bună și bine ați venit la un ghid ilustrat pentru memoria pe termen scurt (LSTM) și unități recurente închise (Gru). Sunt Michael și sunt inginer de învățare automată în spațiul asistentului vocal AI.
în această postare, vom începe cu intuiția din spatele LSTM și GRU. apoi voi explica mecanismele interne care permit lstm și GRU să funcționeze atât de bine. Dacă doriți să înțelegeți ce se întâmplă sub capotă pentru aceste două rețele, atunci acest post este pentru dvs.
de asemenea, puteți viziona versiunea video a acestei postări pe youtube, dacă preferați.
rețelele neuronale recurente suferă de memorie pe termen scurt. Dacă o secvență este suficient de lungă, le va fi greu să transporte informații de la pașii temporali anteriori la cei ulteriori. Deci, dacă încercați să procesați un paragraf de text pentru a face predicții, RNN-urile pot lăsa informații importante de la început.
în timpul propagării înapoi, rețelele neuronale recurente suferă de problema gradientului de dispariție. Gradienții sunt valori utilizate pentru a actualiza greutățile rețelelor neuronale. Problema gradientului de dispariție este atunci când gradientul se micșorează pe măsură ce se propagă înapoi în timp. Dacă o valoare a gradientului devine extrem de mică, nu contribuie prea mult la învățare.

regula de actualizare a gradientului
deci, în rețelele neuronale recurente, straturile care primesc o actualizare gradient mic se oprește de învățare. Acestea sunt de obicei straturile anterioare. Deci, deoarece aceste straturi nu învață, RNN poate uita ceea ce a văzut în secvențe mai lungi, având astfel o memorie pe termen scurt. Dacă doriți să aflați mai multe despre mecanica rețelelor neuronale recurente în general, puteți citi postarea mea anterioară aici.
LSTM și GRU ca soluție
LSTM și GRU au fost create ca soluție pentru memoria pe termen scurt. Au mecanisme interne numite porți care pot regla fluxul de informații.

aceste porți pot afla ce date dintr-o secvență sunt importante de păstrat sau aruncat. Procedând astfel, poate transmite informații relevante în lungul lanț de secvențe pentru a face predicții. Aproape toate rezultatele de ultimă oră bazate pe rețele neuronale recurente sunt obținute cu aceste două rețele. LSTM și GRU pot fi găsite în recunoașterea vorbirii, sinteza vorbirii și generarea de text. Le puteți folosi chiar și pentru a genera subtitrări pentru videoclipuri.
Ok, deci până la sfârșitul acestui post ar trebui să aveți o înțelegere solidă a motivului pentru care LSTM-urile și GRU-urile sunt bune la procesarea secvențelor lungi. Am de gând să abordeze acest lucru cu explicații intuitive și ilustrații și pentru a evita matematica cât mai mult posibil.
intuiția
ok, să începem cu un experiment de gândire. Să presupunem că vă uitați la Recenzii online pentru a determina dacă doriți să cumpărați cereale Life (nu mă întrebați de ce). Mai întâi veți citi recenzia, apoi veți determina dacă cineva a crezut că este bine sau dacă a fost rău.

când citiți recenzia, creierul dvs. își amintește subconștient doar cuvinte cheie importante. Ridici cuvinte precum” uimitor „și”mic dejun perfect echilibrat”. Nu vă pasă prea mult de cuvinte precum „asta”, „a dat”, „toate”, „ar trebui” etc. Dacă un prieten vă întreabă a doua zi ce a spus recenzia, probabil că nu v-ați aminti cuvânt cu cuvânt. S-ar putea aminti principalele puncte, deși ca „va fi cu siguranta de cumpărare din nou”. Dacă semeni mult cu mine, celelalte cuvinte vor dispărea din memorie.

