VMware High Availability (HA) este un utilitar care elimină necesitatea de hardware standby dedicat și software-ul într-un mediu virtualizat. VMware HA este adesea folosit pentru a îmbunătăți fiabilitatea, pentru a reduce timpul de nefuncționare în mediile virtuale și pentru a îmbunătăți recuperarea în caz de dezastru/continuitatea afacerii.
acest capitol extras din examenul Vcp4 Cram: VMware Certified Professional, ediția a 2-A de Elias Khnaser explorează cele mai bune practici VMware HA.
VMware High Availability se ocupă în primul rând de ESX / ESXi host failure și ce se întâmplă cu mașinile virtuale (VMs) care rulează pe această gazdă. HA poate, de asemenea, să monitorizeze și să repornească un VM verificând dacă instrumentele VMware încă rulează. Când o gazdă ESX/ESXi eșuează din orice motiv, toate VM-urile care rulează nu reușesc. VMware HA asigură că VM-urile de la gazda eșuată sunt capabile să fie repornite pe alte gazde ESX/ESXi.
mulți oameni confundă greșit VMware HA cu toleranța la erori. VMware HA nu este tolerant la erori prin faptul că, dacă o gazdă eșuează, VM-urile de pe ea nu reușesc. HA se ocupă doar de repornirea acelor VM-uri pe alte gazde ESX/ESXi cu resurse suficiente. Toleranța la erori, pe de altă parte, oferă acces neîntreruptibil la resurse în cazul unei defecțiuni a gazdei.
 Faceți clic pe imaginea de copertă a cărții de mai sus
Faceți clic pe imaginea de copertă a cărții de mai sus pentru a descărca întregul capitol al lui Elias Khnaser
despre backup și disponibilitate ridicată.
VMware HA menține un canal de comunicare cu toate celelalte gazde ESX / ESXi care sunt membre ale aceluiași cluster utilizând o bătaie de inimă pe care o trimite la fiecare 1 secundă în vSphere 4.0 sau la fiecare 10 secunde în vSphere 4.1 în mod implicit. Când un server ESX ratează o bătaie de inimă, celelalte gazde așteaptă 15 secunde pentru ca cealaltă gazdă să răspundă din nou. După 15 secunde, cluster inițiază repornirea VMs pe ESX/ESXi gazdă lipsa pe gazdele ESX/ESXi rămase în cluster. De asemenea, VMware HA monitorizează constant gazdele ESX/ESXi care sunt membre ale clusterului și se asigură că resursele sunt întotdeauna disponibile pentru a satisface cerințele în cazul unei defecțiuni a gazdei.
monitorizarea defecțiunilor mașinii virtuale
monitorizarea defecțiunilor mașinii virtuale este o tehnologie dezactivată în mod implicit. Funcția sa este de a monitoriza mașinile virtuale, pe care le interoghează la fiecare 20 de secunde printr-o bătăi de inimă. Ea face acest lucru prin utilizarea instrumentelor VMware care sunt instalate în interiorul VM. Când un VM ratează o bătaie de inimă, VMware HA consideră că acest VM a eșuat și încearcă să-l reseteze. Gândiți-vă la monitorizarea defecțiunilor mașinii virtuale ca la un fel de disponibilitate ridicată pentru VMs.
monitorizarea defecțiunilor mașinii virtuale poate detecta dacă o mașină virtuală a fost oprită, suspendată sau migrată manual și, prin urmare, nu încearcă să o repornească.
cerințe preliminare de configurare VMware HA
HA necesită următoarele cerințe preliminare de configurare înainte de a putea funcționa corect:
- vCenter: deoarece VMware HA este o caracteristică de clasă enterprise, necesită vCenter înainte de a putea fi activată.
- rezoluție DNS: toate gazdele ESX/ESXi care sunt membre ale clusterului HA trebuie să se poată rezolva reciproc folosind DNS.
- acces la stocare partajată: toate gazdele din clusterul HA trebuie să aibă acces și vizibilitate la același spațiu de stocare partajat; în caz contrar, nu ar avea acces la VMs.
