de William W Wold
în ultimele 6 luni, am lucrat la un limbaj de programare numit Pinecone. Nu l-aș numi încă matur, dar are deja suficiente caracteristici care funcționează pentru a fi utilizabile, cum ar fi:
- variabile
- funcții
- structuri definite de utilizator
dacă sunteți interesat de aceasta, consultați pagina de destinație a Pinecone sau repo-ul său GitHub.
nu sunt expert. Când am început acest proiect, nu am avut nici o idee despre ceea ce făceam, și eu încă nu fac. am luat zero clase pe crearea de limbă, citit doar un pic despre el on-line, și nu a urmat o mare parte din sfaturile pe care le-au fost date.
și totuși, am făcut încă un limbaj complet nou. Și funcționează. Așa că trebuie să fac ceva bine.
în acest post, Mă voi scufunda sub capotă și vă voi arăta conducta Pinecone (și alte limbaje de programare) utilizați pentru a transforma codul sursă în magie.
voi aborda, de asemenea, unele dintre compromisurile pe care le-am făcut și de ce am luat deciziile pe care le-am făcut.
acesta nu este în niciun caz un tutorial complet despre scrierea unui limbaj de programare, dar este un bun punct de plecare dacă sunteți curioși de dezvoltarea limbajului.
Noțiuni de bază
„nu am absolut nici o idee de unde aș începe chiar” este ceva ce aud foarte mult atunci când spun altor dezvoltatori scriu o limbă. În cazul în care aceasta este reacția dvs., voi trece acum prin câteva decizii inițiale care sunt luate și pașii care sunt luați atunci când începeți orice limbă nouă.
compilate vs interpretate
există două tipuri majore de limbi: compilate și interpretate:
- un compilator își dă seama de tot ce va face un program, îl transformă în „cod mașină” (un format pe care computerul îl poate rula foarte repede), apoi îl salvează pentru a fi executat mai târziu.
- un interpret trece prin codul sursă linie cu linie, imaginind ce face pe măsură ce merge.din punct de vedere tehnic, orice limbă ar putea fi compilată sau interpretată, dar una sau alta are de obicei mai mult sens pentru o anumită limbă. În general, interpretarea tinde să fie mai flexibilă, în timp ce compilarea tinde să aibă performanțe mai mari. Dar aceasta este doar zgârierea suprafeței unui subiect foarte complex.
Am valoare foarte mare de performanță, și am văzut o lipsă de limbaje de programare, care sunt atât de înaltă performanță și simplitate orientate, așa că am mers cu compilate pentru Pinecone.
aceasta a fost o decizie importantă de luat din timp, deoarece o mulțime de decizii de proiectare a limbajului sunt afectate de aceasta (de exemplu, tastarea statică este un mare beneficiu pentru limbile compilate, dar nu atât pentru cele interpretate).în ciuda faptului că Pinecone a fost proiectat cu compilarea în minte, are un interpret complet funcțional, care a fost singura modalitate de a rula pentru un timp. Există o serie de motive pentru aceasta, pe care le voi explica mai târziu.
alegerea unei limbi
știu că este un pic meta, dar un limbaj de programare este el însuși un program și, prin urmare, trebuie să îl scrieți într-o limbă. Am ales C++ din cauza performanței sale și set de caracteristici mari. De asemenea, îmi place să lucrez în c++.
dacă scrieți un limbaj interpretat, are mult sens să îl scrieți într-unul compilat (cum ar fi C, C++ sau Swift), deoarece performanța pierdută în limba interpretului dvs. și interpretul care interpretează interpretul dvs. va fi compusă.
dacă intenționați să compilați, un limbaj mai lent (cum ar fi Python sau JavaScript) este mai acceptabil. Compilare timp poate fi rău, dar în opinia mea, care nu este aproape la fel de mare o afacere ca timp de rulare rău.
design de nivel înalt
un limbaj de programare este în general structurat ca o conductă. Adică are mai multe etape. Fiecare etapă are date formatate într-un mod specific, bine definit. De asemenea, are funcții pentru a transforma datele de la fiecare etapă la alta.
prima etapă este un șir care conține întregul fișier sursă de intrare. Etapa finală este ceva care poate fi rulat. Toate acestea vor deveni clare pe măsură ce trecem pas cu pas prin conducta Pinecone.