și asta este în esență ceea ce face un lstm sau Gru. Poate învăța să păstreze doar informații relevante pentru a face predicții și să uite date non-relevante. În acest caz, cuvintele pe care ți le-ai amintit te-au făcut să judeci că este bine.
revizuirea rețelelor neuronale recurente
pentru a înțelege modul în care LSTM sau GRU realizează acest lucru, să trecem în revistă rețeaua neuronală recurentă. Un RNN funcționează astfel; primele cuvinte se transformă în vectori citibili de mașină. Apoi RNN procesează secvența vectorilor unul câte unul.

secvență de procesare unul câte unul
în timpul procesării, trece starea ascunsă anterioară la pasul următor al secvenței. Starea ascunsă acționează ca memoria rețelelor neuronale. Deține informații despre datele anterioare pe care rețeaua le-a văzut anterior.

trecerea statului ascuns la pasul următor
să ne uităm la o celulă a RNN pentru a vedea cum ați calcula starea ascunsă. În primul rând, intrarea și starea ascunsă anterioară sunt combinate pentru a forma un vector. Acest vector are acum informații despre intrarea curentă și intrările anterioare. Vectorul trece prin activarea tanh, iar ieșirea este noua stare ascunsă sau memoria rețelei.

RNN Cell
activarea tanh
activarea tanh este utilizată pentru a ajuta la reglarea valorilor care curg prin rețea. Funcția tanh squishes valori să fie întotdeauna între -1 și 1.

Tanh squishes valori a fi între -1 și 1
când vectorii curg printr-o rețea neuronală, acesta suferă multe transformări datorită diferitelor operații matematice. Deci, imaginați-vă o valoare care continuă să fie înmulțită cu să spunem 3. Puteți vedea cum unele valori pot exploda și deveni astronomice, determinând alte valori să pară nesemnificative.

transformări vectoriale fără tanh
o funcție tanh asigură că valorile rămân între -1 și 1, reglând astfel ieșirea rețelei neuronale. Puteți vedea cum aceleași valori de sus rămân între limitele permise de funcția tanh.

transformări vectoriale cu tanh
deci este un RNN. Are foarte puține operații pe plan intern, dar funcționează destul de bine având în vedere circumstanțele potrivite (cum ar fi secvențele scurte). RNN utilizează mult mai puține resurse de calcul decât variantele evoluate, LSTM și GRU.
LSTM
Un LSTM are un flux de control similar cu o rețea neuronală recurentă. Procesează datele care transmit informații pe măsură ce se propagă înainte. Diferențele sunt operațiile din celulele LSTM.

