informații despre versiune: codul pentru această pagină a fost testat în Stata 12.
regresia Poisson este utilizată pentru a modela variabilele de numărare.
vă rugăm să rețineți: scopul acestei pagini este de a arăta cum să utilizați diferite comenzi de analiză a datelor. Nu acoperă toate aspectele procesului de cercetare pe care se așteaptă să le facă cercetătorii. În special, acesta nu acoperă curățarea și verificarea datelor, verificarea ipotezelor, diagnosticarea modelelor sau eventualele analize ulterioare.
Exemple de regresie Poisson
Exemplul 1. Numărul de persoane ucise de catâr sau lovituri de cal în armata prusacă pe an.Ladislaus Bortkiewicz a colectat date din 20 de volume Depreussischen Statistik. Aceste date au fost colectate pe 10 corpuri ale armatei prusace la sfârșitul anilor 1800 pe parcursul a 20 de ani.
Exemplul 2. Numărul de persoane în linie în fața ta la magazin alimentar. Predictorii pot include numărul de articole oferite în prezent la un preț redus special și dacă un eveniment special (de exemplu, o vacanță, un eveniment sportiv mare) este la trei sau mai puține zile distanță.
Exemplul 3. Numărul de premii câștigate de elevi la un liceu. Predictorii numărului de premii câștigate includ tipul de program în care studentul a fost înscris (de exemplu, profesional, general sau academic) și scorul la examenul final la matematică.
descrierea datelor
în scopul ilustrării, am simulat un set de date de exemplu 3 de mai sus. În acest exemplu, num_awards este variabila de rezultat și indică numărul de premii câștigate de elevi la un liceu într-un an, matematica este o variabilă predictor continuu și reprezintă scorurile elevilor la examenul final de Matematică, iar prog este o variabilă predictor categorică cu trei niveluri care indică tipul de program în care au fost înscriși elevii.
să începem cu încărcarea datelor și să analizăm câteva statistici descriptive.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
fiecare variabilă are 200 de observații valide și distribuțiile lor par destul de rezonabile. În acest sens, media necondiționată și varianța variabilei noastre de rezultat nu sunt extrem de diferite.
să continuăm cu descrierea variabilelor din acest set de date. Tabelul de mai jos arată numărul mediu de premii în funcție de tipul de program și pare să sugereze că tipul de program este un bun candidat pentru prezicerea numărului de premii, variabila noastră de rezultat, deoarece valoarea medie a rezultatului pare să varieze în funcție de prog.
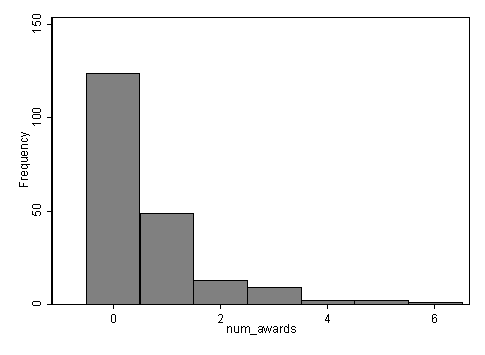
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
metode de analiză puteți lua în considerare
mai jos este o listă a unor metode de analiză pe care le-ați întâlnit. Unele dintre metodele enumerate sunt destul de rezonabile, în timp ce altele au căzut din favoare sau au limitări.
- regresia Poisson – regresia Poisson este adesea folosită pentru modelarea datelor de numărare. Regresia Poisson are o serie de extensii utile pentru modelele de numărare.
- regresia binomială negativă – regresia binomială negativă poate fi utilizată pentru datele de numărare supra-dispersate, adică atunci când varianța condiționată depășește media condiționată. Poate fi considerată ca o generalizare a regresiei Poisson, deoarece are aceeași structură medie ca regresia Poisson și are un parametru suplimentar pentru a modela supra-dispersia. Dacă distribuția condiționată a variabilei de rezultat este supra-dispersată, intervalele de încredere pentru regresia binomială negativă sunt probabil mai restrânse în comparație cu cele dintr-o regresie Poisson.
- modelul de regresie umflat Zero-modelele umflate Zero încearcă să țină cont de excesul de zerouri. Cu alte cuvinte, se crede că există două tipuri de zerouri în date, „zerouri adevărate” și „zerouri în exces”. Modelele umflate la Zero estimează două ecuații simultan, una pentru modelul de numărare și una pentru zerourile în exces.
