Bonjour et bienvenue dans un Guide Illustré de la Mémoire à Long Terme à Court Terme ( LSTM) et les Unités récurrentes fermées (GRU). Je suis Michael, et je suis ingénieur en apprentissage automatique dans l’espace des assistants vocaux IA.
Dans cet article, nous allons commencer par l’intuition derrière les LSTM et les GRU. Ensuite, je vais expliquer les mécanismes internes qui permettent aux LSTM et aux GRU de fonctionner si bien. Si vous voulez comprendre ce qui se passe sous le capot pour ces deux réseaux, alors ce post est pour vous.
Vous pouvez également regarder la version vidéo de ce post sur youtube si vous préférez.
Les réseaux de neurones récurrents souffrent de mémoire à court terme. Si une séquence est assez longue, ils auront du mal à transporter des informations des étapes temporelles antérieures vers les étapes ultérieures. Donc, si vous essayez de traiter un paragraphe de texte pour faire des prédictions, les RNN peuvent laisser de côté des informations importantes dès le début.
Pendant la propagation arrière, les réseaux de neurones récurrents souffrent du problème du gradient de disparition. Les gradients sont des valeurs utilisées pour mettre à jour les poids d’un réseau de neurones. Le problème du gradient de disparition est lorsque le gradient se rétrécit à mesure qu’il se propage dans le temps. Si une valeur de gradient devient extrêmement faible, cela ne contribue pas trop à l’apprentissage.

Ainsi, dans les réseaux de neurones récurrents, les couches qui obtiennent une petite mise à jour de gradient cessent d’apprendre. Ce sont généralement les couches antérieures. Ainsi, parce que ces couches n’apprennent pas, les RNN peuvent oublier ce qu’ils ont vu dans des séquences plus longues, ayant ainsi une mémoire à court terme. Si vous voulez en savoir plus sur la mécanique des réseaux de neurones récurrents en général, vous pouvez lire mon article précédent ici.
Les LSTM et les GRU en tant que solution
Les LSTM et les GRU ont été créés comme solution à la mémoire à court terme. Ils ont des mécanismes internes appelés portes qui peuvent réguler le flux d’informations.

Ces portes peuvent apprendre quelles données d’une séquence sont importantes à conserver ou à jeter. En faisant cela, il peut transmettre des informations pertinentes tout au long de la longue chaîne de séquences pour faire des prédictions. Presque tous les résultats de pointe basés sur des réseaux de neurones récurrents sont obtenus avec ces deux réseaux. Les LSTM et les GRU peuvent être trouvés dans la reconnaissance vocale, la synthèse vocale et la génération de texte. Vous pouvez même les utiliser pour générer des légendes pour les vidéos.
Ok, donc à la fin de cet article, vous devriez avoir une bonne compréhension des raisons pour lesquelles les LSTM et les GRU sont bons pour traiter de longues séquences. Je vais aborder cela avec des explications et des illustrations intuitives et éviter autant de mathématiques que possible.
Intuition
Ok, commençons par une expérience de pensée. Disons que vous regardez les avis en ligne pour déterminer si vous voulez acheter des céréales Life (ne me demandez pas pourquoi). Vous lirez d’abord la critique, puis déterminerez si quelqu’un pensait que c’était bon ou si c’était mauvais.

Lorsque vous lisez la critique, votre cerveau ne se souvient inconsciemment que des mots clés importants. Vous prenez des mots comme « incroyable » et « petit déjeuner parfaitement équilibré ». Vous ne vous souciez pas beaucoup de mots comme « ceci », « donné”, « tout”, « devrait », etc. Si un ami vous demande le lendemain ce que dit la critique, vous ne vous en souviendrez probablement pas mot pour mot. Vous vous souvenez peut-être des points principaux comme « va certainement acheter à nouveau”. Si vous êtes beaucoup comme moi, les autres mots disparaîtront de la mémoire.

Et c’est essentiellement ce que fait un LSTM ou un GRU. Il peut apprendre à ne conserver que des informations pertinentes pour faire des prédictions, et oublier des données non pertinentes. Dans ce cas, les mots dont vous vous êtes souvenus vous ont fait juger que c’était bon.
Revue des réseaux de neurones récurrents
Pour comprendre comment les LSTM ou les GRU y parviennent, examinons le réseau de neurones récurrent. Un RNN fonctionne comme ceci; Les premiers mots sont transformés en vecteurs lisibles par machine. Ensuite, le RNN traite la séquence des vecteurs un par un.

