Les fonctions d’activation sont la partie la plus cruciale de tout réseau de neurones dans l’apprentissage profond. Dans le deep learning, les tâches très compliquées sont la classification des images, la transformation du langage, la détection d’objets, etc., qui sont nécessaires à l’aide de réseaux de neurones et de la fonction d’activation. Donc, sans cela, ces tâches sont extrêmement complexes à gérer.
En bref, un réseau de neurones est une technique très puissante dans l’apprentissage automatique qui imite fondamentalement comment un cerveau comprend, comment? Le cerveau reçoit les stimuli, en entrée, de l’environnement, les traite et produit ensuite la sortie en conséquence.
Introduction
Les fonctions d’activation du réseau de neurones, en général, sont la composante la plus importante de l’apprentissage profond, elles sont fondamentalement utilisées pour déterminer la sortie des modèles d’apprentissage profond, sa précision et l’efficacité des performances du modèle d’entraînement qui peut concevoir ou diviser un réseau de neurones à grande échelle.
Les fonctions d’activation ont laissé des effets considérables sur la capacité des réseaux de neurones à converger et la vitesse de convergence, ne voulez-vous pas comment? Continuons avec une introduction à la fonction d’activation, les types de fonctions d’activation & leur importance et leurs limites à travers ce blog.
Quelle est la fonction d’activation ?
La fonction d’activation définit la sortie de l’entrée ou de l’ensemble des entrées ou en d’autres termes définit le nœud de la sortie du nœud qui est donnée dans les entrées. Ils décident essentiellement de désactiver les neurones ou de les activer pour obtenir la sortie souhaitée. Il effectue également une transformation non linéaire sur l’entrée pour obtenir de meilleurs résultats sur un réseau neuronal complexe.
La fonction d’activation permet également de normaliser la sortie de toute entrée comprise entre 1 et -1. La fonction d’activation doit être efficace et elle doit réduire le temps de calcul car le réseau neuronal s’entraîne parfois sur des millions de points de données.
La fonction d’activation décide fondamentalement dans n’importe quel réseau neuronal que l’entrée ou la réception d’informations données est pertinente ou non pertinente. Prenons un exemple pour mieux comprendre ce qu’est un neurone et comment la fonction d’activation limite la valeur de sortie à une certaine limite.
Le neurone est essentiellement une moyenne pondérée de l’entrée, puis cette somme est passée par une fonction d’activation pour obtenir une sortie.
Y= ∑(poids * entrée + biais)
Ici, Y peut être n’importe quoi pour un neurone entre la plage – infini et + infini. Nous devons donc lier notre sortie pour obtenir la prédiction souhaitée ou les résultats généralisés.
Y= Fonction d’activation(∑(poids*entrée + biais))
Nous transmettons donc ce neurone à la fonction d’activation aux valeurs de sortie liées.
Pourquoi avons-nous besoin de Fonctions d’activation?
Sans fonction d’activation, le poids et le biais n’auraient qu’une transformation linéaire, ou le réseau de neurones n’est qu’un modèle de régression linéaire, une équation linéaire est un polynôme d’un seul degré qui est simple à résoudre mais limité en termes de capacité à résoudre des problèmes complexes ou des polynômes de degré supérieur.
Mais à l’opposé de cela, l’ajout d’une fonction d’activation au réseau de neurones exécute la transformation non linéaire en entrée et la rend capable de résoudre des problèmes complexes tels que les traductions linguistiques et les classifications d’images.
En plus de cela, les fonctions d’activation sont différentiables grâce auxquelles elles peuvent facilement mettre en œuvre des propagations arrières, une stratégie optimisée tout en effectuant des rétropropagations pour mesurer les fonctions de perte de gradient dans les réseaux de neurones.
