ce este învățarea întăririi?
învățarea prin armare este definită ca o metodă de învățare automată care se referă la modul în care agenții software ar trebui să ia măsuri într-un mediu. Învățarea prin întărire este o parte a metodei de învățare profundă care vă ajută să maximizați o parte din recompensa cumulativă.
această metodă de învățare a rețelei neuronale vă ajută să învățați cum să atingeți un obiectiv complex sau să maximizați o dimensiune specifică pe mai mulți pași.
în tutorial de învățare armare, veți învăța:
- ce este de învățare armare?
- termeni importanți utilizați în metoda de învățare a întăririi profunde
- cum funcționează învățarea întăririi?
- algoritmi de învățare de armare
- caracteristicile învățării de armare
- tipuri de învățare de armare
- modele de învățare de armare
- învățare de armare vs. învățare supravegheată
- aplicații ale învățării de armare
- de ce să folosiți învățarea de armare?
- când să nu folosiți învățarea de întărire?
- provocări ale învățării întăririi
termeni importanți utilizați în metoda de învățare profundă a întăririi
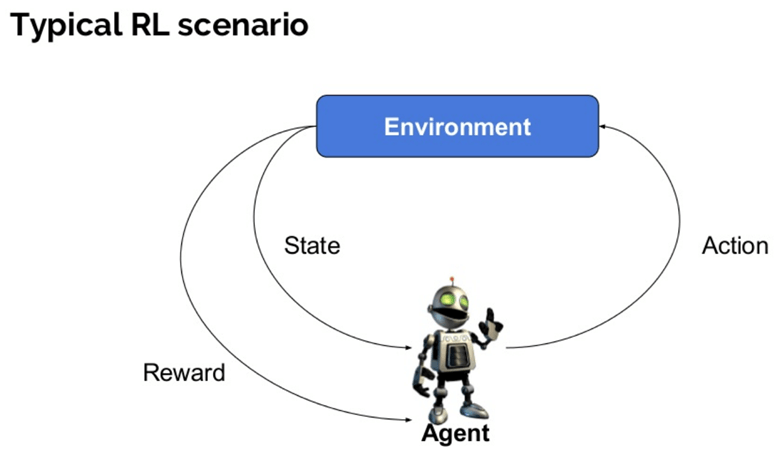
iată câțiva termeni importanți utilizați în întărirea AI:
- agent: este o entitate asumată care efectuează acțiuni într-un mediu pentru a obține o anumită recompensă.
- Mediu (e): un scenariu cu care trebuie să se confrunte un agent.
- recompensa (R): O întoarcere imediată dat la un agent atunci când el sau ea efectuează o anumită acțiune sau sarcină.
- Stat (E): stat se referă la situația actuală a revenit de mediu.
- Politica (?): Este o strategie care se aplică de către agent pentru a decide următoarea acțiune bazată pe starea actuală.
- valoare (V): este de așteptat întoarcere pe termen lung cu discount, în comparație cu recompensa pe termen scurt.
- funcție de valoare: specifică valoarea unei stări care este suma totală a recompensei. Este un agent care ar trebui să fie așteptat începând de la acel stat.
- Modelul mediului: aceasta imită comportamentul mediului. Vă ajută să faceți inferențe și, de asemenea, să determinați cum se va comporta mediul.
- metode bazate pe Model: este o metodă pentru rezolvarea problemelor de învățare de întărire care utilizează metode bazate pe model.
- valoarea Q sau valoarea acțiunii (Q): valoarea Q este destul de similară cu valoarea. Singura diferență dintre cele două este că este nevoie de un parametru suplimentar ca acțiune curentă.
cum funcționează învățarea prin întărire?
să vedem un exemplu simplu care vă ajută să ilustrați mecanismul de învățare a întăririi.
luați în considerare scenariul de a învăța noi trucuri pisicii dvs.
- deoarece pisica nu înțelege engleza sau orice altă limbă umană, nu îi putem spune direct ce să facă. În schimb, urmăm o strategie diferită.
