actualizat ultima dată pe 17 februarie 2021
o predicție dintr-o perspectivă de învățare automată este un singur punct care ascunde incertitudinea acelei predicții.intervalele de predicție oferă o modalitate de a cuantifica și comunica incertitudinea într-o predicție. Acestea sunt diferite de intervalele de încredere care încearcă în schimb să cuantifice incertitudinea într-un parametru de populație, cum ar fi o medie sau o abatere standard. Intervalele de predicție descriu incertitudinea pentru un singur rezultat specific.
în acest tutorial, veți descoperi intervalul de predicție și cum să-l calculați pentru un model simplu de regresie liniară.
după finalizarea acestui tutorial, veți ști:
- că un interval de predicție cuantifică incertitudinea unei predicții cu un singur punct.
- că intervalele de predicție pot fi estimate analitic pentru modele simple, dar sunt mai dificile pentru modelele neliniare de învățare automată.
- cum se calculează intervalul de predicție pentru un model simplu de regresie liniară.
începeți-vă proiectul cu noile mele statistici de carte pentru învățarea automată, inclusiv tutoriale pas cu pas și fișierele de cod sursă Python pentru toate exemplele.
Să începem.
- actualizat Iunie / 2019: nivel de semnificație corectat ca o fracțiune din abaterile standard.
- actualizat Aprilie / 2020: greșeală de scriere fixă în graficul intervalului de predicție.

intervale de predicție pentru învățarea automată
foto de Jim Bendon, unele drepturi rezervate.
tutorial prezentare generală
acest tutorial este împărțit în 5 părți; acestea sunt:
- ce este în neregulă cu o estimare punct?
- ce este un interval de predicție?
- cum se calculează un interval de predicție
- interval de predicție pentru regresia liniară
- exemplu lucrat
aveți nevoie de ajutor cu statistici pentru învățarea automată?
Ia-Mi gratuit 7 zile de e-mail crash course acum (cu codul de probă).
Faceți clic pentru a vă înscrie și pentru a obține, de asemenea, o versiune gratuită PDF Ebook a cursului.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.prezice (X)
|
unde yhat este rezultatul estimat sau predicția făcută de modelul instruit pentru datele de intrare date X.
aceasta este o predicție punctuală.
prin definiție, este o estimare sau o aproximare și conține o anumită incertitudine.
incertitudinea provine din erorile din modelul în sine și zgomotul din datele de intrare. Modelul este o aproximare a relației dintre variabilele de intrare și variabilele de ieșire.
având în vedere procesul utilizat pentru a alege și regla modelul, acesta va fi cea mai bună aproximare făcută având în vedere informațiile disponibile, dar va face în continuare erori. Datele din domeniu vor ascunde în mod natural relația de bază și necunoscută dintre variabilele de intrare și ieșire. Acest lucru va face o provocare pentru a se potrivi modelului și va face, de asemenea, o provocare pentru un model potrivit să facă predicții.având în vedere aceste două surse principale de eroare, predicția lor punctuală dintr-un model predictiv este insuficientă pentru a descrie adevărata incertitudine a predicției.
ce este un interval de predicție?
un interval de predicție este o cuantificare a incertitudinii pe o predicție.
oferă o limită superioară și inferioară probabilistică la estimarea unei variabile de rezultat.
un interval de predicție pentru o singură observație viitoare este un interval care, cu un anumit grad de încredere, va conține o viitoare observație selectată aleatoriu dintr-o distribuție.
— pagina 27, intervale statistice: un ghid pentru practicieni și cercetători, 2017.intervalele de predicție sunt cel mai frecvent utilizate atunci când se fac predicții sau previziuni cu un model de regresie, unde se prezice o cantitate.
un exemplu de prezentare a unui interval de predicție este următorul:
având în vedere o predicție a ” y ” dat „x”, există o probabilitate de 95% ca intervalul ” a ” la ” b ” să acopere rezultatul adevărat.
intervalul de predicție înconjoară predicția făcută de model și, sperăm, acoperă intervalul rezultatului adevărat.
diagrama de mai jos ajută la înțelegerea vizuală a relației dintre predicție, intervalul de predicție și rezultatul real.