Types de Fonctions d’activation
Les fonctions d’activation les plus célèbres sont données ci-dessous,
-
Étape binaire
-
Linéaire
-
ReLU
-
LeakyReLU
-
Sigmoïde
-
Tanh
-
Softmax
1. Fonction d’activation d’étape binaire
Cette fonction d’activation est très basique et cela nous vient à l’esprit à chaque fois que nous essayons de lier la sortie. C’est essentiellement un classificateur de base de seuil, en cela, nous décidons d’une valeur de seuil pour décider de la sortie que le neurone doit être activé ou désactivé.
f(x)= 1 si x > 0 sinon 0 si x < 0
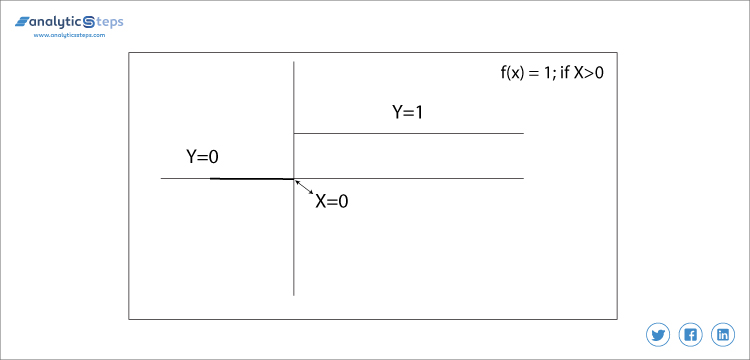
Fonction d’étape binaire
Dans ce cas, nous décidons de la valeur de seuil à 0. Il est très simple et utile de classer les problèmes binaires ou le classificateur.
2. Fonction d’activation linéaire
C’est une simple fonction d’activation en ligne droite où notre fonction est directement proportionnelle à la somme pondérée des neurones ou de l’entrée. Les fonctions d’activation linéaires sont meilleures pour donner une large gamme d’activations et une ligne de pente positive peut augmenter la cadence de tir à mesure que la cadence d’entrée augmente.
En binaire, un neurone se déclenche ou non. Si vous connaissez la descente de gradient en apprentissage profond, vous remarquerez que dans cette fonction, la dérivée est constante.
Y=mZ
Où la dérivée par rapport à Z est constante m. Le gradient de signification est également constant et cela n’a rien à voir avec Z. En cela, si les modifications apportées à la rétropropagation seront constantes et ne dépendront pas de Z, ce ne sera donc pas bon pour l’apprentissage.
En cela, notre deuxième couche est la sortie d’une fonction linéaire de l’entrée des couches précédentes. Attendez une minute, qu’avons-nous appris en cela que si nous comparons toutes nos couches et supprimons toutes les couches sauf la première et la dernière, nous ne pouvons également obtenir qu’une sortie qui est une fonction linéaire de la première couche.
3. Fonction d’activation ReLU (Unité linéaire rectifiée)
L’unité linéaire rectifiée ou ReLU est la fonction d’activation la plus largement utilisée actuellement qui va de 0 à l’infini, Toutes les valeurs négatives sont converties en zéro, et ce taux de conversion est si rapide que ni elle ne peut cartographier ni s’intégrer correctement dans les données, ce qui crée un problème, mais là où il y a un problème, il y a une solution.
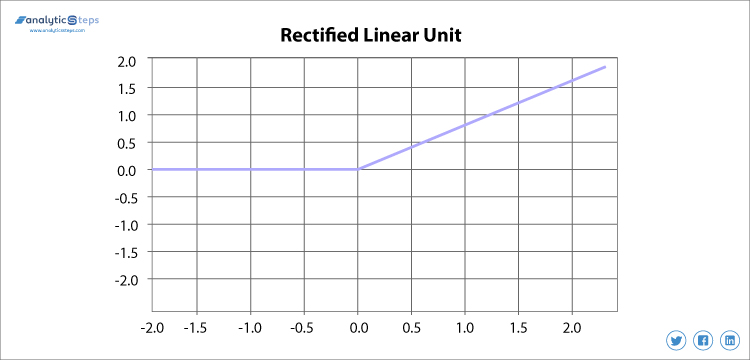
Fonction d’activation de l’unité linéaire rectifiée
Nous utilisons la fonction RELU Leaky au lieu de ReLU pour éviter cela, la gamme Relu Leaky est étendue, ce qui améliore les performances.
Fonction d’activation RELU Leaky
Fonction d’activation de ReLU qui fuit
Nous avions besoin de la fonction d’activation de ReLU qui fuit pour résoudre le problème de « ReLU mourant », comme discuté dans ReLU, nous observons que toutes les valeurs d’entrée négatives se transforment très rapidement en zéro et dans le cas de ReLU qui fuit, nous ne faisons pas toutes les entrées négatives à zéro mais à une valeur proche de zéro qui résout le problème majeur de la fonction d’activation de ReLU.
