VMware High Availability (HA) est un utilitaire qui élimine le besoin de matériel et de logiciels de secours dédiés dans un environnement virtualisé. VMware HA est souvent utilisé pour améliorer la fiabilité, réduire les temps d’arrêt dans les environnements virtuels et améliorer la reprise après sinistre/la continuité des activités.
Ce chapitre extrait de l’examen VCP4 Cram: VMware Certified Professional, 2e édition par Elias Khnaser explore les meilleures pratiques de VMware HA.
VMware High Availability traite principalement de la défaillance de l’hôte ESX/ESXi et de ce qui arrive aux machines virtuelles (VM) qui s’exécutent sur cet hôte. HA peut également surveiller et redémarrer une machine virtuelle en vérifiant si les outils VMware sont toujours en cours d’exécution. Lorsqu’un hôte ESX/ESXi échoue pour une raison quelconque, toutes les machines virtuelles en cours d’exécution échouent également. VMware HA garantit que les machines virtuelles de l’hôte défaillant peuvent être redémarrées sur d’autres hôtes ESX/ESXi.
De nombreuses personnes confondent à tort VMware HA avec la tolérance aux pannes. VMware HA n’est pas tolérant aux pannes en ce sens que si un hôte tombe en panne, les machines virtuelles qui s’y trouvent échouent également. HA s’occupe uniquement du redémarrage de ces machines virtuelles sur d’autres hôtes ESX / ESXi disposant de suffisamment de ressources. La tolérance aux pannes, d’autre part, fournit un accès sans interruption aux ressources en cas de panne de l’hôte.
 Cliquez sur l’image de couverture du livre ci-dessus
Cliquez sur l’image de couverture du livre ci-dessus pour télécharger le chapitre entier d’Elias Khnaser
sur la sauvegarde et la haute disponibilité.
VMware HA maintient un canal de communication avec tous les autres hôtes ESX/ESXi membres du même cluster en utilisant un battement de cœur qu’il envoie toutes les 1 seconde dans vSphere 4.0 ou toutes les 10 secondes dans vSphere 4.1 par défaut. Lorsqu’un serveur ESX manque un battement de cœur, les autres hôtes attendent 15 secondes que l’autre hôte réponde à nouveau. Après 15 secondes, le cluster lance le redémarrage des machines virtuelles sur l’hôte ESX/ESXi défaillant sur les hôtes ESX/ESXi restants du cluster. VMware HA surveille également en permanence les hôtes ESX/ESXi membres du cluster et veille à ce que les ressources soient toujours disponibles pour répondre aux exigences en cas de défaillance de l’hôte.
Surveillance des pannes de machines virtuelles
La surveillance des pannes de machines virtuelles est une technologie désactivée par défaut. Sa fonction est de surveiller les machines virtuelles, qu’il interroge toutes les 20 secondes via un battement de cœur. Pour ce faire, il utilise les outils VMware installés à l’intérieur de la machine virtuelle. Lorsqu’une machine virtuelle rate un battement de cœur, VMware HA considère cette machine virtuelle comme ayant échoué et tente de la réinitialiser. Considérez la surveillance des pannes de machines virtuelles comme une sorte de Haute disponibilité pour les machines virtuelles.
La surveillance des pannes de machines virtuelles peut détecter si une machine virtuelle a été mise hors tension manuellement, suspendue ou migrée, et ne tente donc pas de la redémarrer.
prérequis de configuration de VMware HA
HA nécessite les prérequis de configuration suivants avant de pouvoir fonctionner correctement :
- vCenter : Comme VMware HA est une fonctionnalité de classe entreprise, il nécessite vCenter avant de pouvoir être activé.
- Résolution DNS : Tous les hôtes ESX/ESXi membres du cluster HA doivent pouvoir se résoudre mutuellement à l’aide du DNS.
- Accès au stockage partagé : Tous les hôtes du cluster HA doivent avoir accès et une visibilité sur le même stockage partagé ; sinon, ils n’auraient pas accès aux machines virtuelles.
- Accès au même réseau: Tous les hôtes ESX/ESXi doivent avoir les mêmes réseaux configurés sur tous les hôtes de sorte que lorsqu’une machine virtuelle est redémarrée sur n’importe quel hôte, elle a à nouveau accès au réseau correct.
