nu puteți folosi cu ușurință variabilele categorice ca predictori în regresia liniară: trebuie să le împărțiți în variabile dihotomice cunoscute sub numele de variabile fictive.
modul ideal de a crea aceste este instrumentul nostru variabile fictive. Dacă nu doriți să utilizați acest instrument, atunci acest tutorial arată modul corect de a face acest lucru manual.
- exemplu I – orice variabilă numerică
- exemplu II – variabilă numerică cu numere întregi adiacente
- exemplu III – variabilă șir cu conversie
- exemplu IV – variabilă șir fără conversie
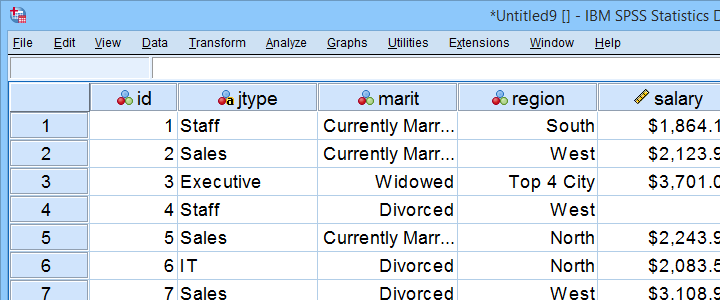
exemplu fișier de date
acest tutorial folosește personal.sav pe tot parcursul. O parte din acest fișier de date este prezentată mai jos.
exemplu i – orice variabilă numerică
să creăm mai întâi variabile fictive pentru marit, scurt pentru starea civilă. Primul nostru pas este să rulăm un tabel de frecvențe de bază cufrecvențe marit.Tabelul de mai jos prezintă tabelul rezultat.
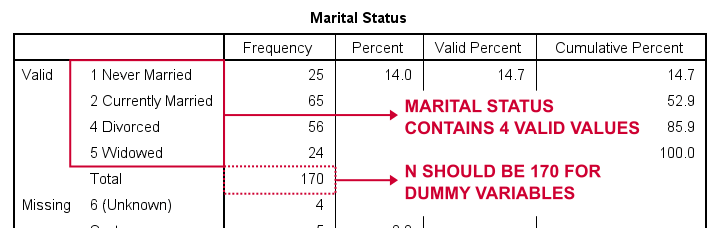
Deci, cum să desparți starea civilă în variabile fictive? În primul rând, omitem întotdeauna o categorie, categoria de referință. Puteți alege orice categorie ca categorie de referință.
deci, pentru acest exemplu, alegem 5 (văduv). Acest lucru implică faptul că vom crea 3 variabile fictive reprezentând categoriile 1, 2 și 4 (rețineți că 3 nu apare în această variabilă).
sintaxa de mai jos arată cum să creați și să etichetați cele 3 variabile fictive. Să-l rulați.
calcula marit_1 =(marit = 1).
calcula marit_2 = (marit = 2).
calcula marit_4 =(marit = 4).
*aplicați etichete variabile variabilelor fictive.
etichete variabile
marit_1 ‘Stare civilă = niciodată căsătorit’
marit_2 ‘Stare civilă = în prezent căsătorit’
marit_4 ‘Stare civilă = Divorțat’.
*verificați rapid prima variabilă fictivă
frecvențe marit_1.
rezultate
în primul rând, rețineți că am creat 3 variabile fictive frumos etichetate în setul nostru de date activ.
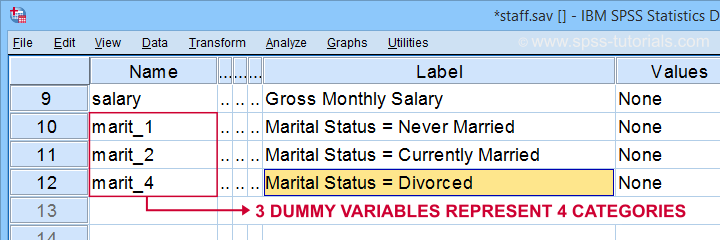
tabelul de mai jos prezintă distribuția frecvenței pentru prima noastră variabilă fictivă.

rețineți că variabila noastră fictivă deține 3 valori distincte:
- respondenții a căror stare civilă nu este „niciodată căsătoriți” Scor 0;
- respondenții a căror stare civilă este „niciodată căsătoriți” scor 1;
- respondenții a căror stare civilă este o valoare lipsă (și, prin urmare, necunoscută) au o valoare lipsă de sistem.
putem verifica acum rezultatele mai bine de runningcrosstabs marit de marit_1 la marit_4.Acest lucru creează 3 tabele de urgență, dintre care primul este prezentat mai jos.
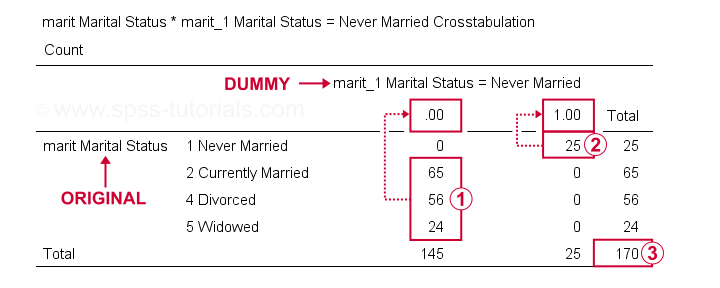
pe variabila noastră fictivă, respondenții care au alte stări civile decât „niciodată căsătoriți” toate Scor 0;
respondenții care au alte stări civile decât „niciodată căsătoriți” toate Scor 0; respondenții care „nu s-au căsătorit niciodată” toate scor 1;
respondenții care „nu s-au căsătorit niciodată” toate scor 1; avem o dimensiune a eșantionului de N = 170 (acest tabel include numai respondenții fără valori lipsă pe oricare dintre variabile).