- imităm o situație, iar pisica încearcă să răspundă în mai multe moduri diferite. Dacă răspunsul pisicii este modul dorit, îi vom da pește.
- acum, ori de câte ori pisica este expusă aceleiași situații, pisica execută o acțiune similară cu și mai mult entuziasm în așteptarea obținerii mai multor recompense(mâncare).
- este ca și cum ai învăța că pisica primește de la” ce să facă ” din experiențe pozitive.
- în același timp, pisica învață și ce nu face atunci când se confruntă cu experiențe negative.
explicație despre exemplu:
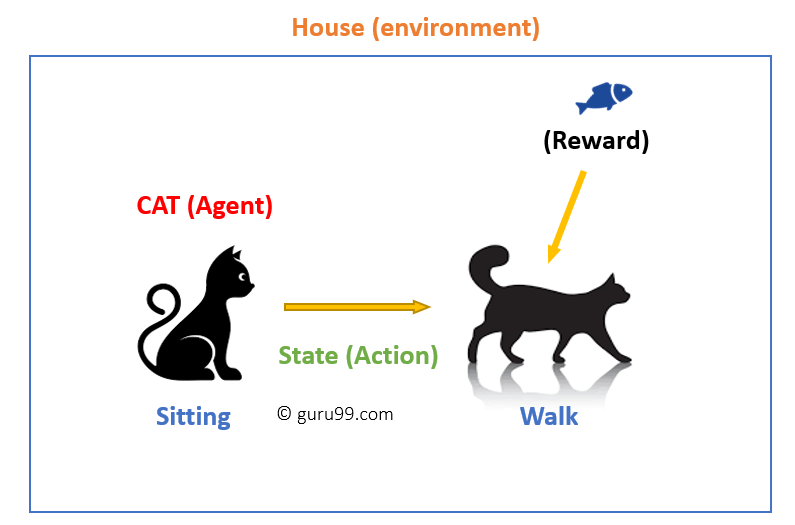
în acest caz,
- pisica dvs. este un agent care este expus mediului. În acest caz, este casa ta. Un exemplu de stare ar putea fi pisica ta așezată și folosești un cuvânt specific pentru ca pisica să meargă.
- agentul nostru reacționează efectuând o tranziție de acțiune de la o „stare” la alta „stare.”
- de exemplu, pisica ta trece de la ședință la mers. reacția unui agent este o acțiune, iar politica este o metodă de selectare a unei acțiuni date unei stări în așteptarea unor rezultate mai bune.
- după tranziție, ei pot primi o recompensă sau o penalizare în schimb.
algoritmi de învățare de armare
există trei abordări pentru a implementa un algoritm de învățare de armare.
bazat pe valoare:
într-o metodă de învățare bazată pe valoare, ar trebui să încercați să maximizați o funcție de valoare V(s). În această metodă, agentul se așteaptă la o revenire pe termen lung a statelor actuale în cadrul politicii ?.
bazat pe politici:
într-o metodă RL bazată pe politici, încercați să veniți cu o astfel de politică încât acțiunea efectuată în fiecare stat vă ajută să obțineți o recompensă maximă în viitor.
două tipuri de metode bazate pe politici sunt:
- deterministe: pentru orice stat, aceeași acțiune este produsă de politică ?.
- Stochastic: fiecare acțiune are o anumită probabilitate, care este determinată de următoarea ecuație.Politica stocastică:
n{a\s) = P\A, = a\S, =S]
bazată pe Model:
În această metodă de învățare de armare, trebuie să creați un model virtual pentru fiecare mediu. Agentul învață să efectueze în acel mediu specific.
caracteristicile învățării de armare
aici sunt caracteristici importante ale învățării de armare
- nu există nici un supraveghetor, doar un număr real sau semnal de recompensă
- luarea deciziilor secvențiale
- timpul joacă un rol crucial în problemele de armare
- Feedback-ul este întotdeauna întârziat, nu instantaneu
- acțiunile agentului determină datele ulterioare pe care le primește
- procesul de decizie Markov
- q learning
- Set de acțiuni – A
- Set de stări-S
- Reward – R
- Politică – n
- valoare – V
- există cinci camere într-o clădire care sunt conectate prin uși.