Lexing
primul pas în majoritatea limbajelor de programare este lexingul sau tokenizarea. ‘Lex’ este prescurtarea de la analiza lexicală, un cuvânt foarte fantezist pentru împărțirea unei grămezi de text în jetoane. Cuvântul ‘ tokenizer ‘are mult mai mult sens, dar’ lexer ‘ este atât de distractiv să spun că îl folosesc oricum.
token-uri
un token este o unitate mică a unei limbi. Un simbol poate fi o variabilă sau un nume de funcție (AKA un identificator), un operator sau un număr.
sarcina Lexer
lexer ar trebui să ia într-un șir care conține un întreg fișiere în valoare de cod sursă și scuipa o listă care conține fiecare jeton.
etapele viitoare ale conductei nu se vor referi înapoi la codul sursă original, astfel încât lexerul trebuie să producă toate informațiile necesare acestora. Motivul pentru acest format de conductă relativ strict este că lexerul poate face sarcini precum eliminarea comentariilor sau detectarea dacă ceva este un număr sau un identificator. Doriți să păstrați această logică blocată în interiorul lexerului, atât pentru a nu trebui să vă gândiți la aceste reguli atunci când scrieți restul limbii, cât și pentru a putea schimba acest tip de sintaxă într-un singur loc.
Flex
în ziua în care am început limba, primul lucru pe care l-am scris a fost un lexer simplu. Curând după aceea, am început să învăț despre instrumente care ar presupune că ar face lexing mai simplu și mai puțin buggy.
instrumentul predominant este Flex, un program care generează lexeri. Îi dai un fișier care are o sintaxă specială pentru a descrie gramatica limbii. Din aceasta generează un program C care lexes un șir și produce ieșirea dorită.
decizia mea
am ales să păstrez lexerul pe care l-am scris pentru moment. În cele din urmă, nu am văzut beneficii semnificative ale utilizării Flex, cel puțin nu suficient pentru a justifica adăugarea unei dependențe și complicarea procesului de construire.lexer meu este doar câteva sute de linii lungi, și rareori îmi dă probleme. Rularea propriului lexer îmi oferă, de asemenea, mai multă flexibilitate, cum ar fi posibilitatea de a adăuga un operator în limbă fără a edita mai multe fișiere.
parsare
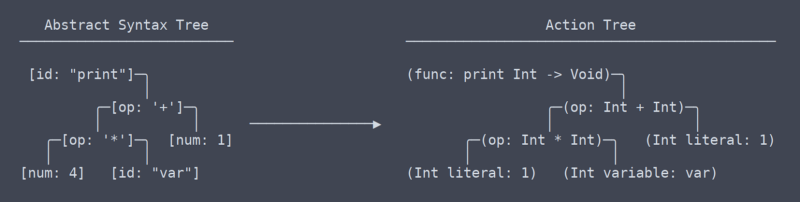
a doua etapă a conductei este analizorul. Parserul transformă o listă de jetoane într-un arbore de noduri. Un arbore utilizat pentru stocarea acestui tip de date este cunoscut sub numele de arbore de sintaxă abstractă sau AST. Cel puțin în Pinecone, AST nu are informații despre tipuri sau care sunt identificatorii. Este pur și simplu structurat jetoane.
Taxe Parser
parser adaugă structura la lista ordonată de token-uri Lexer produce. Pentru a opri ambiguitățile, parserul trebuie să ia în considerare paranteza și ordinea operațiilor. Pur și simplu parsarea operatorilor nu este teribil de dificilă, dar pe măsură ce se adaugă mai multe construcții lingvistice, parsarea poate deveni foarte complexă.