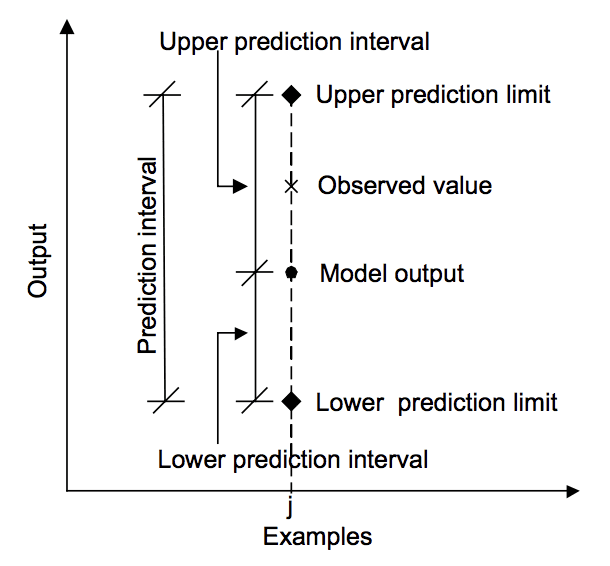
relația dintre predicție, valoarea reală și intervalul de predicție.
preluat din „abordări de învățare automată pentru estimarea intervalului de predicție pentru producția modelului”, 2006.
un interval de predicție este diferit de un interval de încredere.
un interval de încredere cuantifică incertitudinea pe o variabilă estimată a populației, cum ar fi media sau deviația standard. În timp ce un interval de predicție cuantifică incertitudinea pe o singură observație estimată din populație.
în modelarea predictivă, un interval de încredere poate fi utilizat pentru a cuantifica incertitudinea abilității estimate a unui model, în timp ce un interval de predicție poate fi utilizat pentru a cuantifica incertitudinea unei singure prognoze.
un interval de predicție este adesea mai mare decât intervalul de încredere, deoarece trebuie să ia în considerare intervalul de încredere și varianța variabilei de ieșire care este prezisă.
intervalele de predicție vor fi întotdeauna mai largi decât intervalele de încredere , deoarece acestea explică incertitudinea asociată cu e, eroarea ireductibilă.
— pagina 103, o introducere în învățarea Statistică: cu aplicații în R, 2013.
cum se calculează un interval de predicție
un interval de predicție este calculat ca o combinație a varianței estimate a modelului și a varianței variabilei de rezultat.intervalele de predicție sunt ușor de descris, dar dificil de calculat în practică.
în cazuri simple, cum ar fi regresia liniară, putem estima intervalul de predicție direct.
în cazul algoritmilor de regresie neliniară, cum ar fi rețelele neuronale artificiale, este mult mai dificilă și necesită alegerea și implementarea tehnicilor specializate. Pot fi utilizate tehnici generale, cum ar fi metoda de reeșantionare bootstrap, dar sunt costisitoare din punct de vedere al calculului.
lucrarea „O revizuire cuprinzătoare a intervalelor de predicție bazate pe rețele neuronale și a noilor progrese” oferă un studiu rezonabil recent al intervalelor de predicție pentru modelele neliniare în contextul rețelelor neuronale. Următoarea listă rezumă câteva metode care pot fi utilizate pentru incertitudinea de predicție pentru modelele neliniare de învățare automată:
- metoda Delta, din domeniul regresiei neliniare.
- metoda Bayesiană, din modelarea și statisticile Bayesiene.
- metoda de estimare a varianței medii, folosind statistici estimate.
