a contagem prevista do nível 2 de prog é (.6249446/.211411) = 2,96 vezes maior que a contagem prevista para o Nível 1 de prog. Isto corresponde ao que vimos na tabela de saída da TIR.abaixo obteremos as contagens previstas para valores matemáticos que variam de 35 a 75 em incrementos de 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
a tabela acima mostra que com prog em seus valores observados e matemática realizada em 35 para todas as observações, a contagem média prevista (ou número médio de prêmios) é de cerca de .13; quando matemática = 75, a contagem média prevista é de cerca de 2,17. Se compararmos as contagens previstas em matemática = 35 e matemática = 45, podemos ver que a razão é (.2644714/.1311326) = 2.017. Isto corresponde à IRR de 1.0727 para uma mudança de 10 unidades: 1.0727^10 = 2.017.
o comando fitstat escrito pelo Utilizador (bem como os comandos estadat do Stata) pode ser usado para obter informações adicionais que podem ser úteis se quiser comparar modelos. Você pode digitar o fitstat search para baixar este programa (Veja Como posso usar o comando search para procurar programas e obter ajuda adicional? para mais informações sobre o uso da pesquisa).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
você pode gráfico o número previsto de eventos com os comandos abaixo. O grafo indica que a maioria dos prêmios são previstos para aqueles no programa acadêmico (prog = 2), especialmente se o aluno tem uma pontuação de matemática alta. O menor número de prêmios previstos é para aqueles estudantes no programa geral (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
Coisas a considerar
- Se overdispersion parece ser um problema, devemos primeiramente verificar se o nosso modelo é adequadamente especificado, tais como variáveis omitidas e formas funcionais. Por exemplo, se omitirmos a variável predictor progin o exemplo acima, nosso modelo pareceria ter um problema com a dispersão excessiva. Em outras palavras, um modelo mal especificado poderia apresentar um sintoma como um problema de dispersão excessiva.
- assumindo que o modelo está correctamente especificado, poderá querer verificar se há dispersão. Existem várias maneiras de fazer isso, incluindo o teste da relação de probabilidade do parâmetro de dispersão Alfa, rodando o mesmo modelo de regressão usando distribuição binomial negativa (nbreg). uma causa comum de dispersão excessiva é o excesso de zeros, que por sua vez são gerados por um processo adicional de geração de dados. Nesta situação, deve considerar-se o modelo com inflação zero.
- Se o processo gerador de dados não permite qualquer 0s (como o número de dias passados no hospital), então um modelo zero truncado pode ser mais apropriado.os dados de contagem de
- têm frequentemente uma variável de exposição, o que indica o número de vezes que o evento poderia ter acontecido. Esta variável deve ser incorporada num modelo Poisson com a utilização da opção exp ().
- a variável de resultado numa regressão de Poisson não pode ter números negativos, e a exposição não pode ter 0s.
- No Stata, um modelo de Poisson pode ser estimado através do comando glm com a ligação de log e a família Poisson.
- terá de usar o comando glm para obter os resíduos para verificar outros pressupostos do modelo Poisson (ver Cameron e Trivedi (1998) e Dupont (2002) para mais informações).existem muitas medidas diferentes de pseudo-R-quadrado. Todos eles tentam fornecer informações semelhantes às fornecidas pelo R-quadrado na regressão OLS, embora nenhum deles possa ser interpretado exatamente como R-quadrado na regressão OLS é interpretado. Para uma discussão de vários pseudo-R-squares, veja Long e Freese (2006) ou nossa página FAQ O que são pseudo-R-squareds?.a regressão de Poisson é estimada através da estimativa máxima da probabilidade. Normalmente requer um grande tamanho de amostra.
Ver também
- resultado anotado para o comando poisson
- FAQ Stata: Como posso usar countfit na escolha de um modelo de contagem?como são calculados os erros padrão e os intervalos de confiança para as taxas de incidência (irritações) por poisson e nbreg?
- Cameron, A. C. and Trivedi, P. K. (2009). Microeconomia Usando Stata. College Station, TX: Stata Press.Cameron, A. C. and Trivedi, P. K. (1998). Análise de regressão dos dados de contagem. New York: Cambridge Press.Cameron, A. C. Advances in Count Data Regression Talk for the Applied Statistics Workshop, March 28, 2009.http://cameron.econ.ucdavis.edu/racd/count.html .
- Dupont, W. D. (2002). Statistical Modeling for Biomedical Researchers: a Simple Introduction to the Analysis of Complex Data. New York: Cambridge Press.Long, J. S. (1997). Modelos de regressão para variáveis dependentes categóricas e limitadas.Thousand Oaks, CA: Sage Publications.Long, J. S. and Freese, J. (2006). Modelos de regressão para variáveis categóricas dependentes usando Stata, segunda edição. College Station, TX: Stata Press.