Qu’est-ce que l’Apprentissage par renforcement?
L’apprentissage par renforcement est défini comme une méthode d’apprentissage automatique qui concerne la façon dont les agents logiciels doivent agir dans un environnement. L’apprentissage par renforcement fait partie de la méthode d’apprentissage en profondeur qui vous aide à maximiser une partie de la récompense cumulative.
Cette méthode d’apprentissage par réseau neuronal vous aide à apprendre à atteindre un objectif complexe ou à maximiser une dimension spécifique sur de nombreuses étapes.
Dans le tutoriel d’apprentissage par renforcement, vous apprendrez:
- Qu’est-ce que l’apprentissage par renforcement?
- Termes importants utilisés dans la méthode d’apprentissage par renforcement profond
- Comment fonctionne l’apprentissage par renforcement?
- Algorithmes d’Apprentissage par Renforcement
- Caractéristiques de l’Apprentissage par Renforcement
- Types d’Apprentissage par Renforcement
- Modèles d’Apprentissage du Renforcement
- Apprentissage par Renforcement vs Apprentissage Supervisé
- Applications de l’Apprentissage par Renforcement
- Pourquoi utiliser l’Apprentissage par Renforcement?
- Quand ne pas Utiliser l’Apprentissage par renforcement?
- Défis de l’Apprentissage par renforcement
Termes importants utilisés dans la méthode d’apprentissage par renforcement profond
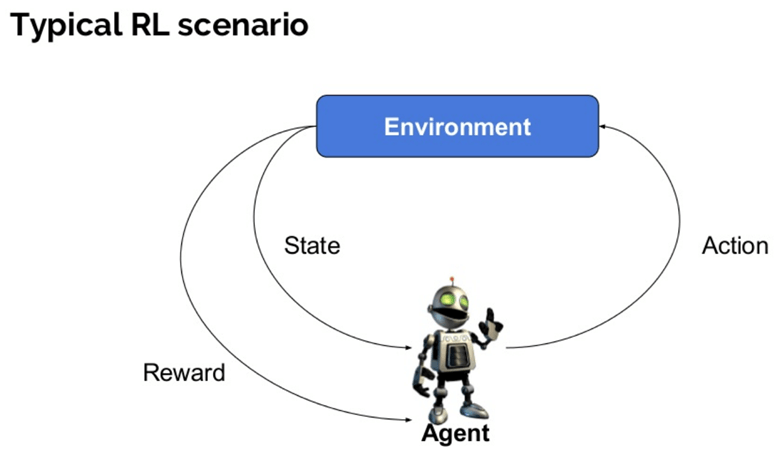
Voici quelques termes importants utilisés dans l’IA de renforcement:
- Agent: C’est une entité supposée qui effectue des actions dans un environnement pour obtenir une récompense.
- Environnement(e) : Un scénario auquel un agent doit faire face.
- Récompense (R): Un retour immédiat donné à un agent lorsqu’il effectue une action ou une tâche spécifique.
- État(s) : État fait référence à la situation actuelle renvoyée par l’environnement.
- Politique (?) : C’est une stratégie qui s’applique par l’agent pour décider de l’action suivante en fonction de l’état actuel.
- Valeur (V): Il est prévu un rendement à long terme avec une remise, par rapport à la récompense à court terme.
- Fonction Valeur : Elle spécifie la valeur d’un état qui est le montant total de la récompense. C’est un agent qui devrait être attendu à partir de cet état.
- Modèle de l’environnement : Ceci imite le comportement de l’environnement. Cela vous aide à faire des inférences et à déterminer le comportement de l’environnement.
- Méthodes basées sur des modèles: C’est une méthode pour résoudre des problèmes d’apprentissage par renforcement qui utilisent des méthodes basées sur des modèles.
- Valeur Q ou valeur d’action (Q): La valeur Q est assez similaire à la valeur. La seule différence entre les deux est qu’il prend un paramètre supplémentaire comme action courante.
Comment fonctionne l’apprentissage par renforcement?
Voyons un exemple simple qui vous aide à illustrer le mécanisme d’apprentissage par renforcement.
Considérez le scénario d’enseigner de nouvelles astuces à votre chat
- Comme le chat ne comprend pas l’anglais ou toute autre langue humaine, nous ne pouvons pas lui dire directement quoi faire. Au lieu de cela, nous suivons une stratégie différente.
