Informations sur la version : Le code de cette page a été testé dans Stata 12.
La régression de poisson est utilisée pour modéliser les variables de comptage.
Remarque: Le but de cette page est de montrer comment utiliser différentes commandes d’analyse de données. Il ne couvre pas tous les aspects du processus de recherche que les chercheurs sont censés effectuer. En particulier, il ne couvre pas le nettoyage et la vérification des données, la vérification des hypothèses, les diagnostics de modèles ou les analyses de suivi potentielles.
Exemples de régression de Poisson
Exemple 1. Le nombre de personnes tuées par des coups de pied de mulet ou de cheval dans l’armée prussienne par an.Ladislaus Bortkiewicz a collecté des données à partir de 20 volumes dePreussischen Statistik. Ces données ont été collectées sur 10 corps de l’armée prussienne à la fin des années 1800 au cours des années 20.
Exemple 2. Le nombre de personnes qui font la queue devant vous à l’épicerie. Les prédicteurs peuvent inclure le nombre d’articles actuellement offerts à un prix réduit spécial et le fait qu’un événement spécial (p. ex., un jour férié, un grand événement sportif) dure trois jours ou moins.
Exemple 3. Le nombre de récompenses obtenues par les étudiants d’une école secondaire. Les prédicteurs du nombre de bourses obtenues comprennent le type de programme auquel l’étudiant était inscrit (p. ex., professionnel, général ou académique) et la note à son examen final en mathématiques.
Description des données
A titre d’illustration, nous avons simulé un jeu de données pour l’exemple 3 ci-dessus. Dans cet exemple, num_awards est la variable de résultat et indique le nombre de récompenses obtenues par les élèves d’une école secondaire au cours d’une année, math est une variable prédictive continue et représente les scores des élèves à leur examen final de mathématiques, et prog est une variable prédictive catégorielle avec trois niveaux indiquant le type de programme auquel les étudiants étaient inscrits.
Commençons par charger les données et regarder quelques statistiques descriptives.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
Chaque variable a 200 observations valides et leurs distributions semblent tout à fait raisonnables. En particulier, la moyenne inconditionnelle et la variance de notre variable de résultat ne sont pas extrêmement différentes.
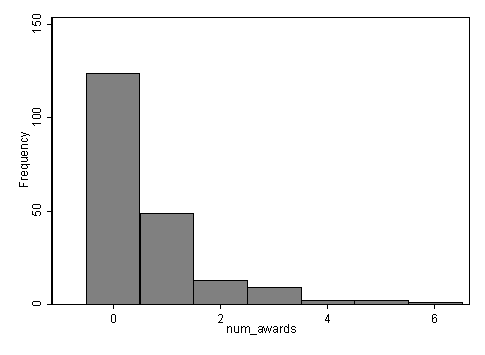
Continuons avec notre description des variables de cet ensemble de données. Le tableau ci-dessous montre le nombre moyen de bourses par type de programme et semble suggérer que le type de programme est un bon candidat pour prédire le nombre de bourses, notre variable de résultat, car la valeur moyenne du résultat semble varier selon le prog.
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
Méthodes d’analyse que vous pourriez envisager
Voici une liste de certaines méthodes d’analyse que vous avez peut-être rencontrées. Certaines des méthodes énumérées sont tout à fait raisonnables, tandis que d’autres sont tombées en disgrâce ou ont des limites.
- Régression de poisson – La régression de poisson est souvent utilisée pour modéliser les données de comptage. La régression de poisson a un certain nombre d’extensions utiles pour les modèles de comptage.
- Régression binomiale négative – La régression binomiale négative peut être utilisée pour les données de comptage sur-dispersées, c’est-à-dire lorsque la variance conditionnelle dépasse la moyenne conditionnelle. Elle peut être considérée comme une généralisation de la régression de Poisson car elle a la même structure moyenne que la régression de Poisson et elle a un paramètre supplémentaire pour modéliser la sur-dispersion. Si la distribution conditionnelle de la variable de résultat est sur-dispersée, les intervalles de confiance pour la régression binomiale négative seront probablement plus étroits que ceux d’une régression de Poisson.
- Modèle de régression gonflé à zéro – Les modèles gonflés à zéro tentent de tenir compte des zéros excédentaires. En d’autres termes, on pense que deux types de zéros existent dans les données, les « vrais zéros » et les « zéros en excès ». Les modèles gonflés à zéro estiment deux équations simultanément, l’une pour le modèle de comptage et l’autre pour les zéros en excès.