Redondance de la Console de service
La pratique recommandée exige que la Console de service (SC) ait une redondance. VMware HA se plaint et émet un avertissement s’il détecte que la console de service est configurée sur un vSwitch avec un seul vmnic. Comme le montre la figure 1, vous pouvez configurer la redondance de la console de service de l’une des deux manières suivantes :
- Créez deux groupes de ports de console de service, chacun sur un commutateur virtuel différent.
- Attribuez deux cartes d’interface réseau physiques (NIC) sous la forme d’une équipe de NIC à la console de service vSwitch.
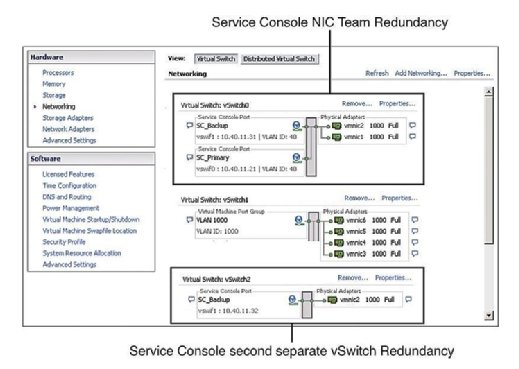
Dans les deux cas, vous devez configurer l’ensemble de la pile IP avec l’adresse IP, le sous-réseau et la passerelle. Les commutateurs virtuels de la console de service sont utilisés pour les battements cardiaques et la synchronisation des états et utilisent les ports suivants:
- Port TCP entrant 8042
- Port UDP entrant 8045
- Port TCP sortant 2050
- Port UDP sortant 2250
- Port TCP entrant 8042-8045
- Port UDP entrant 8042-8045
- Port TCP sortant 2050-2250
- Port UDP sortant 2050-2250
L’échec de la configuration de la redondance SC entraîne un message d’avertissement lorsque vous activez HA. Ainsi, pour éviter de voir ce message d’erreur et respecter les meilleures pratiques, configurez le SC pour qu’il soit redondant.
Planification de la capacité de basculement de l’hôte
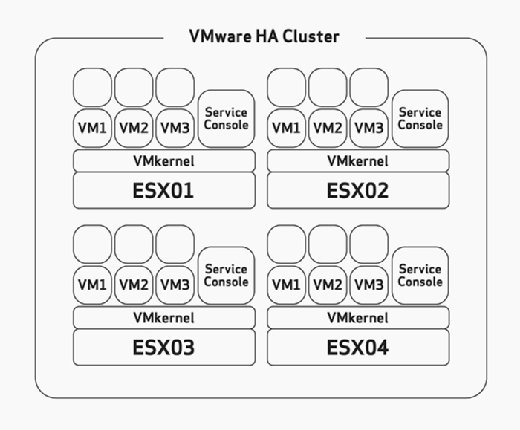
Lors de la configuration de HA, vous devez configurer manuellement la tolérance maximale de défaillance de l’hôte. Il s’agit d’une tâche que vous devez prendre en compte pendant la phase de dimensionnement et de planification du matériel de votre déploiement. Cela supposerait que vous avez construit vos hôtes ESX / ESXi avec suffisamment de ressources pour exécuter plus de machines virtuelles que prévu pour pouvoir accueillir HA. Par exemple, dans la figure 2, notez que le cluster HA a quatre hôtes ESX et que ces quatre hôtes ont une capacité suffisante pour exécuter au moins trois machines virtuelles supplémentaires. Étant donné qu’ils exécutent tous déjà trois machines virtuelles, cela signifie que ce cluster peut se permettre la perte de deux hôtes ESX/ESXi car les deux hôtes ESX/ESXi restants peuvent allumer les six machines virtuelles défaillantes sans problème en cas d’échec.
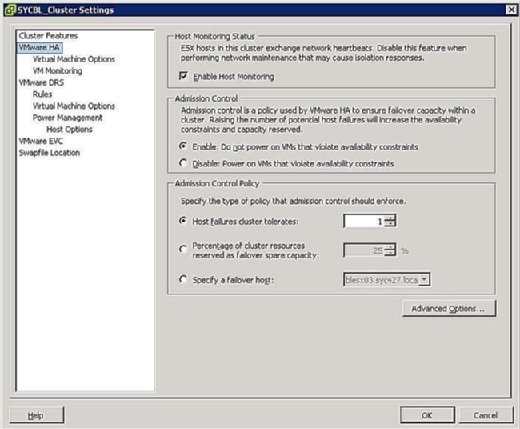
Pendant la phase de configuration du cluster HA, un écran similaire à celui de la figure 3 vous invite à définir deux configurations à l’échelle du cluster comme suit:
- État de la surveillance de l’hôte :
- Activer la surveillance de l’hôte : Ce paramètre vous permet de contrôler si le cluster HA doit surveiller les hôtes pendant un battement de cœur. C’est la façon dont le cluster détermine si un hôte est toujours actif. Dans certains cas, lorsque vous exécutez des tâches de maintenance sur des hôtes ESX/ESXi, il peut être souhaitable de désactiver cette option pour éviter d’isoler un hôte.