Fonction d’activation sigmoïde
La fonction d’activation sigmoïde est principalement utilisée car elle effectue sa tâche avec une grande efficacité, il s’agit essentiellement d’une approche probabiliste de la prise de décision et se situe entre 0 et 1, donc lorsque nous devons prendre une décision ou prédire une sortie, nous utilisons cette fonction d’activation car la plage est le minimum, par conséquent, la prédiction serait plus précise.
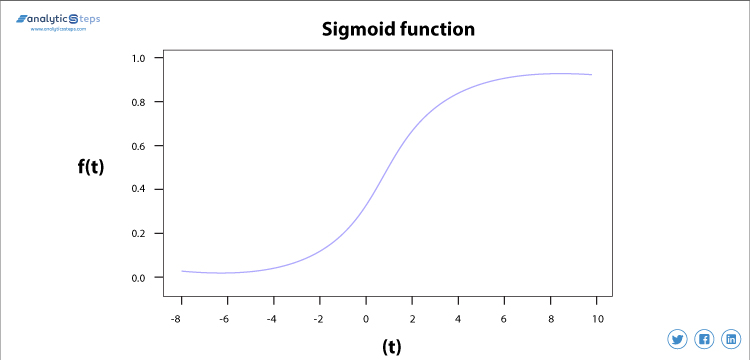
Fonction d’activation sigmoïde
L’équation de la fonction sigmoïde est
f(x) =1/(1+e(-x))
La fonction sigmoïde provoque un problème principalement appelé problème de gradient de fuite qui se produit parce que nous convertissons de grandes entrées entre 0 et 1 et que leurs dérivées deviennent donc beaucoup plus petites, ce qui ne donne pas une sortie satisfaisante. Pour résoudre ce problème, une autre fonction d’activation telle que ReLU est utilisée lorsque nous n’avons pas de petit problème dérivé.
Fonction d’activation Tangente hyperbolique (Tanh)
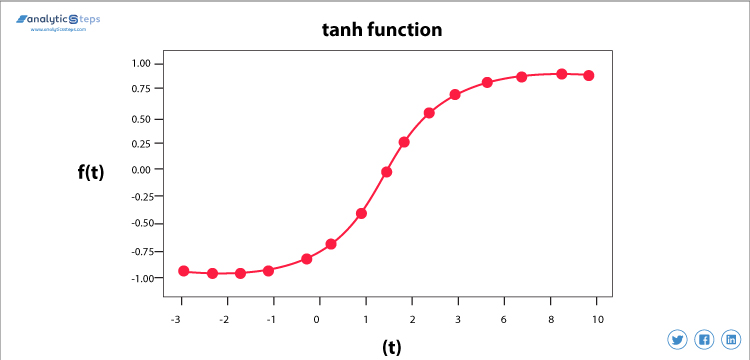
Fonction d’activation Tanh
Cette fonction d’activation est légèrement meilleure que la fonction sigmoïde, comme la fonction sigmoïde, elle est également utilisée pour prédire ou différencier deux classes, mais elle mappe l’entrée négative en quantité négative uniquement et se situe entre -1 et 1.
Fonction d’activation Softmax
Softmax est utilisé principalement au niveau de la dernière couche i.e couche de sortie pour la prise de décision la même que l’activation sigmoïde fonctionne, le softmax donne essentiellement une valeur à la variable d’entrée en fonction de leur poids et la somme de ces poids est finalement un.
Softmax sur la classification binaire
Pour la classification binaire, les deux sigmoïdes, ainsi que softmax, sont également accessibles, mais en cas de problème de classification multi-classes, nous utilisons généralement softmax et l’entropie croisée avec elle.
Conclusion
Les fonctions d’activation sont les fonctions significatives qui effectuent une transformation non linéaire de l’entrée et la rendent compétente pour comprendre et exécuter des tâches plus complexes. Nous avons discuté de 7 fonctions d’activation principalement utilisées avec leur limitation (le cas échéant), ces fonctions d’activation sont utilisées dans le même but mais dans des conditions différentes.