Bison
din nou, a existat o decizie de a face care implică o bibliotecă terță parte. Biblioteca de parsare predominantă este bizonul. Bison funcționează foarte mult ca Flex. Scrieți un fișier într-un format personalizat care stochează informațiile gramaticale, apoi Bison îl folosește pentru a genera un program C care vă va analiza. Nu am ales să folosesc bizon.
de CE Personalizat este mai bine
cu lexer, decizia de a folosi propriul meu cod a fost destul de evident. Un lexer este un program atât de banal încât a nu-mi scrie propriul mi s-a părut aproape la fel de prostesc ca a nu-mi scrie propriul ‘stânga-pad’.
cu parserul, este o chestiune diferită. Parser meu Pinecone este în prezent 750 linii lungi, și am scris trei dintre ele, deoarece primele două au fost gunoi.
am luat inițial decizia mea din mai multe motive și, deși nu a mers complet fără probleme, majoritatea sunt adevărate. Cele mai importante sunt după cum urmează:
- minimizați comutarea contextului în fluxul de lucru: comutarea contextului între C++ și Pinecone este suficient de proastă fără a arunca în gramatica lui Bison gramatica
- păstrați construirea simplă: de fiecare dată când modificările gramaticale Bison trebuie rulate înainte de construire. Acest lucru poate fi automatizat, dar devine o durere atunci când comutați între sistemele de construcție.
- îmi place să construiesc rahaturi mișto: nu am făcut Pinecone pentru că am crezut că va fi ușor, așa că de ce aș delega un rol central când aș putea să o fac singur? Un parser personalizat poate să nu fie banal, dar este complet realizabil.
la început nu eram complet sigur dacă merg pe o cale viabilă, dar mi s-a dat încredere de ceea ce Walter Bright (un dezvoltator pe o versiune timpurie a C++ și creatorul limbajului D) a avut de spus pe această temă:
„ceva mai controversat, nu m-aș deranja să pierd timpul cu generatoarele lexer sau parser și alte așa-numite „compilatoare de compilatoare.”Sunt o pierdere de timp. Scrierea unui lexer și parser este un procent mic de locuri de muncă de a scrie un compilator. Utilizarea unui generator va dura aproximativ la fel de mult timp ca scrierea manuală și vă va căsători cu generatorul (ceea ce contează atunci când portați compilatorul pe o nouă platformă). Și generatoarele au, de asemenea, reputația nefericită de a emite mesaje de eroare proaste.”
arborele de acțiune
am părăsit acum zona termenilor comuni, universali sau cel puțin nu știu care mai sunt termenii. Din înțelegerea mea, ceea ce eu numesc arborele de acțiune este cel mai asemănător cu IR (reprezentarea intermediară) a LLVM.
există o diferență subtilă, dar foarte semnificativă între arborele de acțiune și arborele de sintaxă abstractă. Mi-a luat ceva timp să-mi dau seama că ar trebui să existe chiar și o diferență între ele (ceea ce a contribuit la necesitatea rescrierii parserului).
Action Tree vs AST
mai simplu spus, action tree este AST cu context. Acest context este informații, cum ar fi ce tip de funcție returnează sau că două locuri în care este utilizată o variabilă folosesc de fapt aceeași variabilă. Deoarece trebuie să-și dea seama și să-și amintească tot acest context, codul care generează arborele de acțiune are nevoie de o mulțime de tabele de căutare a spațiului de nume și alte lucruri.
rularea arborelui de acțiune
odată ce avem arborele de acțiune, rularea codului este ușoară. Fiecare nod de acțiune are o funcție ‘execute’ care ia o anumită intrare, face orice acțiune ar trebui (inclusiv, eventual, apelarea sub acțiune) și returnează ieșirea acțiunii. Acesta este interpretul în acțiune.