Pendant le traitement, il passe l’état caché précédent à l’étape suivante de la séquence. L’état caché agit comme la mémoire des réseaux de neurones. Il contient des informations sur les données précédentes que le réseau a vues auparavant.

Regardons une cellule du RNN pour voir comment vous calculeriez l’état caché. Tout d’abord, l’entrée et l’état caché précédent sont combinés pour former un vecteur. Ce vecteur contient maintenant des informations sur l’entrée actuelle et les entrées précédentes. Le vecteur passe par l’activation tanh, et la sortie est le nouvel état caché, ou la mémoire du réseau.

Activation du Tanh
L’activation du tanh est utilisée pour aider à réguler les valeurs circulant dans le réseau. La fonction tanh écrase les valeurs pour qu’elles soient toujours comprises entre -1 et 1.

Lorsque des vecteurs traversent un réseau de neurones, il subit de nombreuses transformations dues à diverses opérations mathématiques. Imaginez donc une valeur qui continue d’être multipliée par disons 3. Vous pouvez voir comment certaines valeurs peuvent exploser et devenir astronomiques, ce qui fait que d’autres valeurs semblent insignifiantes.

Une fonction tanh garantit que les valeurs restent comprises entre -1 et 1, régulant ainsi la sortie du réseau de neurones. Vous pouvez voir comment les mêmes valeurs d’en haut restent entre les limites autorisées par la fonction tanh.

Donc c’est un RNN. Il a très peu d’opérations en interne mais fonctionne plutôt bien compte tenu des bonnes circonstances (comme des séquences courtes). Les RNN utilisent beaucoup moins de ressources de calcul que ses variantes évoluées, les LSTM et les GRU.
LSTM
Un LSTM a un flux de contrôle similaire à celui d’un réseau neuronal récurrent. Il traite les données qui transmettent des informations au fur et à mesure de leur propagation. Les différences sont les opérations dans les cellules du LSTM.