- acces la aceeași rețea: Toate gazdele ESX / ESXi trebuie să aibă aceleași rețele configurate pe toate gazdele, astfel încât atunci când un VM este repornit pe orice gazdă, acesta are din nou acces la rețeaua corectă.
redundanța consolei de servicii
practica recomandată dictează ca consola de servicii (SC) să aibă redundanță. VMware HA se plânge și emite un avertisment dacă detectează că consola de servicii este configurată pe un vSwitch cu un singur vmnic. După cum arată Figura 1, Puteți configura redundanța consolei de servicii într-unul din cele două moduri:
- creați două grupuri de porturi ale consolei de servicii, fiecare pe un vSwitch diferit.
- atribuiți două plăci de interfață de rețea fizică (Nic) sub forma unei echipe NIC la consola de servicii vSwitch.
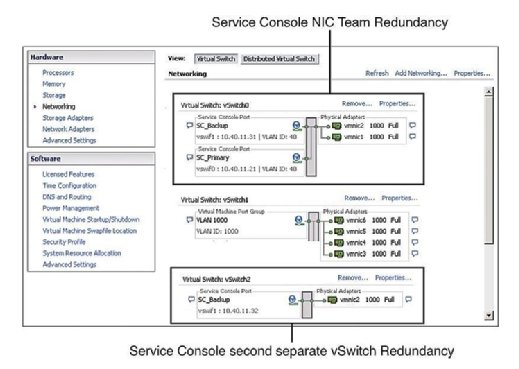
în ambele cazuri, trebuie să configurați întreaga stivă IP cu adresa IP, subrețea și gateway. VSwitch-urile consolei de servicii sunt utilizate pentru bătăile inimii și sincronizarea stării și utilizează următoarele porturi:
- port TCP de intrare 8042
- port UDP de intrare 8045
- port TCP de ieșire 2050
- port UDP de ieșire 2250
- port TCP de intrare 8042-8045
- port UDP de intrare 8042-8045
- port TCP de ieșire 2050-2250
- portul UDP de ieșire 2050-2250
eșecul configurării redundanței SC are ca rezultat un mesaj de avertizare atunci când activați ha. Deci, pentru a evita să vedeți acest mesaj de eroare și să respectați cele mai bune practici, configurați SC să fie redundant.
Host failover capacity planning
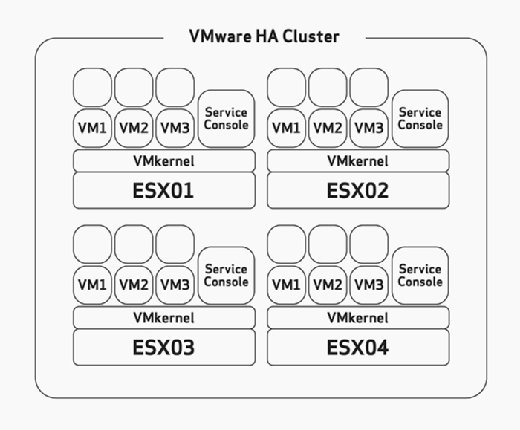
când configurați HA, trebuie să configurați manual toleranța maximă de eșec gazdă. Aceasta este o sarcină pe care ar trebui să o luați în considerare cu atenție în timpul fazei de dimensionare și planificare hardware a implementării. Acest lucru ar presupune că ați construit gazdele ESX/ESXi cu suficiente resurse pentru a rula mai multe VM-uri decât era planificat pentru a putea găzdui HA. De exemplu, în Figura 2, observați că clusterul HA are patru gazde ESX și că toate aceste patru gazde au o capacitate suficientă pentru a rula cel puțin încă trei VM-uri. Deoarece toate rulează deja trei VM-uri, asta înseamnă că acest cluster își poate permite pierderea a două gazde ESX/ESXi, deoarece celelalte două gazde ESX/ESXi pot porni cele șase VM-uri eșuate fără nicio problemă dacă apare eșecul.