- metoda Bootstrap, folosind reeșantionarea datelor și dezvoltarea unui ansamblu de modele.
putem face calculul unui interval de predicție concret cu un exemplu lucrat în secțiunea următoare.
interval de predicție pentru regresia liniară
o regresie liniară este un model care descrie combinația liniară de intrări pentru a calcula variabilele de ieșire.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
nu cunoaștem adevăratele valori ale coeficienților b0 și b1. De asemenea, nu cunoaștem parametrii adevărați ai populației, cum ar fi media și abaterea standard pentru x sau y. toate aceste elemente trebuie estimate, ceea ce introduce incertitudine în utilizarea modelului pentru a face predicții.
putem face unele presupuneri, cum ar fi distribuțiile lui x și y și erorile de predicție făcute de model, numite reziduuri, sunt gaussiene.
intervalul de predicție în jurul yhat poate fi calculat după cum urmează:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
nu știm în practică. Putem calcula o estimare imparțială a deviației standard prezise după cum urmează (preluată din abordările de învățare automată pentru estimarea intervalului de predicție pentru ieșirea modelului):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
exemplu lucrat
să concretizăm cazul intervalelor de predicție a regresiei liniare cu un exemplu lucrat.
în primul rând, să definim un simplu set de date cu două variabile în care variabila de ieșire (y) depinde de variabila de intrare (x) cu un zgomot Gaussian.
exemplul de mai jos definește setul de date pe care îl vom folosi pentru acest exemplu.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# generați variabile conexe
din import numpy medie
din import NumPy std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
se creează apoi un grafic al setului de date.
putem vedea relația liniară clară dintre variabile cu răspândirea punctelor care evidențiază zgomotul sau eroarea aleatorie din relație.
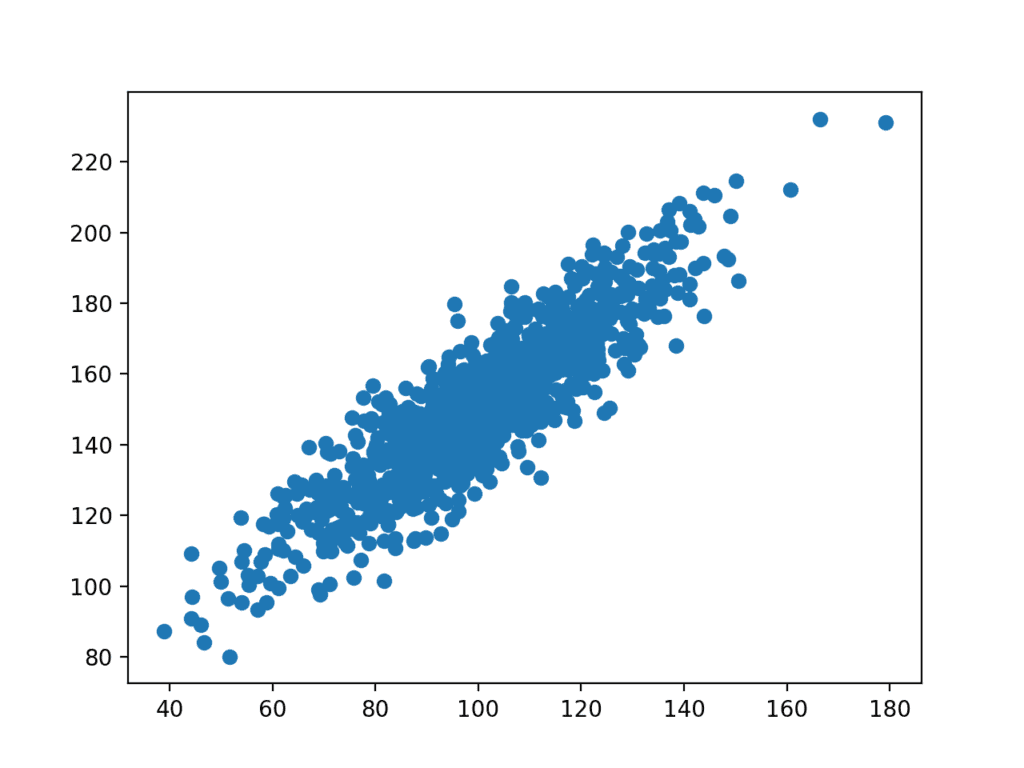
Grafic Scatter de variabile conexe
în continuare, putem dezvolta o regresie liniară simplă care, având în vedere variabila de intrare x, va prezice variabila Y. Putem folosi funcția linregress () SciPy pentru a se potrivi modelului și a returna coeficienții b0 și B1 pentru model.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# model simplu de regresie neliniară
din numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‘b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
B0=1.011, B1=49.117
|
coeficienții sunt apoi utilizați cu intrările din setul de date pentru a face o predicție. Intrările rezultate și valorile y prezise sunt reprezentate ca o linie deasupra graficului scatter pentru setul de date.