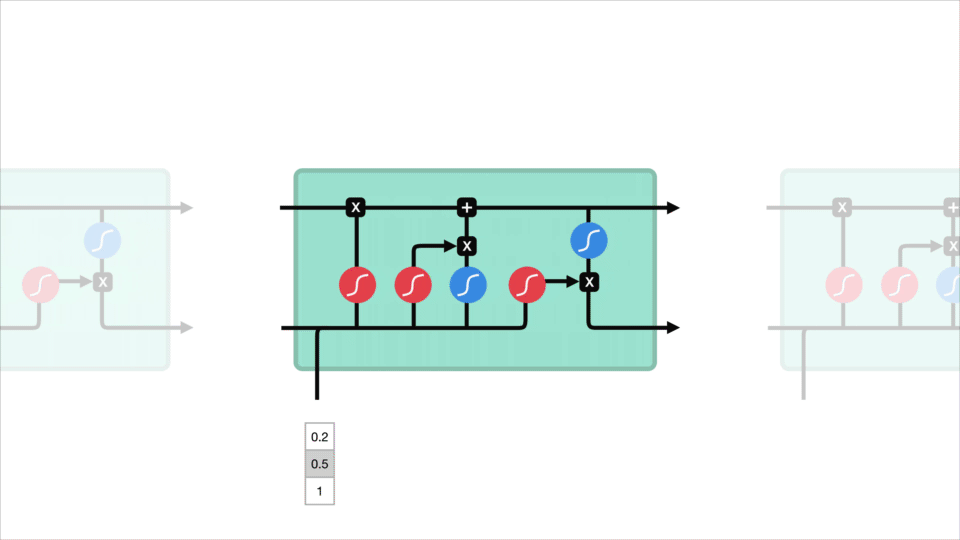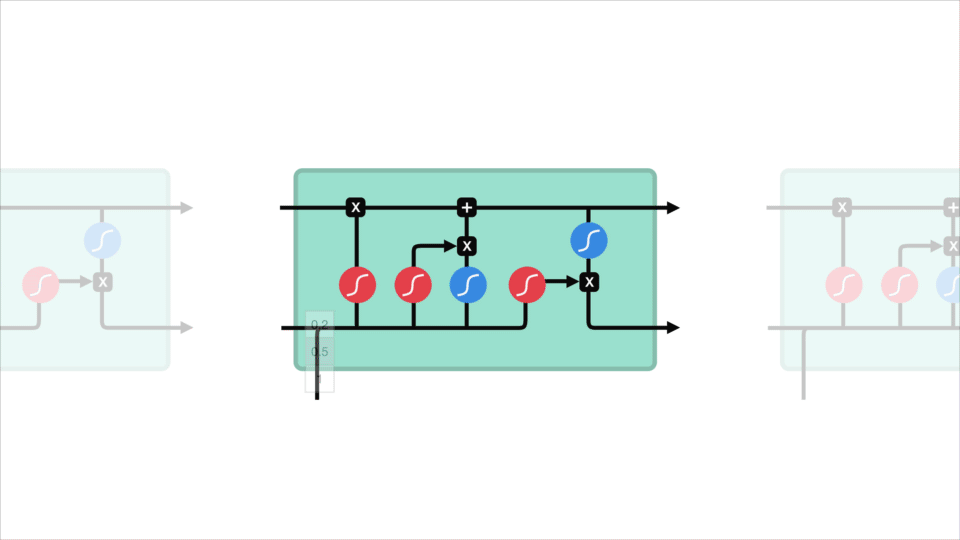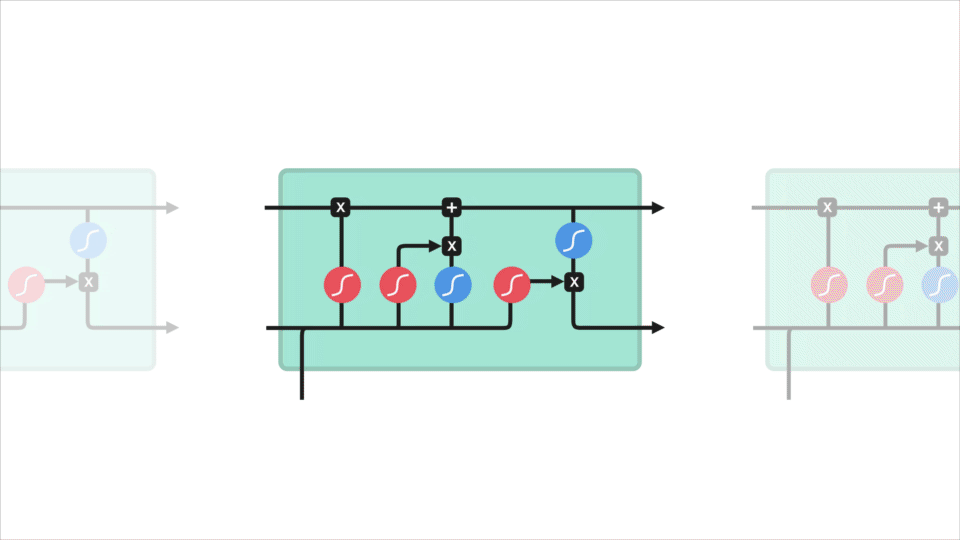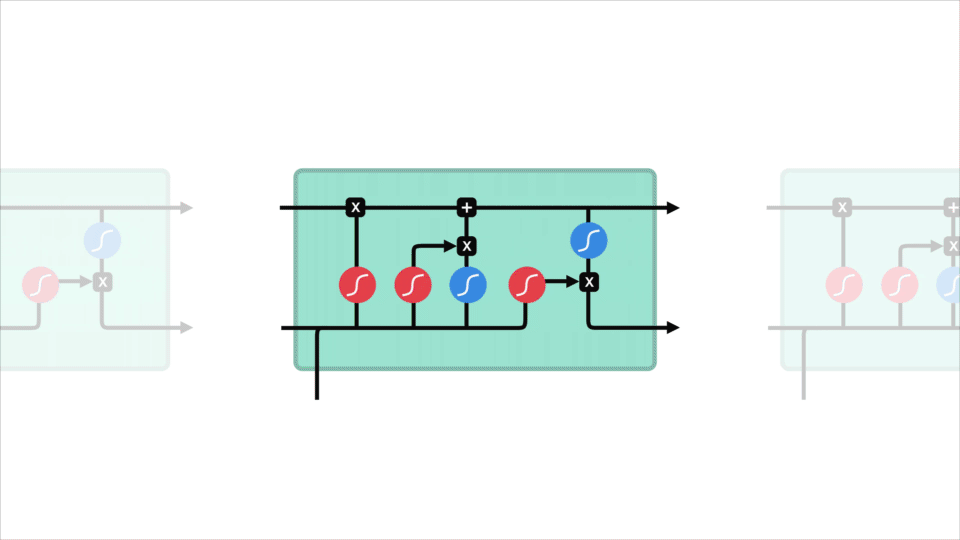
celula LSTM și It operațiile
aceste operații sunt utilizate pentru a permite lstm să păstreze sau să uite informații. Acum, uita la aceste operațiuni pot obține un pic copleșitoare așa că vom trece peste acest pas cu pas.
conceptul de bază
conceptul de bază al LSTM-urilor sunt starea celulei și sunt porți diferite. Starea celulei acționează ca o autostradă de transport care transferă informații relative până la capătul lanțului de secvențe. Vă puteți gândi la ea ca la „memoria” rețelei. Starea celulei, în teorie, poate transporta informații relevante pe tot parcursul procesării secvenței. Deci, chiar și informațiile din etapele anterioare de timp pot face drumul către etapele ulterioare de timp, reducând efectele memoriei pe termen scurt. Pe măsură ce starea celulei își continuă călătoria, informațiile sunt adăugate sau eliminate în starea celulei prin gates. Porțile sunt diferite rețele neuronale care decid ce informații sunt permise în starea celulei. Porțile pot afla ce informații sunt relevante pentru a păstra sau uita în timpul antrenamentului.
Sigmoid
Gates conține activări sigmoide. O activare sigmoidă este similară cu activarea tanh. În loc de squishing valori între -1 și 1, se squishes valori între 0 și 1. Acest lucru este util pentru actualizarea sau uitarea datelor, deoarece orice număr înmulțit cu 0 este 0, determinând dispariția valorilor sau „uitarea”.”Orice număr înmulțit cu 1 este aceeași valoare, prin urmare, această valoare rămâne aceeași sau este „păstrată.”Rețeaua poate afla care date nu sunt importante, prin urmare pot fi uitate sau care date sunt importante de păstrat.