Ces opérations sont utilisées pour permettre au LSTM de conserver ou d’oublier des informations. Maintenant, regarder ces opérations peut devenir un peu accablant, alors nous allons passer en revue cette étape par étape.
Concept de base
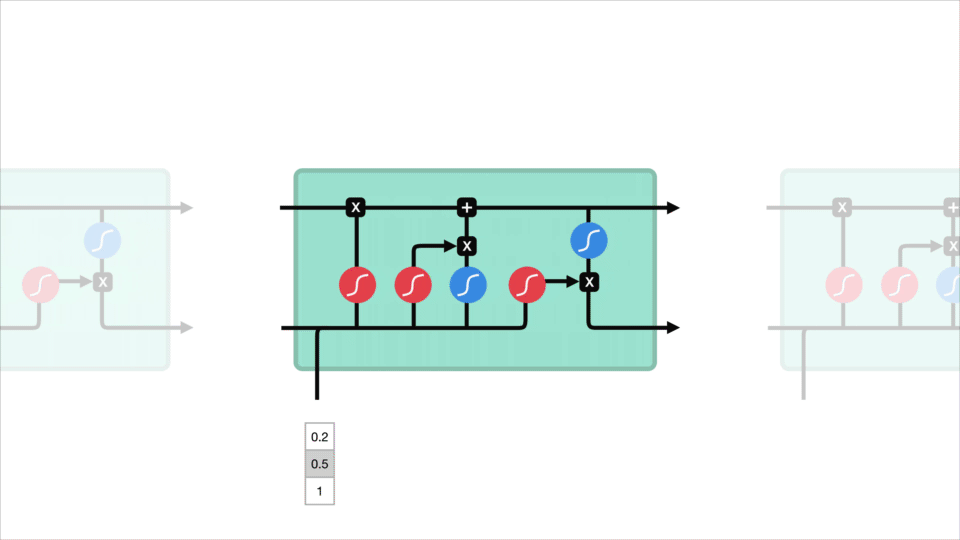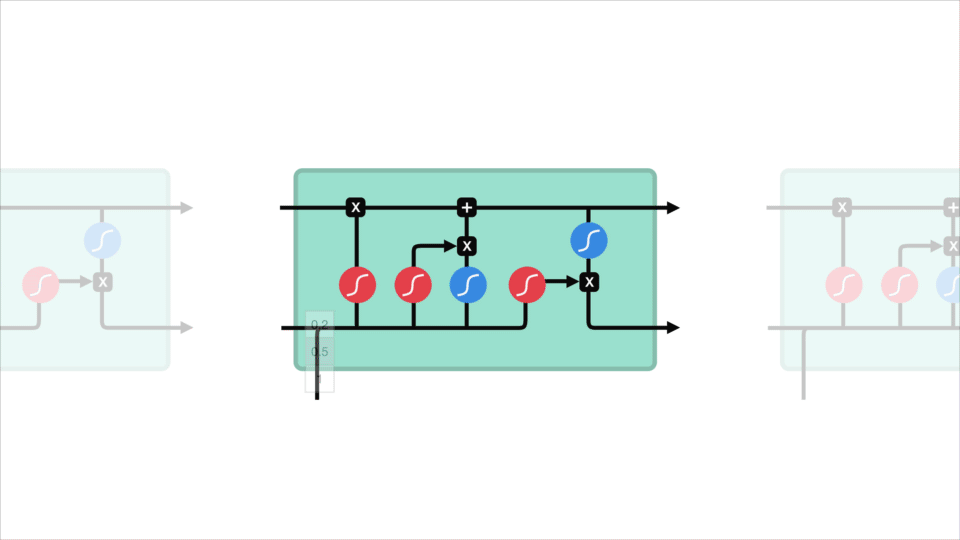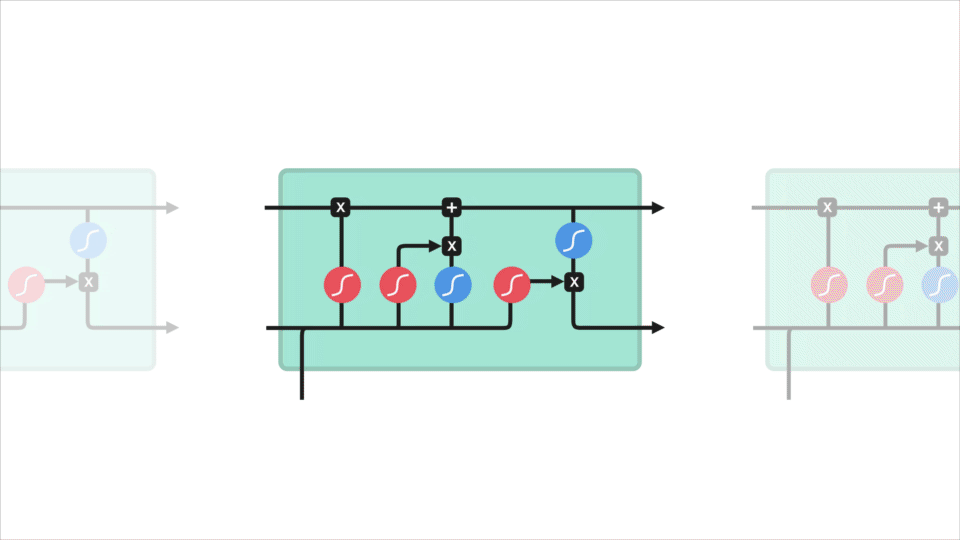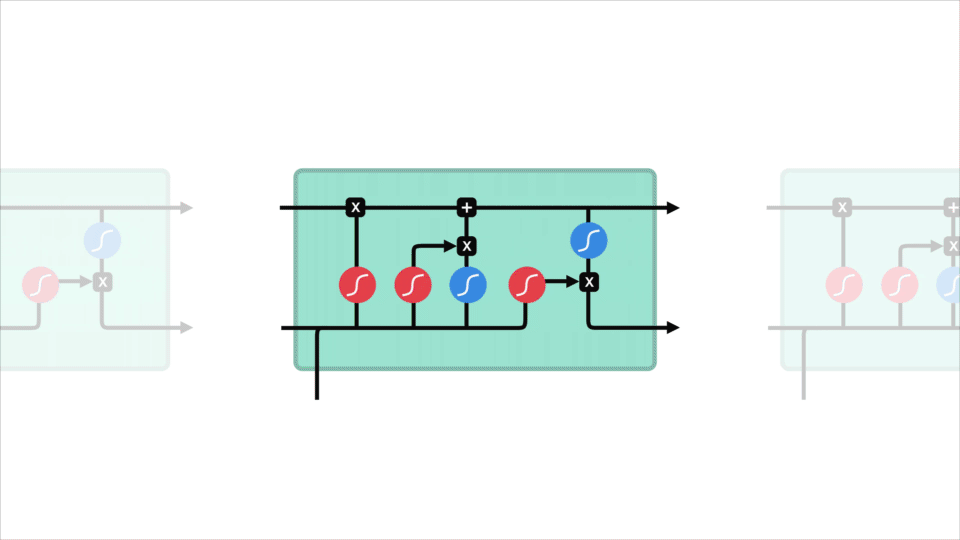
Le concept de base des LSTM sont l’état de la cellule et ses différentes portes. L’état de la cellule agit comme une autoroute de transport qui transfère des informations relatives tout au long de la chaîne de séquences. Vous pouvez le considérer comme la « mémoire » du réseau. L’état cellulaire, en théorie, peut transporter des informations pertinentes tout au long du traitement de la séquence. Ainsi, même les informations provenant des étapes temporelles antérieures peuvent se diriger vers des étapes temporelles ultérieures, réduisant ainsi les effets de la mémoire à court terme. Au fur et à mesure que l’état de la cellule se poursuit, les informations sont ajoutées ou supprimées à l’état de la cellule via des portes. Les portes sont différents réseaux de neurones qui décident des informations autorisées sur l’état de la cellule. Les portes peuvent apprendre quelles informations sont pertinentes à garder ou à oublier pendant la formation.
Les portes sigmoïdes
contiennent des activations sigmoïdes. Une activation sigmoïde est similaire à l’activation tanh. Au lieu d’écraser des valeurs comprises entre -1 et 1, il écrase des valeurs comprises entre 0 et 1. Cela est utile pour mettre à jour ou oublier les données car tout nombre multiplié par 0 est 0, ce qui fait disparaître les valeurs ou les « oublier ». »Tout nombre multiplié par 1 est la même valeur, donc cette valeur reste la même ou est « conservée.”Le réseau peut apprendre quelles données ne sont pas importantes et peuvent donc être oubliées ou quelles données sont importantes à conserver.