- variabilele de rezultat ale numărului de regresii OLS sunt uneori transformate în jurnal și analizate folosind regresia OLS. Multe probleme apar cu această abordare, inclusiv pierderea de date din cauza valorilor nedefinite generate de luarea jurnalului de zero (care este nedefinit) și estimări părtinitoare.
regresia Poisson
mai jos folosim comanda poisson pentru a estima un model de regresie Poisson. I. înainte de prog indică faptul că este o variabilă factor (adică., variabilă categorică) și că ar trebui inclusă în model ca o serie de variabile indicatoare.
folosim opțiunea vce(robust) pentru a obține erori standard robuste pentru estimările parametrilor recomandate de Cameron și Trivedi (2009) pentru a controla încălcarea ușoară a ipotezelor subiacente.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
testul chi-pătrat cu două grade de libertate indică faptul că prog, luat împreună, este un predictor semnificativ statistic al num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
pentru a ajuta la evaluarea potrivirii modelului, comanda estat gof poate fi utilizată pentru a obține testul chi-pătrat al bunătății. Acesta nu este un test al coeficienților modelului (pe care l-am văzut în informațiile antetului), ci un test al formularului modelului: formularul modelului poisson se potrivește datelor noastre?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
concluzionăm că modelul se potrivește destul de bine, deoarece testul chi-pătrat nu este semnificativ statistic. Dacă testul ar fi fost semnificativ statistic, ar indica faptul că datele nu se potrivesc bine modelului. În această situație, putem încerca să determinăm dacă există variabile predictoare omise, dacă ipoteza noastră de liniaritate este valabilă și/sau dacă există o problemă de supra-dispersie.
uneori, am putea dori să prezinte rezultatele de regresie ca raporturi rata incidentelor, putem folosi opțiunea lorr. Aceste valori IRR sunt egale cu coeficienții noștri de la ieșirea de mai sus exponențiată.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
ieșirea de mai sus indică faptul că rata incidentului pentru 2.prog este de 2,96 ori rata incidentelor pentru grupul de referință (1.prog). De asemenea, rata incidentului pentru 3.prog este de 1,45 ori rata incidentelor pentru grupul de referință care deține celelalte variabile constante. Modificarea procentuală a ratei incidentelor num_awards este o creștere de 7% pentru fiecare creștere a unității în matematică.
amintesc forma ecuației noastre model:
log(num_awards) = Intercept + B1(prog=2) + b2(prog=3) + b3math.
aceasta implică:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(B1(prog=2)) * exp(B2(prog=3)) * exp(b3math)
coeficienții au un efect aditiv în scara log(Y), iar IRR au un efect multiplicativ în scara Y.
pentru informații suplimentare despre diferitele valori în care pot fi prezentate rezultatele și interpretarea acestora, consultați Modele de regresie pentru variabile dependente categorice folosind Stata, ediția a doua de J. Scott Long și Jeremy Freese (2006).
pentru a înțelege mai bine modelul, putem folosi comanda margini. Mai jos folosim comanda margini pentru a calcula numărul prezis la fiecare nivel ofprog, ținând toate celelalte variabile (în acest exemplu, matematică) din model la valorile lor medii.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
în rezultatul de mai sus, vedem că numărul prezis de evenimente pentru nivelul 1 al prog este de aproximativ .21, ținând matematica la media sa. Numărul prezis de evenimente pentru nivelul 2 al prog este mai mare la.62, iar numărul prezis de evenimente pentru nivelul 3 al prog este de aproximativ .31. Rețineți că numărul prezis de nivelul 2 al prog este (.6249446/.211411) = de 2,96 ori mai mare decât numărul prevăzut pentru nivelul 1 al prog. Acest lucru se potrivește cu ceea ce am văzut în tabelul de ieșire IRR.
mai jos vom obține numărul prezis pentru valorile matematice care variază de la 35 la 75 în trepte de 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
tabelul de mai sus arată că, cu prog la valorile sale observate și matematica ținută la 35 pentru toate observațiile, numărul mediu prezis (sau numărul mediu de premii) este de aproximativ .13; când matematica = 75, numărul mediu prezis este de aproximativ 2,17. Dacă comparăm numărul prezis la math = 35 și math = 45, putem vedea că raportul este (.2644714/.1311326) = 2.017. Aceasta se potrivește cu IRR de 1.0727 pentru o schimbare de unitate 10: 1.0727^10 = 2.017.