sigmoid squishes valori să fie între 0 și 1
să săpăm puțin mai adânc în ceea ce fac diferitele porți, nu-i așa? Deci avem trei porți diferite care reglează fluxul de informații într-o celulă LSTM. O poarta uita, poarta de intrare, și poarta de ieșire.
uita poarta
În primul rând, avem poarta uita. Această poartă decide ce informații ar trebui aruncate sau păstrate. Informațiile din starea ascunsă anterioară și informațiile de la intrarea curentă sunt transmise prin funcția sigmoid. Valorile apar între 0 și 1. Mai aproape de 0 înseamnă a uita, și mai aproape de 1 înseamnă a păstra.

uitați operațiile porții
poarta de intrare
pentru a actualiza starea celulei, avem poarta de intrare. În primul rând, trecem starea ascunsă anterioară și intrarea curentă într-o funcție sigmoidă. Care decide ce valori vor fi actualizate prin transformarea valorilor să fie între 0 și 1. 0 înseamnă că nu este important, iar 1 înseamnă important. De asemenea, treceți starea ascunsă și intrarea curentă în funcția tanh pentru a strivi valori între -1 și 1 pentru a ajuta la reglarea rețelei. Apoi înmulțiți ieșirea tanh cu ieșirea sigmoidă. Ieșirea sigmoid va decide ce informații sunt importante pentru a păstra de la ieșirea tanh.

operații poarta de intrare
starea celulei
acum ar trebui să avem suficiente informații pentru a calcula starea celulei. În primul rând, starea celulei se înmulțește punctual cu vectorul uita. Aceasta are posibilitatea de a scădea valorile în starea celulei dacă se înmulțește cu valori apropiate de 0. Apoi luăm ieșirea de la poarta de intrare și facem o adăugare punctuală care actualizează starea celulei la noi valori pe care rețeaua neuronală le consideră relevante. Asta ne dă noua stare de celule.