Creusons un peu plus profondément dans ce que font les différentes portes, n’est-ce pas? Nous avons donc trois portes différentes qui régulent le flux d’informations dans une cellule LSTM. Une porte d’oubli, une porte d’entrée et une porte de sortie.
Porte Forget
Tout d’abord, nous avons la porte forget. Cette porte décide quelles informations doivent être jetées ou conservées. Les informations de l’état caché précédent et les informations de l’entrée actuelle sont transmises par la fonction sigmoïde. Les valeurs sont comprises entre 0 et 1. Le plus proche de 0 signifie oublier, et le plus proche de 1 signifie garder.

Porte d’entrée
Pour mettre à jour l’état de la cellule, nous avons la porte d’entrée. Tout d’abord, nous passons l’état caché précédent et l’entrée actuelle dans une fonction sigmoïde. Cela décide quelles valeurs seront mises à jour en transformant les valeurs pour qu’elles soient comprises entre 0 et 1. 0 signifie pas important, et 1 signifie important. Vous passez également l’état caché et l’entrée actuelle dans la fonction tanh pour écraser les valeurs comprises entre -1 et 1 pour aider à réguler le réseau. Ensuite, vous multipliez la sortie tanh avec la sortie sigmoïde. La sortie sigmoïde décidera quelles informations sont importantes à conserver de la sortie tanh.

État de la cellule
Maintenant, nous devrions avoir suffisamment d’informations pour calculer l’état de la cellule. Tout d’abord, l’état de la cellule est multiplié par point par le vecteur d’oubli. Cela a la possibilité de supprimer des valeurs dans l’état de la cellule si elles sont multipliées par des valeurs proches de 0. Ensuite, nous prenons la sortie de la porte d’entrée et effectuons une addition ponctuelle qui met à jour l’état de la cellule à de nouvelles valeurs que le réseau de neurones trouve pertinentes. Cela nous donne notre nouvel état cellulaire.