- Contrôle d’admission :
- Enable : Ne mettez pas sous tension les machines virtuelles qui violent les contraintes de disponibilité: La sélection de cette option indique que si aucune ressource n’est disponible pour satisfaire une machine virtuelle, elle ne doit pas être mise sous tension.
- Désactiver : Mettre sous tension les machines virtuelles qui ne respectent pas les contraintes de disponibilité : La sélection de cette option indique que vous devez mettre sous tension une machine virtuelle même si vous devez surcharger les ressources.
- Stratégie de contrôle d’admission :
- Le cluster tolère les défaillances de l’hôte : Ce paramètre vous permet de configurer le nombre de défaillances de l’hôte que vous souhaitez tolérer. Les paramètres autorisés sont de 1 à 4.
- Pourcentage de ressources de cluster réservées en tant que capacité de réserve de basculement: La sélection de cette option indique que vous réservez un pourcentage du total des ressources de cluster disponibles pour le basculement. Dans un cluster à quatre hôtes, une réservation de 25 % indique que vous mettez de côté un hôte complet pour le basculement. Si vous souhaitez en réserver moins, vous pouvez choisir 10 % des ressources du cluster à la place.
- Spécifiez un hôte de basculement : La sélection de cette option indique que vous sélectionnez un hôte particulier comme hôte de basculement dans le cluster. Cela peut être le cas si vous avez un hôte de rechange ou un hôte particulier qui dispose de beaucoup plus de ressources de calcul et de mémoire disponibles.
Isolation de l’hôte
Un phénomène de réseau connu sous le nom de cerveau divisé se produit lorsque l’hôte ESX/ESXi a cessé de recevoir un battement de cœur du reste du cluster. Le rythme cardiaque est interrogé toutes les secondes dans vSphere 4.0 ou 10 secondes dans vSphere 4.1. Si aucune réponse n’est reçue, le cluster pense que l’hôte ESX/ESXi a échoué. Lorsque cela se produit, l’hôte ESX/ESXi a perdu sa connectivité réseau sur son interface de gestion. L’hôte peut toujours être opérationnel et les machines virtuelles peuvent même ne pas être affectées, car elles peuvent utiliser une interface réseau différente qui n’a pas été affectée. Cependant, vSphere doit prendre des mesures lorsque cela se produit car il estime qu’un hôte a échoué. D’ailleurs, la réponse d’isolement de l’hôte a été créée. La réponse d’isolement de l’hôte est la façon dont HA traite un hôte ESX /ESXi qui a perdu sa connexion réseau.
Vous pouvez contrôler ce qui arrive aux machines virtuelles en cas d’isolement de l’hôte. Pour accéder à l’écran de réponse à l’isolement de la machine virtuelle, cliquez avec le bouton droit sur le cluster en question et cliquez sur Modifier les paramètres. Vous pouvez ensuite cliquer sur Options de la machine virtuelle sous la bannière VMware HA dans le volet de gauche. Vous pouvez contrôler les options à l’échelle du cluster en définissant l’option de réponse d’isolement de l’hôte en conséquence. Ceci est appliqué à toutes les machines virtuelles de l’hôte affecté. Cela étant dit, vous pouvez toujours remplacer les paramètres du cluster en définissant une réponse différente au niveau de la machine virtuelle.