putem vedea clar că modelul a învățat relația de bază în setul de date.
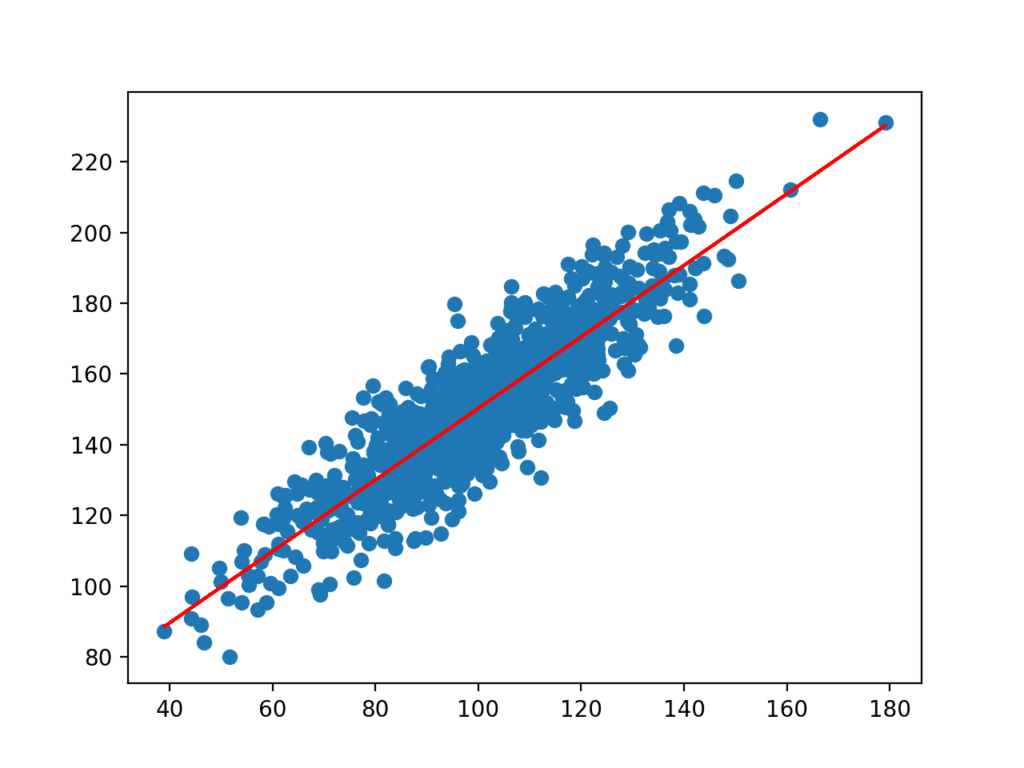
Grafic Scatter set de date cu linie pentru modelul de regresie liniară simplă
acum suntem gata să facem o predicție cu modelul nostru de regresie liniară simplă și să adăugăm un interval de predicție.
vom potrivi modelul ca înainte. De data aceasta vom lua un eșantion din setul de date pentru a demonstra intervalul de predicție. Vom folosi intrarea pentru a face o predicție, vom calcula intervalul de predicție pentru predicție și vom compara predicția și intervalul cu valoarea așteptată cunoscută.