- Nous émulons une situation et le chat essaie de réagir de différentes manières. Si la réponse du chat est la manière souhaitée, nous lui donnerons du poisson.
- Maintenant, chaque fois que le chat est exposé à la même situation, le chat exécute une action similaire avec encore plus d’enthousiasme dans l’espoir d’obtenir plus de récompense (nourriture).
- C’est comme apprendre que le chat tire de « quoi faire » d’expériences positives.
- En même temps, le chat apprend également ce qu’il ne fait pas face à des expériences négatives.
Explication de l’exemple:
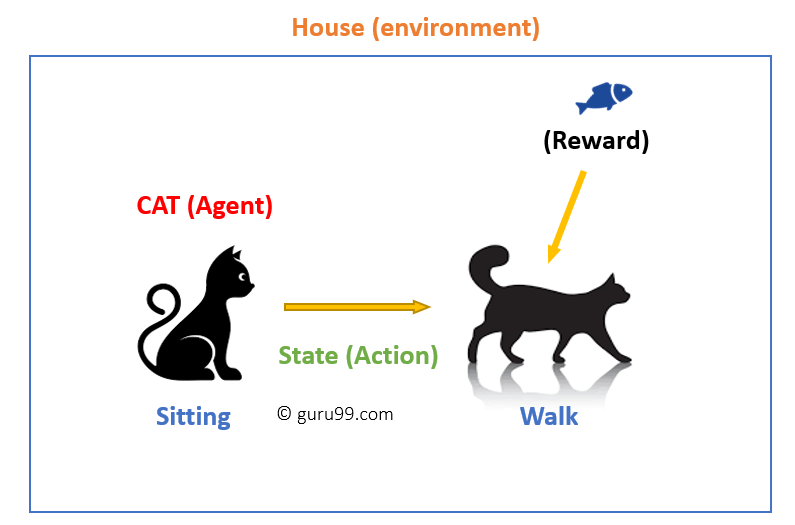
Dans ce cas,
- Votre chat est un agent exposé à l’environnement. Dans ce cas, c’est votre maison. Un exemple d’état pourrait être votre chat assis, et vous utilisez un mot spécifique pour que le chat marche.
- Notre agent réagit en effectuant une transition d’action d’un « état » à un autre « état ». »
- Par exemple, votre chat passe de la position assise à la marche.
- La réaction d’un agent est une action, et la politique est une méthode de sélection d’une action donnée à un état dans l’attente de meilleurs résultats.
- Après la transition, ils peuvent obtenir une récompense ou une pénalité en retour.
Algorithmes d’apprentissage par renforcement
Il existe trois approches pour implémenter un algorithme d’apprentissage par renforcement.
Basé sur la valeur:
Dans une méthode d’apprentissage par renforcement basé sur la valeur, vous devriez essayer de maximiser une fonction de valeur V(s). Dans cette méthode, l’agent s’attend à un retour à long terme des États actuels sous politique?.
Basé sur une stratégie :
Dans une méthode RL basée sur une stratégie, vous essayez de proposer une stratégie telle que l’action effectuée dans chaque état vous aide à obtenir une récompense maximale à l’avenir.
Deux types de méthodes basées sur une politique sont :
- Déterministe : Pour tout état, la même action est produite par la politique ?.
- Stochastique: Chaque action a une certaine probabilité, qui est déterminée par l’équation suivante.Politique stochastique :
n{a\s) = P\A, = a\S, =S]
Basée sur le modèle:
Dans cette méthode d’apprentissage par renforcement, vous devez créer un modèle virtuel pour chaque environnement. L’agent apprend à performer dans cet environnement spécifique.
Caractéristiques de l’Apprentissage par renforcement
Voici les caractéristiques importantes de l’apprentissage par renforcement
- Il n’y a pas de superviseur, seulement un signal de nombre réel ou de récompense
- Prise de décision séquentielle
- Le temps joue un rôle crucial dans les problèmes de renforcement
- Le retour est toujours retardé, pas instantané
- Les actions de l’agent déterminent les données suivantes qu’il reçoit
Types d’apprentissage par renforcement
Deux types de méthodes d’apprentissage par renforcement sont :
Positif:
Il est défini comme un événement, qui se produit en raison d’un comportement spécifique. Il augmente la force et la fréquence du comportement et a un impact positif sur l’action prise par l’agent.