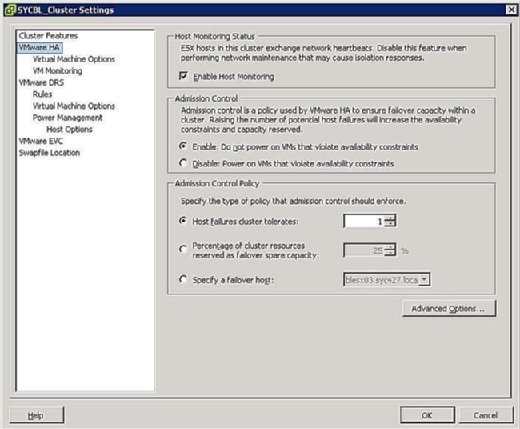
în timpul fazei de configurare a clusterului HA, vi se prezintă un ecran similar cu cel prezentat în Figura 3 care vă solicită să definiți două configurații la nivel de grup, după cum urmează:
- Host Monitoring Status:
- Enable Host Monitoring: această setare vă permite să controlați dacă clusterul HA ar trebui să monitorizeze gazdele pentru o bătaie de inimă. Acesta este modul clusterului de a determina dacă o gazdă este încă activă. În unele cazuri, când executați activități de întreținere pe gazdele ESX/ESXi, poate fi de dorit să dezactivați această opțiune pentru a evita izolarea unei gazde.
- controlul admiterii:
- activare: nu porniți VMs care încalcă constrângerile de disponibilitate: Selectarea acestei opțiuni indică faptul că, dacă nu sunt disponibile resurse pentru a satisface un VM, acesta nu ar trebui să fie pornit.
- Disable: Power On VMs care încalcă constrângerile de disponibilitate: selectarea acestei opțiuni indică faptul că ar trebui să porniți un VM chiar dacă trebuie să overcommit resurse.
- Politica de control admitere:
- gazdă eșecuri cluster tolerează: această setare vă permite să configurați cât de multe eșecuri gazdă pe care doriți să tolereze. Setările permise sunt de la 1 la 4.
- procentul resurselor de cluster rezervate ca capacitate neutilizată în caz de eșec: Selectarea acestei opțiuni indică faptul că rezervați un procent din totalul resurselor de cluster în rezervă pentru failover. Într-un cluster cu patru gazde, o rezervare de 25% indică faptul că puneți deoparte o gazdă completă pentru failover. Dacă doriți să puneți deoparte mai puține, puteți alege în schimb 10% din resursele clusterului.
- specificați o gazdă de reluare: selectarea acestei opțiuni indică faptul că selectați o anumită gazdă ca gazdă de reluare în cluster. Acest lucru ar putea fi cazul dacă aveți o gazdă de rezervă sau aveți o anumită gazdă care are semnificativ mai multe resurse de calcul și memorie disponibile.
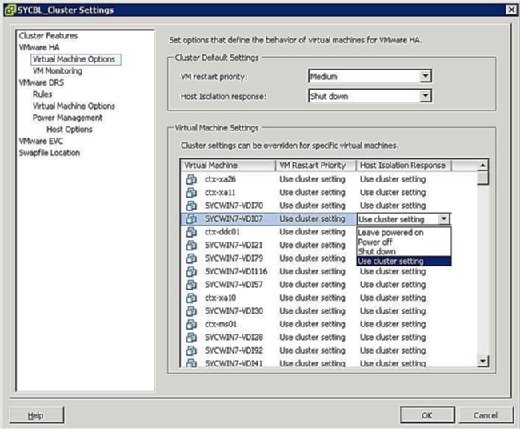
izolarea gazdei
un fenomen de rețea cunoscut sub numele de creier divizat apare atunci când gazda ESX / ESXi a încetat să mai primească bătăi de inimă de la restul clusterului. Bătăile inimii sunt interogate pentru fiecare secundă în vSphere 4.0 sau 10 secunde în vSphere 4.1. Dacă un răspuns nu este primit, clusterul crede că gazda ESX/ESXi a eșuat. Când se întâmplă acest lucru, gazda ESX/ESXi și-a pierdut conectivitatea la rețea pe interfața sa de gestionare. Gazda ar putea fi încă în funcțiune, iar VMs-urile ar putea să nu fie chiar afectate, având în vedere că ar putea utiliza o interfață de rețea diferită care nu a fost afectată. Cu toate acestea, vSphere trebuie să ia măsuri atunci când se întâmplă acest lucru, deoarece crede că o gazdă a eșuat. De altfel, a fost creat răspunsul de izolare a gazdei. Răspunsul de izolare a gazdei este modul HA de a trata o gazdă ESX / ESXi care și-a pierdut conexiunea la rețea.