în primul rând, să definim valorile de intrare, predicție și așteptate.
|
1
2
3
|
x_in = x
y_out = y
yhat_out = yhat
|
în continuare, putem estima curbura standard în direcția de predicție.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.statistici import linregress
din matplotlib import pyplot
# seed generator de numere aleatoare
seed(1)
# pregătiți datele
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit modelul de regresie neliniară
B1, b0, r_value, p_value, std_err = linregress(x, y)
# Mark predictions
yhat = b0 + B1 * x
# define new input, valoarea așteptată și predicție
x_in = x
y_out = y
yhat_out = yhat
# estimare StDev de yhat
sum_errs = arraysum ((y-yhat) * * 2)
stdev = sqrt(1/(len(y) -2) * sum_errs)
# calculați intervalul de predicție
interval = 1,96 * StDev
imprimare(‘interval de predicție: %.3F’% interval)
lower, upper = yhat_out – interval, yhat_out + interval
print (‘95% %probabilitatea ca valoarea reală este între%.3f și %.3F’ % (inferior, superior))
imprimare (‘valoare reală: %.3f ‘ % y_out)
# set de date complot și predicție cu interval
pyplot.scatter (x, y)
pyplot.plot (x, yhat, color = ‘red’)
pyplot.errorbar(x_in, yhat_out, yerr = interval, culoare = ‘Negru’, fmt= ‘o’)
pyplot.arată ()
|
rularea exemplului estimează deviația standard yhat și apoi calculează intervalul de predicție.
odată calculat, intervalul de predicție este prezentat utilizatorului pentru variabila de intrare dată. Pentru că am inventat acest exemplu, știm adevăratul rezultat, pe care îl afișăm și noi. Putem vedea că, în acest caz, intervalul de predicție de 95% acoperă adevărata valoare așteptată.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
se creează, de asemenea, un grafic care arată setul de date brut ca grafic scatter, predicțiile pentru setul de date ca linie roșie și intervalul de predicție și predicție ca punct negru și, respectiv, linie.
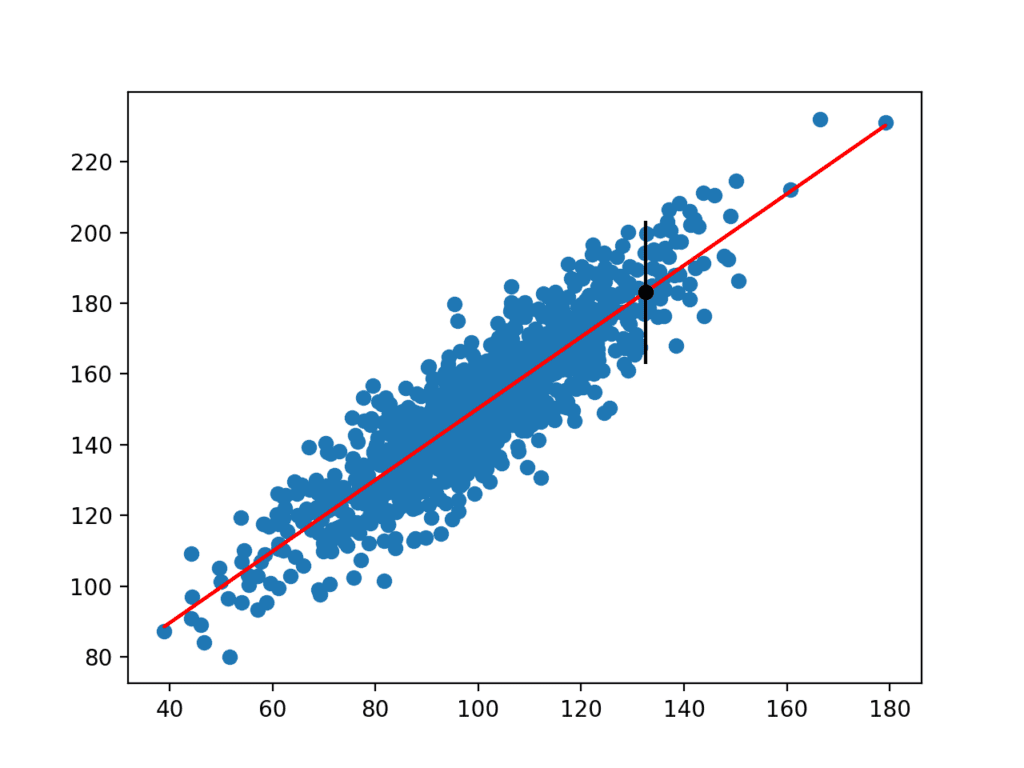
Grafic Scatter set de date cu model liniar și interval de predicție
extensii
această secțiune enumeră câteva idei pentru extinderea tutorialului pe care ați putea dori să-l explorați.