Ce type de renforcement vous aide à maximiser les performances et à soutenir le changement pendant une période plus longue. Cependant, trop de renforcement peut conduire à une sur-optimisation de l’état, ce qui peut affecter les résultats.
Négatif:
Le renforcement négatif est défini comme le renforcement du comportement qui se produit en raison d’une condition négative qui aurait dû s’arrêter ou être évitée. Il vous aide à définir le niveau de performance minimum. Cependant, l’inconvénient de cette méthode est qu’elle fournit suffisamment pour respecter le comportement minimum.
Modèles d’apprentissage du renforcement
Il existe deux modèles d’apprentissage importants dans l’apprentissage par renforcement:
- Processus de décision de Markov
- Q apprentissage
Processus de décision de Markov
Les paramètres suivants sont utilisés pour obtenir une solution:
- Ensemble d’actions – Un
- Ensemble d’états-S
- Récompense-R
- Politique-n
- Valeur-V
L’approche mathématique pour cartographier une solution dans l’apprentissage par renforcement est recon en tant que processus de décision de Markov ou (MDP).
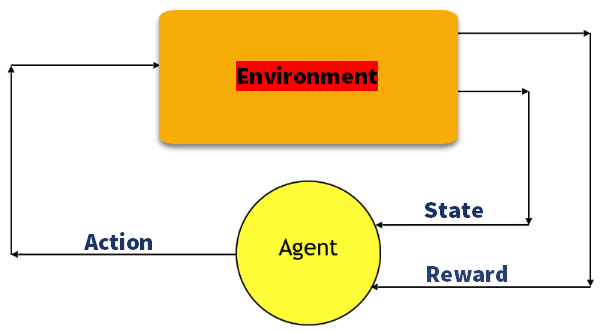
Q-Learning
Q l’apprentissage est une méthode basée sur la valeur pour fournir des informations pour indiquer quelle action un agent doit prendre.
Comprenons cette méthode par l’exemple suivant:
- Il y a cinq pièces dans un bâtiment qui sont reliées par des portes.
- Chaque pièce est numérotée de 0 à 4
- L’extérieur du bâtiment peut être une grande zone extérieure (5)
- Les portes numéro 1 et 4 mènent dans le bâtiment depuis la pièce 5
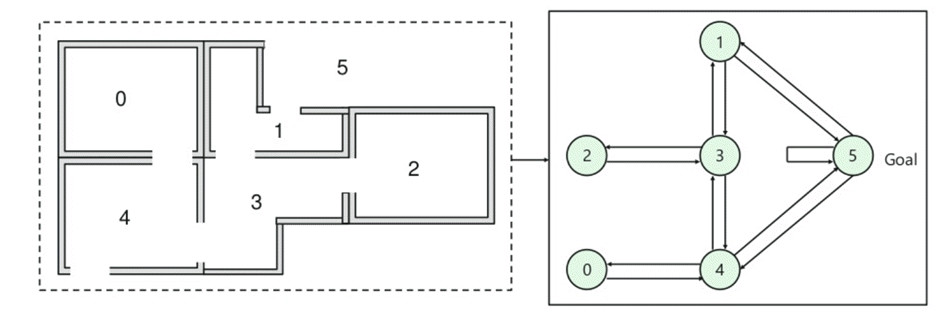
Ensuite, vous devez associer une valeur de récompense à chaque porte:
- Les portes qui mènent directement à l’objectif ont une récompense de 100
- Les portes qui ne sont pas directement connectées à la pièce cible donnent une récompense nulle
- Car les portes sont bidirectionnelles et deux flèches sont attribuées pour chaque pièce
- Chaque flèche de l’image ci-dessus contient une valeur de récompense instantanée
Explication:
Dans cette image, vous pouvez voir que la pièce représente un état
Le mouvement de l’agent d’une pièce à l’autre représente une action
Dans l’image ci-dessous, un état est décrit comme un nœud, tandis que les flèches montrent l’action.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Apprentissage supervisé
| Paramètres | Apprentissage par renforcement | Apprentissage supervisé |
| Style de décision | L’apprentissage par renforcement vous aide à prendre vos décisions de manière séquentielle. | Dans cette méthode, une décision est prise sur l’entrée donnée au début. |
| Fonctionne sur | Fonctionne sur l’interaction avec l’environnement. | Fonctionne sur des exemples ou des données d’échantillon données. |
| Dépendance à la décision | Dans la méthode RL, la décision d’apprentissage dépend. Par conséquent, vous devez donner des étiquettes à toutes les décisions dépendantes. | Apprentissage supervisé des décisions qui sont indépendantes les unes des autres, de sorte que des étiquettes sont données pour chaque décision. |
| Mieux adapté | Prend en charge et fonctionne mieux en IA, où l’interaction humaine est prédominante. | Il est principalement exploité avec un système logiciel interactif ou des applications. |
| Exemple | Jeu d’échecs | Reconnaissance d’objets |
Applications de l’Apprentissage par renforcement
Voici les applications de l’Apprentissage par renforcement:
- Robotique pour l’automatisation industrielle.