puteți controla ce se întâmplă cu VMs în cazul unei izolări a gazdei. Pentru a ajunge la ecranul de răspuns la izolarea VM, faceți clic dreapta pe clusterul în cauză și faceți clic pe Editare setări. Apoi puteți face clic pe Opțiuni mașină virtuală sub bannerul VMware HA din panoul din stânga. Puteți controla opțiunile clusterwide prin setarea opțiunii de răspuns de izolare gazdă în consecință. Acest lucru se aplică tuturor VM-urilor de pe gazda afectată. Acestea fiind spuse, puteți oricând să suprascrieți setările clusterului definind un răspuns diferit la nivelul VM.
după cum se arată în Figura 4, opțiunile de răspuns la izolare sunt următoarele:
- lăsați pornit: după cum sugerează eticheta, această setare înseamnă că, în cazul izolării gazdei, VM rămâne pornit.
- oprire: această setare definește că, în cazul unei izolări, VM este oprit. Aceasta este o putere greu oprit.
- Shut down: această setare definește că, în cazul unei izolări, VM este închis cu grație folosind instrumente VMware. Dacă această sarcină nu este finalizată cu succes în decurs de cinci minute, se execută imediat o oprire. Dacă VMware Tools nu este instalat, se execută în schimb o oprire.
- Use Cluster Setting: această setare redirecționează taskul către setarea clusterwide definită în fereastra prezentată anterior în Figura 4.
în cazul unei izolări, acest lucru nu înseamnă neapărat că gazda este în jos. Deoarece VM-urile ar putea fi configurate cu NIC-uri fizice diferite și conectate la rețele diferite, acestea ar putea continua să funcționeze corect; prin urmare, trebuie să luați în considerare acest lucru atunci când setați prioritatea pentru izolare. Când o gazdă este izolată, aceasta înseamnă pur și simplu că consola sa de servicii nu poate comunica cu restul gazdelor ESX/ESXi din cluster.
prioritate de recuperare mașină virtuală
în cazul în care clusterul HA nu poate găzdui toate VM-urile în caz de eșec, aveți capacitatea de a acorda prioritate VM-urilor. Prioritățile dictează care VM-uri sunt repornite mai întâi și care VM-uri nu sunt atât de importante în caz de urgență. Aceste opțiuni sunt configurate pe același ecran ca și răspunsul de izolare acoperit în secțiunea precedentă. Puteți configura setările clusterului care vor fi aplicate tuturor VM-urilor de pe gazda afectată sau puteți suprascrie setările clusterului configurând o suprascriere la nivelul VM.
puteți seta prioritatea de repornire a unui VM la una dintre următoarele:
- High: VM-urile cu prioritate ridicată sunt repornite mai întâi.
- Mediu: aceasta este setarea implicită.
- Low: VM – urile cu prioritate redusă sunt repornite ultima dată.
- utilizați setarea clusterului: VM-urile sunt repornite pe baza setării definite la nivelul clusterului definit în fereastra prezentată în figura de mai jos.
- dezactivat: VM nu pornește.
prioritatea trebuie stabilită pe baza importanței VMs. Cu alte cuvinte, este posibil să doriți să reporniți controlerele de domeniu și să nu reporniți serverele de imprimare. Mașinile virtuale cu prioritate mai mare sunt repornite mai întâi. VM – urile care pot tolera oprirea rămasă în caz de urgență ar trebui configurate pentru a rămâne oprite pentru a economisi resurse.
MSCS clustering
scopul principal al unui cluster este de a se asigura că sistemele critice rămân online cu orice preț și în orice moment. Similar cu mașinile fizice care pot fi grupate, mașinile virtuale pot fi, de asemenea, grupate cu ESX folosind trei scenarii diferite:
- Cluster-in-a-box: în acest scenariu, toate VM-urile care fac parte din cluster se află pe aceeași gazdă ESX/ESXi. După cum probabil ați ghicit, acest lucru creează imediat un singur punct de eșec: gazda ESX/ESXi. În ceea ce privește stocarea partajată, puteți utiliza discuri virtuale ca stocare partajată în acest scenariu sau puteți utiliza maparea dispozitivelor Raw (RDM) în modul de compatibilitate virtuală.