Opțiuni de compilare
” dar așteptați!”Te-am auzit spunând,” Nu este Pinecone ar trebui să DE compilat?”Da, este. Dar compilarea este mai grea decât interpretarea. Există câteva abordări posibile.
construi propriul meu compilator
acest lucru a sunat ca o idee bună pentru mine la început. Îmi place să fac lucrurile singur, și am fost mâncărime pentru o scuză pentru a obține bun la asamblare.din păcate, scrierea unui compilator portabil nu este la fel de ușoară ca scrierea unui cod de mașină pentru fiecare element de limbă. Din cauza numărului de arhitecturi și sisteme de operare, este imposibil pentru orice persoană să scrie un backend compilator cross-platform.
chiar și echipele din spatele Swift, Rust și zăngănit nu vreau să deranjez cu totul pe cont propriu, așa că în schimb toate folosesc…
LLVM
LLVM este o colecție de instrumente de compilator. Este practic o bibliotecă care vă va transforma limba într-un binar executabil compilat. Mi s-a părut alegerea perfectă, așa că am sărit direct. Din păcate nu am verificat cât de adâncă era apa și m-am înecat imediat.
LLVM, în timp ce nu limbaj de asamblare greu, este gigantic bibliotecă complex greu. Nu este imposibil de utilizat și au tutoriale bune, dar mi-am dat seama că va trebui să fac ceva practică înainte de a fi gata să implementez pe deplin un compilator Pinecone cu el.
Transpiling
am vrut un fel de Pinecone compilat și am vrut rapid, așa că am apelat la o metodă știam că pot face munca: transpiling.
am scris un Pinecone la C++ transpiler, și a adăugat capacitatea de a compila automat sursa de ieșire cu GCC. Acest lucru funcționează în prezent pentru aproape toate programele Pinecone (deși există câteva cazuri de margine care îl rup). Nu este o soluție deosebit de portabilă sau scalabilă, dar funcționează deocamdată.
viitor
presupunând că voi continua să dezvolte Pinecone, acesta va primi LLVM compilarea sprijin mai devreme sau mai târziu. Bănuiesc că nu contează cât de mult lucrez la el, transpilerul nu va fi niciodată complet stabil, iar beneficiile LLVM sunt numeroase. Este doar o chestiune de când am timp să fac niște proiecte de probă în LLVM și să mă obișnuiesc.
până atunci, interpretul este excelent pentru programele banale și C++ transpiling funcționează pentru majoritatea lucrurilor care au nevoie de mai multă performanță.
concluzie
sper că am făcut limbaje de programare un pic mai puțin misterios pentru tine. Dacă doriți să faceți unul singur, vă recomand foarte mult. Există o mulțime de detalii de implementare pentru a afla, dar conturul de aici ar trebui să fie suficient pentru a vă duce.
iată sfatul meu de nivel înalt pentru a începe (amintiți-vă, nu știu cu adevărat ce fac, așa că luați-l cu un bob de sare):
- dacă aveți îndoieli, mergeți interpretat. Limbile interpretate sunt, în general, mai ușor de proiectat, construit și învățat. Nu te descurajez să scrii unul compilat dacă știi că asta vrei să faci, dar dacă ești pe gard, aș merge interpretat.
- când vine vorba de lexers și parsers, fă ce vrei. Există argumente valide pentru și împotriva scrierii proprii. În cele din urmă, dacă vă gândiți la designul dvs. și implementați totul într-un mod sensibil, nu contează cu adevărat.
- aflați din conducta cu care am ajuns. O mulțime de încercări și erori au intrat în proiectarea conductei pe care o am acum. Am încercat eliminarea ASTs, ASTs care se transformă în acțiuni copaci în loc, și alte idei teribile. Această conductă funcționează, așa că nu o schimbați decât dacă aveți o idee foarte bună.
- dacă nu aveți timp sau motivație pentru a implementa un limbaj complex de uz general, încercați să implementați un limbaj ezoteric, cum ar fi Brainfuck. Acești interpreți pot fi la fel de scurți ca câteva sute de rânduri.
am foarte puține regrete atunci când vine vorba de dezvoltarea Pinecone. Am făcut o serie de alegeri proaste pe parcurs, dar am rescris cea mai mare parte a codului afectat de astfel de greșeli.
chiar acum, Pinecone este într-o stare suficient de bună încât funcționează bine și poate fi ușor îmbunătățită. Scrierea Pinecone a fost o experiență extrem de educativă și plăcută pentru mine și abia începe.