- Planification de la stratégie commerciale
- Apprentissage automatique et traitement des données
- Il vous aide à créer des systèmes de formation qui fournissent des instructions et du matériel personnalisés en fonction des besoins des étudiants.
- Contrôle d’avion et contrôle de mouvement de robot
Pourquoi utiliser l’apprentissage par renforcement?
Voici les principales raisons d’utiliser l’apprentissage par renforcement:
- Il vous aide à trouver quelle situation nécessite une action
- Vous aide à découvrir quelle action rapporte la récompense la plus élevée sur la plus longue période.
- L’apprentissage par renforcement fournit également à l’agent d’apprentissage une fonction de récompense.
- Cela lui permet également de trouver la meilleure méthode pour obtenir de grandes récompenses.
Quand ne pas utiliser l’Apprentissage par renforcement?
Vous ne pouvez pas appliquer le modèle d’apprentissage par renforcement est toute la situation. Voici quelques conditions lorsque vous ne devez pas utiliser le modèle d’apprentissage par renforcement.
- Lorsque vous avez suffisamment de données pour résoudre le problème avec une méthode d’apprentissage supervisé
- Vous devez vous rappeler que l’apprentissage par renforcement est lourd en informatique et prend beaucoup de temps. en particulier lorsque l’espace d’action est grand.
Défis de l’apprentissage par renforcement
Voici les principaux défis auxquels vous devrez faire face lorsque vous gagnerez du renforcement:
- Conception de fonctionnalités / récompenses qui devrait être très impliquée
- Les paramètres peuvent affecter la vitesse d’apprentissage.
- Les environnements réalistes peuvent avoir une observabilité partielle.
- Trop de renforcement peut entraîner une surcharge d’états qui peut diminuer les résultats.
- Les environnements réalistes peuvent être non stationnaires.
Résumé:
- L’apprentissage par renforcement est une méthode d’apprentissage automatique
- Vous aide à découvrir quelle action rapporte la récompense la plus élevée sur une période plus longue.
- Trois méthodes d’apprentissage par renforcement sont 1) Basées sur la valeur 2) Basées sur des politiques et un apprentissage basé sur des modèles.
- Agent, État, Récompense, Environnement, Modèle de fonction de valeur de l’environnement, Méthodes basées sur le modèle, sont quelques termes importants utilisés dans la méthode d’apprentissage RL
- L’exemple d’apprentissage par renforcement est que votre chat est un agent exposé à l’environnement.
- La plus grande caractéristique de cette méthode est qu’il n’y a pas de superviseur, seulement un nombre réel ou un signal de récompense
- Deux types d’apprentissage par renforcement sont 1) Positif 2) Négatif
- Deux modèles d’apprentissage largement utilisés sont 1) Processus de décision de Markov 2) Q apprentissage
- La méthode d’apprentissage par renforcement fonctionne sur l’interaction avec l’environnement, alors que la méthode d’apprentissage supervisé fonctionne sur des données d’échantillon ou un exemple donné.
- Les méthodes d’apprentissage par application ou par renforcement sont: Robotique pour l’automatisation industrielle et la planification de la stratégie d’entreprise
- Vous ne devez pas utiliser cette méthode lorsque vous avez suffisamment de données pour résoudre le problème
- Le plus grand défi de cette méthode est que les paramètres peuvent affecter la vitesse d’apprentissage