- cluster-across-boxes: în acest scenariu, nodurile clusterului (VM-urile care sunt membre ale clusterului) se află pe mai multe gazde ESX/ESXi, prin care fiecare dintre nodurile care alcătuiesc clusterul poate accesa același spațiu de stocare, astfel încât, dacă un VM eșuează, celălalt poate continua să funcționeze și să acceseze aceleași date. Acest scenariu creează un mediu de cluster ideal prin eliminarea unui singur punct de eșec. Stocarea partajată este o condiție prealabilă în acest sens și trebuie să locuiască pe Fibre Channel SAN. De asemenea, trebuie să utilizați un RDM în modul de compatibilitate fizică sau virtuală, deoarece discurile virtuale nu sunt o configurație acceptată pentru stocarea partajată. Prin care fiecare dintre nodurile care alcătuiesc clusterul poate accesa același spațiu de stocare, astfel încât, dacă un VM eșuează, celălalt poate continua să funcționeze și să acceseze aceleași date.
- cluster fizic-virtual: În acest scenariu, un membru al clusterului este o mașină virtuală, în timp ce celălalt membru este o mașină fizică. Stocarea partajată este o condiție prealabilă în acest scenariu și trebuie configurată ca RDM în modul de compatibilitate fizică.
ori de câte ori proiectați o soluție de grupare, trebuie să abordați problema stocării partajate, care ar permite mai multor gazde sau VMs acces la aceleași date. vSphere oferă mai multe metode prin care puteți furniza stocare partajată după cum urmează:
- discuri virtuale: Puteți utiliza un disc virtual ca zonă de stocare partajată numai dacă faceți gruparea într-o cutie-cu alte cuvinte, numai dacă ambele VM-uri se află pe aceeași gazdă ESX/ESXi.
- RDM în modul de compatibilitate fizică: acest mod vă permite să atașați un LUN fizic direct într-o mașină VM sau fizică. Acest mod vă împiedică să utilizați funcționalități precum instantanee și este utilizat în mod ideal atunci când un membru al clusterului este o mașină fizică, în timp ce celălalt este un VM.
- RDM în modul de compatibilitate virtuală: acest mod vă permite să atașați un LUN fizic direct într-o mașină VM sau fizică. Acest mod vă oferă toate avantajele discurilor virtuale care rulează pe VMFS, inclusiv instantanee și blocarea avansată a fișierelor. Discul este accesat prin hipervizor și este ideal atunci când configurați un scenariu cluster-peste-cutii în care trebuie să oferiți ambelor VMs acces la stocarea partajată.
la momentul scrierii acestui articol, singurul serviciu de clustering acceptat de VMware este Microsoft Clustering Services (MSCS). Puteți consulta cartea albă VMware ” Setup for failover Clustering and Microsoft Cluster Service.”
VMware Fault Tolerance
VMware Fault Tolerance (FT) este o altă formă de grupare VM dezvoltată de VMware pentru sisteme care necesită timp de funcționare extrem. Una dintre cele mai convingătoare caracteristici ale FT este ușurința de configurare. FT este pur și simplu o casetă de selectare care poate fi activată. Comparativ cu gruparea tradițională care necesită configurații specifice și, în unele cazuri, cablare, FT este simplu, dar puternic.
cum funcționează?
la protejarea VMs cu FT, un VM secundar este creat în lockstep de vm protejat, primul vm. FT funcționează scriind simultan la primul VM și al doilea VM în același timp. Fiecare sarcină este scrisă de două ori. Dacă faceți clic pe meniul Start de pe primul VM, se va face clic și pe meniul Start de pe al doilea VM. Puterea FT este capacitatea sa de a menține ambele VM-uri în sincronizare.
dacă VM-ul protejat ar trebui să coboare din orice motiv, VM-ul secundar își ia imediat locul, confiscându-și identitatea și adresa IP, continuând să deservească utilizatorii fără întrerupere. Noul vm protejat promovat creează apoi un secundar pentru el însuși pe o altă gazdă și ciclul repornește.
pentru a clarifica, să vedem un exemplu. Dacă doriți să protejați un server Exchange, puteți activa FT. Dacă, din orice motiv, gazda ESX/ESXi care transportă VM protejat eșuează, vm secundar intră și își asumă sarcinile fără o întrerupere a serviciului.
tabelul de mai jos prezintă diferitele tehnologii de disponibilitate ridicată și clustering la care aveți acces cu vSphere și evidențiază limitările fiecăruia.