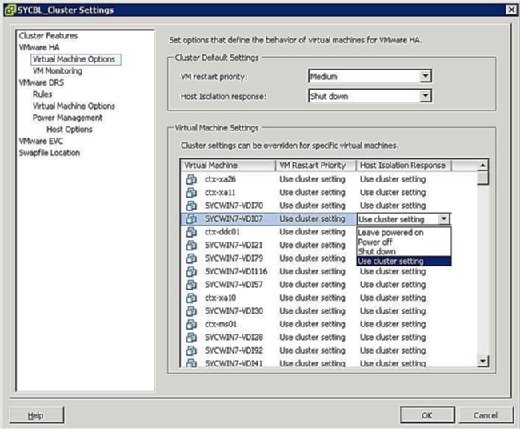
Comme le montre la figure 4, vos options de réponse d’isolement sont les suivantes :
- Laisser sous tension : Comme l’étiquette l’indique, ce paramètre signifie qu’en cas d’isolement de l’hôte, la machine virtuelle reste sous tension.
- Mise hors tension : Ce paramètre définit qu’en cas d’isolement, la machine virtuelle est mise hors tension. C’est une mise hors tension difficile.
- Arrêt : Ce paramètre définit qu’en cas d’isolement, la machine virtuelle est arrêtée gracieusement à l’aide de VMware Tools. Si cette tâche n’est pas terminée avec succès dans les cinq minutes, une mise hors tension est immédiatement exécutée. Si VMware Tools n’est pas installé, une mise hors tension est exécutée à la place.
- Utiliser le paramètre Cluster : Ce paramètre transfère la tâche au paramètre à l’échelle du cluster défini dans la fenêtre illustrée précédemment à la figure 4.
En cas d’isolement, cela ne signifie pas nécessairement que l’hôte est en panne. Étant donné que les machines virtuelles peuvent être configurées avec différentes cartes réseau physiques et connectées à différents réseaux, elles peuvent continuer à fonctionner correctement ; vous devez donc en tenir compte lors de la définition de la priorité d’isolement. Lorsqu’un hôte est isolé, cela signifie simplement que sa console de service ne peut pas communiquer avec le reste des hôtes ESX/ESXi du cluster.
Priorité de récupération de la machine virtuelle
Si votre cluster HA ne peut pas accueillir toutes les machines virtuelles en cas de panne, vous avez la possibilité de hiérarchiser les machines virtuelles. Les priorités dictent quelles machines virtuelles sont redémarrées en premier et quelles machines virtuelles ne sont pas si importantes en cas d’urgence. Ces options sont configurées sur le même écran que la réponse d’isolement couverte dans la section précédente. Vous pouvez configurer des paramètres à l’échelle du cluster qui seront appliqués à toutes les machines virtuelles de l’hôte affecté, ou vous pouvez remplacer les paramètres du cluster en configurant un remplacement au niveau de la machine virtuelle.
Vous pouvez définir la priorité de redémarrage d’une machine virtuelle sur l’une des options suivantes :
- High : les machines virtuelles ayant une priorité élevée sont redémarrées en premier.
- Medium : C’est le paramètre par défaut.
- Faible : Les machines virtuelles avec une priorité faible sont redémarrées en dernier.
- Utiliser le paramètre Cluster : Les machines virtuelles sont redémarrées en fonction du paramètre défini au niveau du cluster défini dans la fenêtre illustrée dans la figure ci-dessous.
- Désactivé : La machine virtuelle ne s’allume pas.
La priorité doit être définie en fonction de l’importance des machines virtuelles. En d’autres termes, vous voudrez peut-être redémarrer les contrôleurs de domaine et ne pas redémarrer les serveurs d’impression. Les machines virtuelles de priorité supérieure sont redémarrées en premier. Les machines virtuelles qui peuvent tolérer de rester hors tension en cas d’urgence doivent être configurées pour rester hors tension afin de conserver les ressources.
Clustering MSCS
L’objectif principal d’un cluster est de s’assurer que les systèmes critiques restent en ligne à tout prix et à tout moment. Comme pour les machines physiques pouvant être mises en cluster, les machines virtuelles peuvent également être mises en cluster avec ESX en utilisant trois scénarios différents :
- Cluster-in-a-box : Dans ce scénario, toutes les machines virtuelles faisant partie du cluster résident sur le même hôte ESX/ESXi. Comme vous l’avez peut-être deviné, cela crée immédiatement un seul point de défaillance : l’hôte ESX / ESXi. En ce qui concerne le stockage partagé, vous pouvez utiliser des disques virtuels comme stockage partagé dans ce scénario, ou vous pouvez utiliser le mappage de périphérique brut (RDM) en mode de compatibilité virtuelle.