- Régression OLS – Les variables de résultat du comptage sont parfois transformées en log et analysées à l’aide de la régression OLS. De nombreux problèmes se posent avec cette approche, notamment la perte de données due à des valeurs non définies générées par la prise du journal de zéro (qui n’est pas défini) et des estimations biaisées.
Régression de poisson
Ci-dessous, nous utilisons la commande poisson pour estimer un modèle de régression de poisson. Le prog i.before indique qu’il s’agit d’une variable factorielle (i.e., variable catégorielle), et qu’elle devrait être incluse dans le modèle sous la forme d’une série de variables indicatrices.
Nous utilisons l’option vce (robuste) pour obtenir des erreurs-types robustes pour les estimations des paramètres, comme recommandé par Cameron et Trivedi (2009), afin de contrôler la violation légère des hypothèses sous-jacentes.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
Le test du chi carré à deux degrés de liberté indique que prog, pris ensemble, est un prédicteur statistiquement significatif des récompenses numériques.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
Pour aider à évaluer l’ajustement du modèle, la commande estat gof peut être utilisée pour obtenir le test du chi carré de la qualité de l’ajustement. Ce n’est pas un test des coefficients du modèle (que nous avons vu dans les informations d’en-tête), mais un test de la forme du modèle: La forme du modèle de poisson correspond-elle à nos données?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
Nous concluons que le modèle convient raisonnablement bien car le test du chi carré n’est pas statistiquement significatif. Si le test avait été statistiquement significatif, cela indiquerait que les données ne correspondent pas bien au modèle. Dans cette situation, nous pouvons essayer de déterminer s’il y a des variables prédictives omises, si notre hypothèse de linéarité est valable et / ou s’il y a un problème de sur-dispersion.
Parfois, nous pourrions vouloir présenter les résultats de régression sous forme de rapports de taux d’incident, nous pouvons utiliser leur option r. Ces valeurs IRR sont égales à nos coefficients de la sortie ci-dessus exponentiée.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
La sortie ci-dessus indique que le taux d’incident pour 2.prog est 2,96 fois le taux d’incident pour le groupe de référence (1.prog). De même, le taux d’incident pour 3.prog est 1,45 fois le taux d’incident pour le groupe de référence en maintenant les autres variables constantes. La variation en pourcentage du taux d’incidents des récompenses numériques est une augmentation de 7% pour chaque augmentation d’unité en mathématiques.
Rappelez la forme de notre équation de modèle:
log(num_awards)= Intercept +b1(prog=2) +b2(prog=3) +b3math.
Cela implique:
num_awards = exp(Intercept+b1(prog=2) +b2(prog=3) +b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3) )*exp(b3math)
Les coefficients ont un effet additif dans l’échelle log(y) et les TRI ont un effet multiplicatif dans l’échelle y.
Pour plus d’informations sur les différentes métriques dans lesquelles les résultats peuvent être présentés, et l’interprétation de ceux-ci, veuillez consulter Modèles de régression pour les variables dépendantes catégorielles Utilisant Stata, Deuxième édition de J. Scott Long et Jeremy Freese (2006).
Pour mieux comprendre le modèle, nous pouvons utiliser la commande margins. Ci-dessous, nous utilisons la commande margins pour calculer les nombres prédits à chaque niveau de prog, en maintenant toutes les autres variables (dans cet exemple, mathématiques) dans le modèle à leurs valeurs moyennes.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
Dans la sortie ci-dessus, nous voyons que le nombre d’événements prédit pour le niveau 1 de prog est d’environ.21, tenant les mathématiques à sa moyenne. Le nombre prévu d’événements pour le niveau 2 de prog est plus élevé à.62, et le nombre prévu d’événements pour le niveau 3 de prog est d’environ.31. Notez que le nombre prédit de niveau 2 de prog est (.6249446/.211411) = 2,96 fois plus élevé que le nombre prévu pour le niveau 1 de prog. Cela correspond à ce que nous avons vu dans la table de sortie IRR.
Ci-dessous, nous obtiendrons les nombres prédits pour des valeurs mathématiques allant de 35 à 75 par incréments de 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
Le tableau ci-dessus montre qu’avec prog à ses valeurs observées et les mathématiques maintenues à 35 pour toutes les observations, le nombre moyen prédit (ou le nombre moyen de récompenses) est d’environ.13; lorsque math = 75, le nombre moyen prédit est d’environ 2,17. Si nous comparons les nombres prédits à math = 35 et math = 45, nous pouvons voir que le rapport est (.2644714/.1311326) = 2.017. Cela correspond au TRI de 1,0727 pour un changement de 10 unités : 1,0727 ^ 10 = 2,017.