cerințe de toleranță la erori
toleranța la erori nu este diferită de orice altă caracteristică a întreprinderii prin faptul că necesită anumite condiții prealabile pentru a fi îndeplinite înainte. Aceste cerințe sunt prezentate în următoarea listă și defalcate în diferite categorii care necesită cerințe minime specifice:
- cerințe gazdă:
- CPU compatibil FT. Verificați acest articol VMware KB pentru mai multe informații.
- virtualizarea Hardware trebuie activată în bios.
- vitezele ceasului procesorului gazdei trebuie să fie la 400 MHz una de cealaltă.
- cerințe VM:
- VMs trebuie să se afle pe spațiul de stocare partajat acceptat (FC, iSCSI și NFS).
- VMs trebuie să ruleze un sistem de operare acceptat.
- VM-urile trebuie stocate fie într-un VMDK, fie într-un RDM virtual.
- VMs nu poate fi prevăzut subțire VMDK și trebuie să utilizeze un disc virtual Eagerzeroedthick.
- VMs nu poate avea mai mult de un vCPU configurat.
- cerințe de Cluster:
- toate gazdele ESX / ESXi trebuie să fie aceeași versiune și același nivel de patch-uri.
- toate gazdele ESX / ESXi trebuie să aibă acces la magazinele de date și rețelele VM.
- VMware HA trebuie să fie activat pe cluster.
- fiecare gazdă trebuie să aibă un VMotion și FT logare Nic configurat.
- verificarea certificatului gazdă trebuie, de asemenea, să fie activată.
este foarte recomandabil ca, pe lângă verificarea compatibilității procesorului cu FT, să verificați compatibilitatea mărcii și modelului serverului dvs. cu FT împotriva listei de compatibilitate Hardware VMware (HCL).în timp ce FT este o soluție excelentă de grupare, este important să rețineți că are și anumite limitări. De exemplu, Ft VM-urile nu pot fi snapshotted și nu pot fi Vmotioned de stocare. De fapt, aceste VM-uri vor fi marcate automat Drs-dezactivat și nu vor participa la nicio echilibrare dinamică a încărcării resurselor.
cum se activează FT
activarea FT nu este dificilă, dar implică configurarea câtorva setări diferite. Următoarele setări trebuie să fie configurate corect pentru ca FT să funcționeze:
- activați verificarea certificatului gazdă: Pentru a activa această setare, conectați-vă la serverul vCenter și faceți clic pe Administrare din meniul fișier și faceți clic pe Setări Server vCenter. În panoul din stânga, faceți clic pe Setări SSL și bifați caseta vCenter Requires Verified host SSL Certificates.
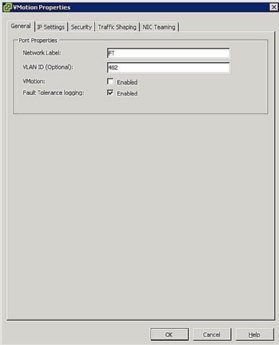
Figura 5. Setările grupului de porturi FT - configurați rețeaua gazdă: Configurația de rețea pentru FT este ușoară și urmează aceiași pași și proceduri ca vMotion, cu excepția cazului în care bifați caseta vMotion, bifați caseta de înregistrare a toleranței la erori așa cum se arată în Figura 5.
- pornirea FT On și Off: odată ce ați îndeplinit cerințele anterioare, puteți activa acum FT on și off pentru VMs. Acest proces este, de asemenea, simplu: Găsiți VM-ul pe care doriți să îl protejați, faceți clic dreapta pe el și selectați toleranță la erori>activați toleranța la erori.
în timp ce FT este o tehnologie de clustering de primă generație, funcționează impresionant de bine și simplifică metodele tradiționale supracomplicate de construire, configurare și întreținere a clusterelor. FT este o tehnologie impresionantă pentru un punct de vedere uptime și dintr-un punct de vedere failover fără sudură.