calcularea stării celulei
poarta de ieșire
ultima avem poarta de ieșire. Poarta de ieșire decide care ar trebui să fie următoarea stare ascunsă. Amintiți-vă că starea ascunsă conține informații despre intrările anterioare. Starea ascunsă este folosită și pentru predicții. În primul rând, trecem starea ascunsă anterioară și intrarea curentă într-o funcție sigmoidă. Apoi trecem starea celulei nou modificată la funcția tanh. Înmulțim ieșirea tanh cu ieșirea sigmoidă pentru a decide ce informații ar trebui să poarte starea ascunsă. Ieșirea este starea ascunsă. Noua stare de celulă și Noul ascuns este apoi reportată la pasul următor.

operații poarta de ieșire
pentru a revizui, poarta uita decide ce este relevant pentru a păstra de la etapele anterioare. Poarta de intrare decide ce informații sunt relevante pentru a adăuga de la pasul curent. Poarta de ieșire determină care ar trebui să fie următoarea stare ascunsă.
cod Demo
pentru cei dintre voi care înțeleg mai bine prin a vedea codul, aici este un exemplu folosind Python pseudo cod.

python pseudo cod
1. În primul rând, starea ascunsă anterioară și intrarea curentă sunt concatenate. O vom numi combina.
2. Combinați get-ul alimentat în stratul de uitare. Acest strat elimină datele care nu sunt relevante.
4. Un strat candidat este creat folosind combina. Candidatul deține valori posibile pentru a adăuga la starea celulei.
3. Se combină, de asemenea, a obține alimentat în stratul de intrare. Acest strat decide ce date de la candidat ar trebui adăugate la noua stare de celulă.
5. După calcularea stratului de uitare, a stratului candidat și a stratului de intrare, starea celulei este calculată folosind acei vectori și starea celulei anterioare.
6. Rezultatul este apoi calculat.
7. Înmulțirea punctuală a ieșirii și a noii stări celulare ne oferă noua stare ascunsă.
asta e! Fluxul de control al unei rețele LSTM sunt câteva operații tensor și o buclă pentru. Puteți utiliza stările ascunse pentru predicții. Combinând toate aceste mecanisme, un LSTM poate alege ce informații sunt relevante să-și amintească sau să uite în timpul procesării secvenței.
GRU
Deci, acum știm cum funcționează un LSTM, să ne uităm pe scurt la GRU. GRU este noua generație de rețele neuronale recurente și este destul de similar cu un LSTM. GRU a scăpat de starea celulei și a folosit starea ascunsă pentru a transfera informații. De asemenea, are doar două porți, o poartă de resetare și o poartă de actualizare.

celula GRU și este porți
poarta de actualizare
poarta de actualizare acționează similar cu poarta de uitare și intrare a unui lstm. Decide ce informații să arunce și ce informații noi să adauge.
Reset Gate
reset gate este o altă poartă este folosit pentru a decide cât de mult trecut informații pentru a uita.
și acesta este un GRU. GRU are mai puține operații tensoriale; prin urmare, ele sunt un pic mai rapid pentru a instrui apoi LSTM. nu există un câștigător clar care unul este mai bun. Cercetătorii și inginerii încearcă, de obicei, atât pentru a determina care funcționează mai bine pentru cazul lor de utilizare.
deci asta este
pentru a rezuma acest lucru, RNN-urile sunt bune pentru procesarea datelor de secvență pentru predicții, dar suferă de memorie pe termen scurt. LSTM și GRU au fost create ca o metodă de atenuare a memoriei pe termen scurt folosind mecanisme numite porți. Porțile sunt doar rețele neuronale care reglează fluxul de informații care curge prin lanțul secvenței. LSTM și GRU sunt utilizate în stare de artă aplicații de învățare profundă, cum ar fi recunoașterea vorbirii, sinteza vorbirii, înțelegerea limbajului natural, etc.
dacă sunteți interesat în a merge mai adânc, aici sunt link-uri de unele resurse fantastice care vă pot oferi o perspectivă diferită în înțelegerea LSTM și GRU lui. acest post a fost puternic inspirat de ei.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/