La commande fitstat écrite par l’utilisateur (ainsi que les commandes estat de Stata) peuvent être utilisées pour obtenir des informations supplémentaires qui peuvent être utiles si vous souhaitez comparer des modèles. Vous pouvez taper search fitstat pour télécharger ce programme (voir Comment puis-je utiliser la commande de recherche pour rechercher des programmes et obtenir de l’aide supplémentaire? pour plus d’informations sur l’utilisation de la recherche).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
Vous pouvez représenter graphiquement le nombre d’événements prédit avec les commandes ci-dessous. Le graphique indique que le plus de récompenses sont prévues pour ceux du programme académique (prog = 2), surtout si l’étudiant a un score élevé en mathématiques. Le plus petit nombre de bourses prévues concerne les étudiants du programme général (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
Choses à considérer
- Si une surdispersion semble être un problème, nous devrions vérifiez d’abord si notre modèle est correctement spécifié, comme les variables omises et les formes fonctionnelles. Par exemple, si nous omettons la variable prédictive progin dans l’exemple ci-dessus, notre modèle semble avoir un problème de sur-dispersion. En d’autres termes, un modèle mal spécifié pourrait présenter un symptôme comme un problème de sur-dispersion.
- En supposant que le modèle est correctement spécifié, vous voudrez peut-être vérifier la surverdispersion. Il existe plusieurs façons de le faire, y compris le test du rapport de vraisemblance du paramètre de sur-dispersion alpha en exécutant le même modèle de régression en utilisant la distribution binomiale négative (nbreg).
- Une cause fréquente de sur-dispersion est l’excès de zéros, qui à son tour sont générés par un processus de génération de données supplémentaires. Dans cette situation, un modèle gonflé à zéro doit être envisagé.
- Si le processus de génération de données ne permet aucun 0 (comme le nombre de jours passés à l’hôpital), un modèle tronqué à zéro peut être plus approprié.
- Les données de comptage ont souvent une variable d’exposition, qui indique le nombre de fois où l’événement a pu se produire. Cette variable doit être incorporée dans un modèle de Poisson avec l’utilisation de l’option exp().
- La variable de résultat dans une régression de Poisson ne peut pas avoir de nombres négatifs, et l’exposition ne peut pas avoir de 0s.
- Dans Stata, un modèle de Poisson peut être estimé via la commande glm avec le lien de journal et la famille de Poisson.
- Vous devrez utiliser la commande glm pour obtenir les résidus afin de vérifier d’autres hypothèses du modèle de Poisson (voir Cameron et Trivedi (1998) et Dupont (2002) pour plus d’informations).
- De nombreuses mesures différentes du pseudo-R-carré existent. Ils tentent tous de fournir des informations similaires à celles fournies par R au carré dans la régression OLS, même si aucun d’entre eux ne peut être interprété exactement comme R au carré dans la régression OLS est interprété. Pour une discussion sur les différents pseudo-R-carrés, voir Long et Freese (2006) ou notre page FAQ Que sont les pseudo-R-carrés?.
- La régression de poisson est estimée par estimation du maximum de vraisemblance. Cela nécessite généralement une grande taille d’échantillon.
Voir aussi
- Sortie annotée pour la commande poisson
- Stata FAQ: Comment puis-je utiliser countfit dans le choix d’un modèle de comptage?
- Manuel en ligne de Stata
- poisson
- Faq de Stata
- Comment les erreurs types et les intervalles de confiance sont-ils calculés pour les rapports incidence-taux (RIR) par poisson et nbreg ?
- Cameron, A. C. et Trivedi, P. K. (2009). Microéconométrie Utilisant Stata. Station universitaire, TX: Presse Stata.
- Cameron, A. C. et Trivedi, P. K. (1998). Analyse de régression des données de comptage. La presse de Cambridge.
- Cameron, A. C. Advances in Count Data Regression Talk for the Applied Statistics Workshop, 28 mars 2009.http://cameron.econ.ucdavis.edu/racd/count.html.
- Dupont, W. D. (2002). Modélisation Statistique pour les Chercheurs Biomédicaux: Une Introduction simple à l’Analyse de Données Complexes. La presse de Cambridge.
- Long, J.S. (1997). Modèles de régression pour les Variables Dépendantes Catégorielles et Limitées.Thousand Oaks, CA: Sage Publications.
- Long, J. S. et Freese, J. (2006). Modèles de régression pour les Variables Dépendantes Catégorielles à l’aide de Stata, Deuxième Édition. Station universitaire, TX: Presse Stata.