avem o dimensiune a eșantionului de N = 170 (acest tabel include numai respondenții fără valori lipsă pe oricare dintre variabile).
opțional, o verificare finală-foarte amănunțită – este de a compara rezultatele ANOVA pentru variabila inițială cu rezultatele regresiei folosind variabilele noastre fictive. Sintaxa de mai jos face doar asta, folosind salariul lunar ca variabilă dependentă.
regresie
/salariu dependent
/metoda introduceți marit_1 la marit_4.
* Anova minim folosind variabila originală.
salariul oneway de marit.
rețineți că ambele analize au ca rezultat tabele ANOVA identice. Vom discuta ANOVA versus regresia variabilă dummy mai detaliat într-un tutorial viitor.
exemplul II – variabila numerică cu numere întregi adiacente
vom crea acum variabile fictive pentru regiune. Din nou, începem prin inspectarea unui tabel de frecvență minimă pe care îl vom crea prin regiunea runningfrequencies.Acest lucru are ca rezultat tabelul de mai jos.
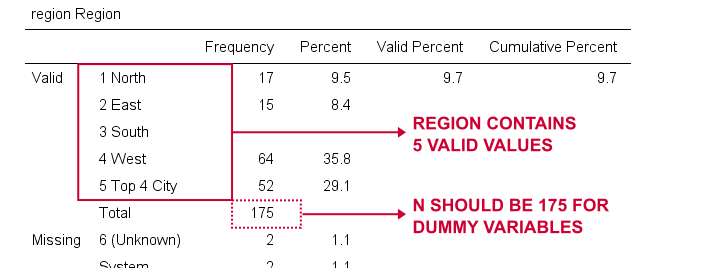
vom alege 1 („Nord”) ca categorie de referință. Prin urmare, vom crea variabile fictive pentru categoriile 2 până la 5. Deoarece acestea sunt numere întregi adiacente, putem accelera lucrurile folosind repetați așa cum se arată mai jos.
repetați # vals = 2 la 5 / # vars = region_2 la region_5.
recode Regiune (#vals = 1)(lo thru hi = 0) în #vars.
sfârșit repetare imprimare.
*aplicați etichete variabile la noi variabile.
etichete variabile
region_2 ‘Region = Est’
region_3 ‘Region = Sud’
region_4 ‘Region = Vest’
region_5 ‘Region = Top 4 oraș’.
*verificare rapidă.
crosstabs regiune de region_2 la region_5.
o inspecție atentă a tabelelor rezultate confirmă faptul că toate rezultatele sunt corecte.
exemplul III – variabila String cu conversie
Din păcate, primele noastre 2 metode nu funcționează pentru variabilele string, cum ar fi jtype-prescurtare pentru „tip job”). Cea mai ușoară soluție este să-l transforme într-o variabilă numerică așa cum sa discutat în SPSS converti șir de variabile numerice. Sintaxa de mai jos folosește codul automat pentru a face treaba.
autorecode jtype
/în njtype.
*verificați rezultatul.
frecvențe njtype.
*Setați valorile lipsă.
valori lipsă njtype (1,2).
* verificați din nou rezultatul.
frecvențe njtype.
rezultat

deoarece Njtype-prescurtare pentru „numeric job type”- este o variabilă numerică, putem folosi acum metoda I sau metoda II pentru a o împărți în variabile fictive.
exemplu IV – string variabilă fără conversie
conversia variabilelor șir în cele numerice este ușor de a crea variabile fictive pentru ei. Fără această conversie, procesul este greoi, deoarece SPSS nu gestionează corect valorile lipsă pentru variabilele de șir. Cu toate acestea, sintaxa de mai jos face treaba corect.
frecvențe jtype.
*șansă ‘(necunoscut) ‘în’NA’.
recode jtype (‘(necunoscut) ‘ = ‘NA’).
*Set utilizator valori lipsă.
valori lipsă jtype ( ” , „NA”).
*Reinspectați frecvențele.
frecvențe jtype.
*Crearea variabile fictive pentru variabile șir.
dacă (nu lipsește (jtype)) jtype_1 = (jtype = ‘IT’).
dacă (nu lipsește (jtype)) jtype_2 = (jtype = ‘Management’).
dacă (nu lipsește (jtype)) jtype_3 = (jtype = ‘vânzări’).
dacă (nu lipsește (jtype)) jtype_4 = (jtype = ‘personal’).
*aplicați etichete variabile variabilelor fictive.
etichete variabile
jtype_1 ‘Job type = IT’
jtype_2 ‘Job type = Management’
jtype_3 ‘Job type = Sales’
jtype_4 ‘Job type = Staff’.
*Verificați rezultatele.
crosstabs jtype de jtype_1 la jtype_4.
note finale
crearea variabilelor fictive pentru variabilele numerice se poate face rapid și ușor. Cu toate acestea, setarea Etichetelor variabile adecvate necesită întotdeauna un pic de lucru. Variabilele șir necesită unele pas(e) suplimentare, dar sunt destul de greu de realizat, de asemenea.
cu toate acestea, cea mai ușoară opțiune este instrumentul nostru SPSS Create Dummy Variables, deoarece are grijă perfectă de tot.