comanda fitstat scrisă de utilizator (precum și comenzile estat ale Stata) pot fi utilizate pentru a obține informații suplimentare care pot fi utile dacă doriți să comparați modele. Puteți tasta Căutare fitstat pentru a descărca acest program (consultați Cum pot folosi comanda de căutare pentru a căuta programe și pentru a obține ajutor suplimentar? pentru mai multe informații despre utilizarea căutării).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
puteți grafic numărul prezis de evenimente cu comenzile de mai jos. Graficul indică faptul că cele mai multe premii sunt prezise pentru cei din programul academic (prog = 2), mai ales dacă elevul are un scor mare la matematică. Cel mai mic număr de premii prezise este pentru acei studenți din programul general (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
lucruri de luat în considerare
- dacă overdispersion pare a fi o problemă, ar trebui mai întâi verificați dacă modelul nostru este specificat corespunzător, cum ar fi variabilele omise și formele funcționale. De exemplu, dacă am omis variabila predictor progin exemplul de mai sus, modelul nostru ar părea să aibă o problemă cu supra-dispersia. Cu alte cuvinte, un model specificat greșit ar putea prezenta un simptom ca o problemă de supra-dispersie.
- presupunând că modelul este specificat corect, poate doriți să verificați foroverdispersion. Există mai multe modalități de a face acest lucru, inclusiv testul raportului de probabilitate al parametrului de supra-dispersie alfa prin rularea aceluiași model de regresie folosind distribuția binomială negativă (nbreg).
- o cauză comună a supra-dispersiei este excesul de zerouri, care la rândul lor sunt generate de un proces suplimentar de generare a datelor. În această situație, ar trebui luat în considerare modelul umflat la zero.
- dacă procesul de generare a datelor nu permite niciun 0s (cum ar fi numărul de zile petrecute în spital), atunci un model trunchiat zero poate fi mai adecvat.
- datele de numărare au adesea o variabilă de expunere, care indică de câte ori s-ar fi putut întâmpla evenimentul. Această variabilă ar trebui încorporată într-un model Poisson cu utilizarea opțiunii exp ().
- variabila de rezultat într-o regresie Poisson nu poate avea numere negative, iar expunerea nu poate avea 0s.
- în Stata, un model Poisson poate fi estimat prin comanda glm cu legătura jurnal și familia Poisson.
- va trebui să utilizați comanda glm pentru a obține reziduurile pentru a verifica alte ipoteze ale modelului Poisson (vezi Cameron și Trivedi (1998) și Dupont (2002) pentru mai multe informații).
- există multe măsuri diferite de pseudo-R-pătrat. Toți încearcă să furnizeze informații similare cu cele furnizate de R-pătrat în regresia OLS, chiar dacă niciunul dintre ele nu poate fi interpretat exact așa cum este interpretat R-pătrat în regresia OLS. Pentru o discuție despre diverse pseudo-r-pătrate, consultați Long and Freese (2006) sau pagina noastră de întrebări frecvente Ce sunt pseudo r-squareds?.
- regresia Poisson este estimată prin estimarea probabilității maxime. De obicei necesită o dimensiune mare a eșantionului.
Vezi și
- ieșire adnotată pentru comanda poisson
- stata Întrebări frecvente: Cum pot folosi countfit în alegerea unui model de numărare?
- stata Online manual
- poisson
- cum sunt calculate erorile standard și intervalele de încredere pentru ratele ratei de incidență (IRR) de către poisson și nbreg?
Stata Întrebări frecvente
- Cameron, A. C. și Trivedi, P. K. (2009). Microeconometrics Folosind Stata. Stația de colegiu, TX: Stata Press.Cameron, A. C. și Trivedi, P. K. (1998). Analiza de regresie a datelor de numărare. New York: Cambridge Press.
- Cameron, A. C. Avansuri în discuția de regresie a datelor de numărare pentru Atelierul de Statistică Aplicată, 28 martie 2009.http://cameron.econ.ucdavis.edu/racd/count.html .
- Dupont, W. D. (2002). Modelarea statistică pentru cercetătorii biomedicali: o simplă introducere în analiza datelor complexe. New York: Cambridge Press.
- Long, J. S. (1997). Modele de regresie pentru variabile dependente categorice și limitate.Thousand Oaks, CA: publicații salvie.
- Long, J. S. și Freese, J. (2006). Modele de regresie pentru variabile dependente categorice folosind Stata, ediția a doua. Stația de colegiu, TX: Stata Press.