- Cluster-across-boxes : Dans ce scénario, les nœuds de cluster (machines virtuelles membres du cluster) résident sur plusieurs hôtes ESX/ESXi, chacun des nœuds composant le cluster pouvant accéder au même stockage de sorte que si une machine virtuelle échoue, l’autre peut continuer à fonctionner et accéder aux mêmes données. Ce scénario crée un environnement de cluster idéal en éliminant un seul point de défaillance. Le stockage partagé est une condition préalable à cet égard et doit résider sur le SAN Fibre Channel. Vous devez également utiliser un RDM en mode de compatibilité physique ou virtuelle car les disques virtuels ne sont pas une configuration prise en charge pour le stockage partagé. Chacun des nœuds qui composent le cluster peut accéder au même stockage de sorte qu’en cas de défaillance d’une machine virtuelle, l’autre peut continuer à fonctionner et accéder aux mêmes données.
- Cluster physique à virtuel: Dans ce scénario, un membre du cluster est une machine virtuelle, tandis que l’autre membre est une machine physique. Le stockage partagé est une condition préalable dans ce scénario et doit être configuré en tant que RDM en mode de compatibilité physique.
Chaque fois que vous concevez une solution de clustering, vous devez résoudre le problème du stockage partagé, qui permettrait à plusieurs hôtes ou machines virtuelles d’accéder aux mêmes données. vSphere propose plusieurs méthodes permettant de provisionner le stockage partagé comme suit :
- Disques virtuels: Vous ne pouvez utiliser un disque virtuel comme zone de stockage partagée que si vous effectuez un clustering dans une boîte, c’est-à-dire uniquement si les deux machines virtuelles résident sur le même hôte ESX/ESXi.
- RDM en mode de compatibilité physique : Ce mode vous permet d’attacher un LUN physique directement dans une machine virtuelle ou une machine physique. Ce mode vous empêche d’utiliser des fonctionnalités telles que les instantanés et est idéalement utilisé lorsqu’un membre du cluster est une machine physique tandis que l’autre est une machine virtuelle.
- RDM en mode de compatibilité virtuelle : Ce mode vous permet d’attacher un LUN physique directement dans une machine virtuelle ou une machine physique. Ce mode vous offre tous les avantages des disques virtuels exécutés sur VMFS, y compris les instantanés et le verrouillage avancé des fichiers. Le disque est accessible via l’hyperviseur et est idéal lors de la configuration d’un scénario de cluster-across-box dans lequel vous devez donner aux deux machines virtuelles un accès au stockage partagé.
Au moment de la rédaction de cet article, le seul service de clustering pris en charge par VMware est Microsoft Clustering Services (MSCS). Vous pouvez consulter le livre blanc VMware » Configuration du cluster de basculement et du service de cluster Microsoft. »
Tolérance aux pannes VMware
La tolérance aux pannes VMware (FT) est une autre forme de clustering de machines virtuelles développée par VMware pour les systèmes nécessitant une disponibilité extrême. L’une des caractéristiques les plus convaincantes de FT est sa facilité d’installation. FT est simplement une case à cocher qui peut être activée. Comparé au clustering traditionnel qui nécessite des configurations spécifiques et, dans certains cas, un câblage, FT est simple mais puissant.
Comment ça marche ?
Lors de la protection des machines virtuelles avec FT, une machine virtuelle secondaire est créée au pas de la machine virtuelle protégée, la première machine virtuelle. FT fonctionne en écrivant simultanément sur la première machine virtuelle et la deuxième machine virtuelle en même temps. Chaque tâche est écrite deux fois. Si vous cliquez sur le menu Démarrer de la première machine virtuelle, le menu Démarrer de la deuxième machine virtuelle sera également cliqué. La puissance de FT est sa capacité à garder les deux machines virtuelles synchronisées.
Si la machine virtuelle protégée doit tomber en panne pour une raison quelconque, la machine virtuelle secondaire prend immédiatement sa place, saisissant son identité et son adresse IP, continuant à servir les utilisateurs sans interruption. La machine virtuelle protégée nouvellement promue crée ensuite un secondaire pour elle-même sur un autre hôte et le cycle redémarre.
Pour clarifier, voyons un exemple. Si vous souhaitez protéger un serveur Exchange, vous pouvez activer FT. Si, pour une raison quelconque, l’hôte ESX/ESXi qui transporte la machine virtuelle protégée tombe en panne, la machine virtuelle secondaire entre en fonction et assume ses fonctions sans interruption de service.