- fiecare cameră este numerotată de la 0 la 4
- exteriorul clădirii poate fi o zonă exterioară mare (5)
- ușile numărul 1 și 4 conduc în clădire din camera 5
- ușile care duc direct la obiectiv au o recompensă de 100
- ușile care nu sunt conectate direct la camera țintă oferă recompensă zero
- deoarece ușile sunt bidirecționale și sunt atribuite două săgeți pentru fiecare cameră
- fiecare săgeată din imaginea de mai sus conține o valoare de recompensă instantanee
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
- Robotica pentru automatizari industriale.
- planificarea strategiei de afaceri
- învățarea automată și prelucrarea datelor
- vă ajută să creați sisteme de instruire care să ofere instrucțiuni personalizate și materiale în funcție de cerințele studenților.
- controlul aeronavei și controlul mișcării robotului
- vă ajută să găsiți ce situație are nevoie de o acțiune
- vă ajută să descoperiți care acțiune produce cea mai mare recompensă pe perioada mai lungă.
- învățarea prin întărire oferă, de asemenea, agentului de învățare o funcție de recompensă.
- de asemenea, îi permite să descopere cea mai bună metodă pentru obținerea de recompense mari.
- când aveți suficiente date pentru a rezolva problema cu o metodă de învățare supravegheată
- trebuie să vă amintiți că învățarea prin întărire este dificilă și consumă mult timp. în special atunci când spațiul de acțiune este mare.
- caracteristică/recompensă design care ar trebui să fie foarte implicat
- parametrii pot afecta viteza de învățare.
- mediile realiste pot avea observabilitate parțială.
- prea multă întărire poate duce la o supraîncărcare a stărilor care pot diminua rezultatele.
- mediile realiste pot fi non-staționare.
- învățarea prin armare este o metodă de învățare automată
- vă ajută să descoperiți care acțiune produce cea mai mare recompensă pe perioada mai lungă.
- trei metode de consolidare a învățării sunt 1) bazate pe Valoare 2) învățarea bazată pe politici și Model.
- Agent, de Stat, recompensa, Mediu, Modelul funcției de valoare a mediului, metode bazate pe Model, sunt câțiva termeni importanți folosind în metoda de învățare RL
- exemplul de învățare armare este pisica ta este un agent care este expus la mediul înconjurător.
- cea mai mare caracteristică a acestei metode este că nu există nici un supraveghetor, doar un număr real sau un semnal de recompensă
- două tipuri de învățare de armare sunt 1) pozitive 2) Negative
- două modele de învățare utilizate pe scară largă sunt 1) Procesul de decizie Markov 2) învățarea Q
- metoda de învățare de armare funcționează pe interacțiunea cu mediul, în timp ce metoda de învățare supravegheată funcționează pe date sau exemple date.
- metodele de învățare a aplicațiilor sau întăririlor sunt: Robotica pentru automatizare industrială și planificarea strategiei de afaceri
- nu trebuie să utilizați această metodă atunci când aveți suficiente date pentru a rezolva problema
- cea mai mare provocare a acestei metode este că parametrii pot afecta viteza de învățare
două tipuri de metode de învățare de armare sunt:
pozitiv:
este definit ca un eveniment, care apare din cauza comportamentului specific. Crește puterea și frecvența comportamentului și are un impact pozitiv asupra acțiunii întreprinse de agent.
Acest tip de armare vă ajută să maximizați performanța și să susțineți schimbarea pentru o perioadă mai lungă. Cu toate acestea, prea multă întărire poate duce la supra-optimizarea stării, ceea ce poate afecta rezultatele.
negativ:
întărirea negativă este definită ca întărirea comportamentului care apare din cauza unei condiții negative care ar fi trebuit oprită sau evitată. Aceasta vă ajută să definiți standul minim de performanță. Cu toate acestea, dezavantajul acestei metode este că oferă suficient pentru a satisface comportamentul minim.
modele de învățare a întăririi
există două modele importante de învățare în învățarea întăririi:
procesul de decizie Markov
următorii parametri sunt utilizați pentru a obține o soluție:
abordarea matematică pentru cartografierea unei soluții în învățarea întăririi este recon ca un proces de decizie Markov sau (MDP).