Porte de sortie
Enfin, nous avons la porte de sortie. La porte de sortie décide quel doit être le prochain état caché. N’oubliez pas que l’état masqué contient des informations sur les entrées précédentes. L’état caché est également utilisé pour les prédictions. Tout d’abord, nous passons l’état caché précédent et l’entrée actuelle dans une fonction sigmoïde. Ensuite, nous passons l’état de cellule nouvellement modifié à la fonction tanh. Nous multiplions la sortie tanh avec la sortie sigmoïde pour décider des informations que l’état caché doit contenir. La sortie est l’état caché. Le nouvel état de cellule et le nouveau caché sont ensuite reportés à l’étape temporelle suivante.

Pour passer en revue, la porte Forget décide de ce qui est pertinent à garder des étapes précédentes. La porte d’entrée décide des informations pertinentes à ajouter à partir de l’étape en cours. La porte de sortie détermine quel doit être le prochain état caché.
Démo de code
Pour ceux d’entre vous qui comprennent mieux en voyant le code, voici un exemple utilisant le pseudo code python.

. Tout d’abord, l’état caché précédent et l’entrée actuelle sont concaténés. On l’appellera combine.
2. Combinez les entrées de get dans la couche forget. Cette couche supprime les données non pertinentes.
4. Une couche candidate est créée à l’aide de la combinaison. Le candidat contient des valeurs possibles à ajouter à l’état de la cellule.
3. Combinez également les entrées dans la couche d’entrée. Cette couche décide quelles données du candidat doivent être ajoutées au nouvel état de cellule.
5. Après avoir calculé la couche d’oubli, la couche candidate et la couche d’entrée, l’état de cellule est calculé à l’aide de ces vecteurs et de l’état de cellule précédent.
6. La sortie est ensuite calculée.
7. La multiplication ponctuelle de la sortie et du nouvel état de cellule nous donne le nouvel état caché.
C’est tout! Le flux de contrôle d’un réseau LSTM est constitué de quelques opérations tensorielles et d’une boucle for. Vous pouvez utiliser les états masqués pour les prédictions. En combinant tous ces mécanismes, un LSTM peut choisir les informations pertinentes à retenir ou à oublier pendant le traitement de la séquence.
GRU
Alors maintenant que nous savons comment fonctionne un LSTM, regardons brièvement le GRU. Le GRU est la nouvelle génération de réseaux de neurones récurrents et est assez similaire à un LSTM. GRU s’est débarrassé de l’état de la cellule et a utilisé l’état caché pour transférer des informations. Il n’a également que deux portes, une porte de réinitialisation et une porte de mise à jour.

Porte de mise à jour
La porte de mise à jour agit de la même manière que la porte d’oubli et d’entrée d’un LSTM. Il décide des informations à jeter et des nouvelles informations à ajouter.
Porte de réinitialisation
La porte de réinitialisation est une autre porte utilisée pour décider de la quantité d’informations passées à oublier.
Et c’est un GRU. GRU a moins d’opérations de tenseur; par conséquent, ils sont un peu plus rapides à entraîner que les LSTM. Il n’y a pas de gagnant clair lequel est le meilleur. Les chercheurs et les ingénieurs essaient généralement tous les deux de déterminer lequel fonctionne le mieux pour leur cas d’utilisation.
C’est donc ça
Pour résumer, les RNN sont bons pour traiter les données de séquence pour les prédictions mais souffrent de mémoire à court terme. Les LSTM et les GRU ont été créés comme une méthode pour atténuer la mémoire à court terme en utilisant des mécanismes appelés portes. Les portes ne sont que des réseaux de neurones qui régulent le flux d’informations circulant dans la chaîne séquentielle. Les LSTM et les GRU sont utilisés dans des applications d’apprentissage profond de pointe telles que la reconnaissance vocale, la synthèse vocale, la compréhension du langage naturel, etc.
Si vous souhaitez aller plus loin, voici des liens de ressources fantastiques qui peuvent vous donner une perspective différente pour comprendre les LSTM et les GRU.Cet article a été fortement inspiré par eux.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/