Vous ne pouvez pas facilement utiliser des variables catégorielles comme prédicteurs dans la régression linéaire: vous devez les diviser en variables dichotomiques appelées variables factices.
Le moyen idéal de créer ces variables est notre outil de variables fictives. Si vous ne souhaitez pas utiliser cet outil, ce tutoriel montre la bonne façon de le faire manuellement.
- Exemple I – Toute Variable Numérique
- Exemple II – Variable Numérique avec des Entiers Adjacents
- Exemple III – Variable de Chaîne avec Conversion
- Exemple IV – Variable de Chaîne sans Conversion
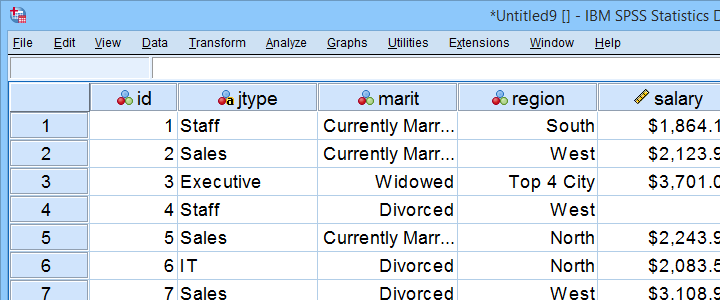
Fichier de données d’Exemple
Ce tutoriel utilise la portée.sav partout. Une partie de ce fichier de données est présentée ci-dessous.
Exemple I – Toute variable numérique
Créons d’abord des variables fictives pour marit, abréviation de l’état matrimonial. Notre première étape consiste à exécuter une table de fréquences de base avecfréquences marit.Le tableau ci-dessous montre le tableau résultant.
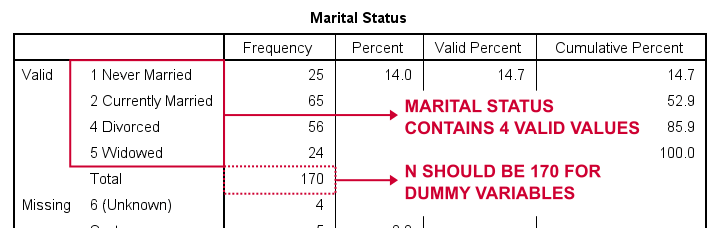
Alors, comment diviser l’état matrimonial en variables fictives? Tout d’abord, nous omettons toujours une catégorie, la catégorie de référence. Vous pouvez choisir n’importe quelle catégorie comme catégorie de référence.
Donc pour cet exemple, nous choisissons 5 (Veuf). Cela implique que nous allons créer 3 variables fictives représentant les catégories 1, 2 et 4 (notez que 3 ne se produit pas dans cette variable).
La syntaxe ci-dessous montre comment créer et étiqueter nos 3 variables fictives. Allons-y.
calculez marit_1=(marit=1).
calculez marit_2=(marit=2).
calculez marit_4=(marit=4).
* Appliquer des étiquettes de variables aux variables fictives.
étiquettes variables
marit_1 ‘État Matrimonial = Jamais marié’
marit_2’État Matrimonial = Actuellement marié’
marit_4 ‘État Matrimonial = Divorcé’.
* Vérification rapide de la première variable factice
fréquences marit_1.
Résultats
Tout d’abord, notez que nous avons créé 3 variables fictives bien étiquetées dans notre jeu de données actif.
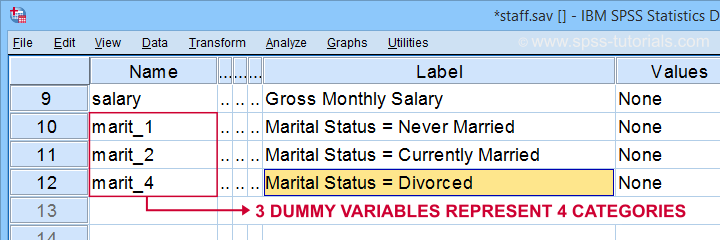
Le tableau ci-dessous montre la distribution de fréquence de notre première variable fictive.

Notez que notre variable fictive contient 3 valeurs distinctes :
- les répondants dont l’état matrimonial n’est pas « jamais marié” obtiennent le score 0;
- les répondants dont l’état matrimonial n’est pas « jamais marié” obtiennent le score 1;
- les répondants dont l’état matrimonial est une valeur manquante (et donc inconnue) ont une valeur manquante du système.
Nous pouvons maintenant vérifier les résultats de manière plus approfondie en exécutant les robots marit de marit_1 à marit_4.Cela crée 3 tableaux de contingence, dont le premier est illustré ci-dessous.
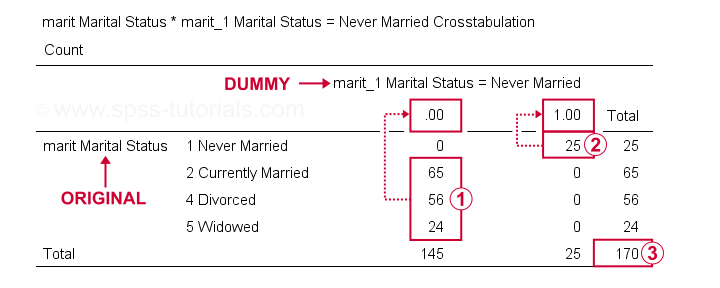
Sur notre variable fictive,  les répondants ayant un autre statut matrimonial que « jamais mariés » obtiennent tous un score 0;
les répondants ayant un autre statut matrimonial que « jamais mariés » obtiennent tous un score 0;  les répondants qui « ne se sont jamais mariés » obtiennent tous un score 1;
les répondants qui « ne se sont jamais mariés » obtiennent tous un score 1; nous avons une taille d’échantillon de N = 170 (ce tableau n’inclut que les répondants sans valeurs manquantes sur l’une ou l’autre variable).
nous avons une taille d’échantillon de N = 170 (ce tableau n’inclut que les répondants sans valeurs manquantes sur l’une ou l’autre variable).