- rezumați diferența dintre intervalele de toleranță, încredere și predicție.
- dezvoltați un model de regresie liniară pentru un set de date standard de învățare automată și calculați intervalele de predicție pentru un set mic de teste.
- descrieți în detaliu modul în care funcționează o metodă de interval de predicție neliniară.
dacă explorați oricare dintre aceste extensii, mi-ar plăcea să știu.
lecturi suplimentare
această secțiune oferă mai multe resurse pe această temă dacă doriți să aprofundați.
postări
- cum se raportează performanța Clasificatorului cu intervale de încredere
- cum se calculează intervalele de încredere Bootstrap pentru rezultatele învățării automate în Python
- înțelegeți incertitudinea prognozei seriilor de timp folosind intervale de încredere cu Python
- estimați numărul de repetări ale experimentului pentru algoritmii de învățare stocastică
Cărți
- înțelegerea noilor statistici: dimensiunile efectului, intervalele de încredere și Meta-analiza, 2017.
- intervale statistice: un ghid pentru practicieni și cercetători, 2017.
- o introducere în învățarea Statistică: cu aplicații în R, 2013.
- Introducere în noile statistici: estimare, știință deschisă și dincolo, 2016.
- Prognoză: principii și practici, 2013.
Papers
- o comparație a unor estimări de eroare pentru modelele de rețele neuronale, 1995.
- abordări de învățare automată pentru estimarea intervalului de predicție pentru producția modelului, 2006.
- o revizuire cuprinzătoare a intervalelor de predicție bazate pe rețele neuronale și a noilor progrese, 2010.
API
- scipy.statistici.linregress () API
- matplotlib.pyplot.scatter () API
- matplotlib.pyplot.errorbar () API
articole
- interval de predicție pe Wikipedia
- interval de predicție Bootstrap pe Cruce validat
rezumat
In acest tutorial, ai descoperit intervalul de predicție și cum să-l calculeze pentru un model simplu de regresie liniară.
în mod specific, ați învățat:
- că un interval de predicție cuantifică incertitudinea unei predicții cu un singur punct.
- că intervalele de predicție pot fi estimate analitic pentru modelele simple, dar sunt mai dificile pentru modelele neliniare de învățare automată.
- cum se calculează intervalul de predicție pentru un model simplu de regresie liniară.
aveți întrebări?
Pune-ți întrebările în comentariile de mai jos și voi face tot posibilul să răspund.
ia un mâner pe statistici pentru machine Learning!

dezvoltă o înțelegere de lucru a statisticilor
…prin scrierea de linii de cod în python
Descoperiți cum în noua mea carte electronică:
metode statistice pentru învățarea automată
oferă tutoriale de auto-studiu pe teme precum:
teste de ipoteze, corelație, statistici neparametrice, reeșantionare și multe altele…
Descoperiți cum să transformați datele în cunoștințe
săriți academicienii. Doar Rezultate.
vezi ce e înăuntru