Le tableau ci-dessous décrit les différentes technologies de haute disponibilité et de clustering auxquelles vous avez accès avec vSphere et met en évidence les limites de chacune.

Exigences de tolérance aux pannes
La tolérance aux pannes n’est pas différente de toute autre fonctionnalité d’entreprise en ce sens qu’elle nécessite certaines conditions préalables avant que la technologie puisse fonctionner correctement et efficacement. Ces exigences sont décrites dans la liste suivante et ventilées en différentes catégories nécessitant des exigences minimales spécifiques :
- Exigences de l’hôte :
- CPU compatible FT. Consultez cet article de VMware KB pour plus d’informations.
- La virtualisation matérielle doit être activée dans le bios.
- Les vitesses d’horloge CPU de l’hôte doivent être à moins de 400 MHz l’une de l’autre.
- Exigences de la machine virtuelle :
- Les machines virtuelles doivent résider sur le stockage partagé pris en charge (FC, iSCSI et NFS).
- Les machines virtuelles doivent exécuter un système d’exploitation pris en charge.
- Les machines virtuelles doivent être stockées dans un VMDK ou un RDM virtuel.
- Les machines virtuelles ne peuvent pas avoir un VMDK provisionné de manière mince et doivent utiliser un disque virtuel Eagerzeroedthick.
- Les machines virtuelles ne peuvent pas avoir plus d’une vCPU configurée.
- Exigences du cluster:
- Tous les hôtes ESX/ESXi doivent avoir la même version et le même niveau de correctif.
- Tous les hôtes ESX/ESXi doivent avoir accès aux banques de données et aux réseaux des machines virtuelles.
- VMware HA doit être activé sur le cluster.
- Chaque hôte doit avoir une carte réseau de journalisation vMotion et FT configurée.
- La vérification des certificats d’hôte doit également être activée.
Il est fortement conseillé, en plus de vérifier la compatibilité du processeur avec FT, de vérifier la compatibilité de la marque et du modèle de votre serveur avec FT par rapport à la liste de compatibilité matérielle VMware (HCL).
Bien que FT soit une excellente solution de clustering, il est important de noter qu’elle présente également certaines limites. Par exemple, les machines virtuelles FT ne peuvent pas être snapshotées et elles ne peuvent pas être stockées vMotioned. En fait, ces machines virtuelles seront automatiquement marquées DRS-désactivées et ne participeront à aucun équilibrage de charge dynamique des ressources.
Comment activer FT
L’activation de FT n’est pas difficile, mais elle implique la configuration de quelques paramètres différents. Les paramètres suivants doivent être correctement configurés pour que FT fonctionne :
- Activer la vérification du certificat d’hôte: Pour activer ce paramètre, connectez-vous à votre serveur vCenter et cliquez sur Administration dans le menu Fichier, puis sur Paramètres de vCenter Server. Dans le volet de gauche, cliquez sur Paramètres SSL et cochez la case vCenter nécessite des certificats SSL d’hôte vérifiés.
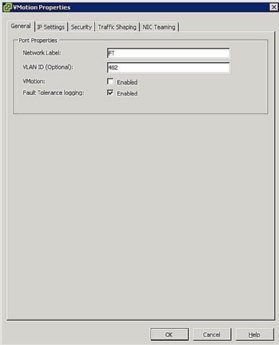
Figure 5. Configuration du groupe de ports FT - Configurer la mise en réseau de l’hôte: La configuration réseau pour FT est simple et suit les mêmes étapes et procédures que vMotion, sauf qu’au lieu de cocher la case vMotion, cochez la case de journalisation de la tolérance aux pannes comme illustré à la figure 5.
- Activer et désactiver FT : Une fois que vous avez satisfait aux exigences précédentes, vous pouvez maintenant activer et désactiver FT pour les machines virtuelles. Ce processus est également simple : Recherchez la machine virtuelle que vous souhaitez protéger, cliquez dessus avec le bouton droit de la souris et sélectionnez Tolérance aux pannes > Activez la tolérance aux pannes.
Bien que FT soit une technologie de clustering de première génération, elle fonctionne de manière impressionnante et simplifie les méthodes traditionnelles trop compliquées de construction, de configuration et de maintenance des clusters. FT est une technologie impressionnante pour un point de vue de disponibilité et d’un point de vue de basculement transparent.