En option, une vérification finale – très approfondie – consiste à comparer les résultats d’ANOVA pour la variable d’origine aux résultats de régression en utilisant nos variables fictives. La syntaxe ci-dessous fait exactement cela, en utilisant le salaire mensuel comme variable dépendante.
régression
/ salaire dépendant
/ méthode entrez marit_1 à marit_4.
* ANOVA minimale en utilisant la variable d’origine.
salaire unique par marit.
Notez que les deux analyses donnent lieu à des tables d’ANOVA identiques. Nous discuterons plus en détail de la régression des variables ANOVA par rapport aux variables fictives dans un futur tutoriel.
Exemple II – Variable numérique avec des entiers adjacents
Nous allons maintenant créer des variables fictives pour la région. Encore une fois, nous commençons par inspecter une table de fréquences minimales que nous créerons en exécutant une région de fréquences.Cela se traduit dans le tableau ci-dessous.
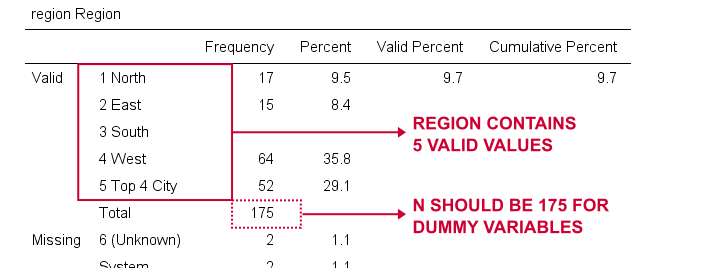
Nous choisirons 1 (« Nord”) comme catégorie de référence. Nous allons donc créer des variables fictives pour les catégories 2 à 5. Puisque ce sont des entiers adjacents, nous pouvons accélérer les choses en utilisant DO REPEAT comme indiqué ci-dessous.
répétez #vals = 2 à 5 / #vars=région_2 à région_5.
recodez la région (#vals = 1) (lo à hi = 0) dans #vars.
fin de l’impression répétée.
* Appliquez des étiquettes de variables aux nouvelles variables.
étiquettes variables
region_2’Region=Est’
region_3′ Region=Sud’
region_4′ Region=Ouest’
region_5’Region=Top 4 Ville’.
* Vérification rapide.
crosstabs région par région_2 à région_5.
Une inspection minutieuse des tableaux obtenus confirme que tous les résultats sont corrects.
Exemple III – Variable de chaîne avec conversion
Malheureusement, nos 2 premières méthodes ne fonctionnent pas pour les variables de chaîne telles que jtype – abréviation de « type de travail”). La solution la plus simple consiste à le convertir en une variable numérique, comme indiqué dans SPSS Convert String en variable numérique. La syntaxe ci-dessous utilise le CODE AUTOMATIQUE pour effectuer le travail.
code automatique jtype
/ dans njtype.
* Vérifier le résultat.
fréquences njtype.
* Définissez les valeurs manquantes.
valeurs manquantes njtype(1,2).
* Revérifier le résultat.
fréquences njtype.
Result

Puisque njtype – abréviation de « numeric job type » – est une variable numérique, nous pouvons maintenant utiliser la méthode I ou la méthode II pour la décomposer en variables fictives.
Exemple de variable de chaîne IV sans conversion
La conversion de variables de chaîne en variables numériques est facile à créer pour elles. Sans cette conversion, le processus est fastidieux car SPSS ne gère pas correctement les valeurs manquantes pour les variables de chaîne. Cependant, la syntaxe ci-dessous fait le travail correctement.
fréquences jtype.
* Chance ‘(Inconnue)’ dans ‘NA’.
recode jtype(‘(Inconnu)’ = ‘NA’).
* Définissez les valeurs manquantes de l’utilisateur.
valeurs manquantes jtype(« , ‘NA’).
* Réinspecter les fréquences.
fréquences jtype.
* Créer des variables fictives pour la variable de chaîne.
si (pas manquant(jtype)) jtype_1 =(jtype= ‘IT’).
si (pas manquant(jtype)) jtype_2 =(jtype=’Gestion’).
si (pas manquant(jtype)) jtype_3 =(jtype=’Ventes’).
si (pas manquant(jtype)) jtype_4 =(jtype=’Portée’).
* Appliquer des étiquettes de variables aux variables fictives.
étiquettes variables
jtype_1 ‘Type de travail = IT’
jtype_2’Type de travail= Gestion’
jtype_3’Type de travail = Ventes’
jtype_4’Type de travail= Personnel’.
* Vérifier les résultats.
crosstabs jtype par jtype_1 à jtype_4.
Notes finales
La création de variables fictives pour les variables numériques peut être effectuée rapidement et facilement. Définir des étiquettes de variables appropriées demande cependant toujours un peu de travail. Les variables de chaîne nécessitent quelques étapes supplémentaires mais sont également assez réalisables.
Néanmoins, l’option la plus simple est notre outil SPSS Create Dummy Variables car il prend parfaitement soin de tout.