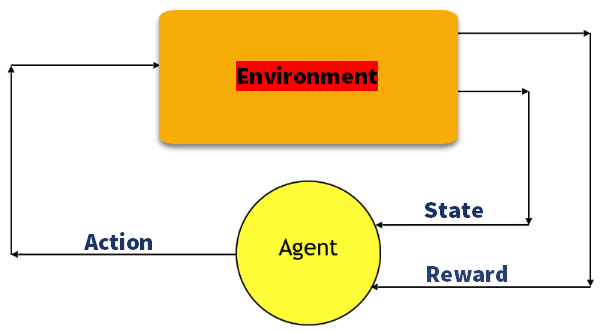
Q-Learning
q learning este o metodă bazată pe valori de furnizare a informațiilor pentru a informa ce acțiune ar trebui să ia un agent.
să înțelegem această metodă prin următorul exemplu:
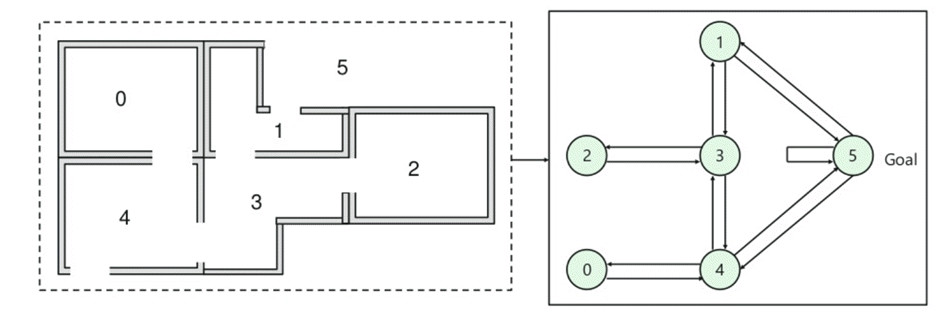
în continuare, trebuie să asociați o valoare de recompensă fiecărei uși:
explicație:
în această imagine, puteți vizualiza acea cameră reprezintă o stare
în imaginea de mai jos, o stare este descrisă ca un nod, în timp ce săgețile arată acțiunea.

For example, an agent traverse from room number 2 to 5
Reinforcement Learning vs. Învățarea supravegheată
| parametri | învățarea prin întărire | învățarea supravegheată |
| stil de decizie | învățarea prin întărire vă ajută să luați deciziile secvențial. | în această metodă, se ia o decizie cu privire la intrarea dată la început. |
| funcționează pe | funcționează pe interacțiunea cu mediul. | funcționează pe exemple sau date de probă date. |
| dependența de decizie | în metoda RL decizia de învățare este dependentă. Prin urmare, ar trebui să dați etichete tuturor deciziilor dependente. | învățare supravegheată deciziile care sunt independente unele de altele, astfel încât etichetele sunt date pentru fiecare decizie. |
| cel mai potrivit | suportă și funcționează mai bine în AI, unde interacțiunea umană este predominantă. | este operat în cea mai mare parte cu un sistem software interactiv sau aplicații. |
| exemplu | joc de șah | recunoaștere obiect |
aplicații de învățare armare
aici sunt aplicații de învățare armare:
de ce să folosiți învățarea întăririi?
iată motivele principale pentru utilizarea învățării de întărire:
când să nu folosiți învățarea de întărire?
nu se poate aplica modelul de învățare armare este tot situația. Iată câteva condiții în care nu ar trebui să utilizați modelul de învățare a întăririi.
provocările învățării întăririi
Iată provocările majore cu care vă veți confrunta în timp ce faceți câștigul de armare: