Dernière mise à jour le 17 février 2021
Une prédiction du point de vue de l’apprentissage automatique est un point unique qui cache l’incertitude de cette prédiction.
Les intervalles de prédiction permettent de quantifier et de communiquer l’incertitude d’une prédiction. Ils sont différents des intervalles de confiance qui cherchent plutôt à quantifier l’incertitude d’un paramètre de population tel qu’une moyenne ou un écart-type. Les intervalles de prédiction décrivent l’incertitude pour un seul résultat spécifique.
Dans ce tutoriel, vous découvrirez l’intervalle de prédiction et comment le calculer pour un modèle de régression linéaire simple.
Après avoir terminé ce tutoriel, vous saurez:
- Qu’un intervalle de prédiction quantifie l’incertitude d’une prédiction ponctuelle unique.
- Les intervalles de prédiction peuvent être estimés analytiquement pour des modèles simples, mais sont plus difficiles pour les modèles d’apprentissage automatique non linéaires.
- Comment calculer l’intervalle de prédiction pour un modèle de régression linéaire simple.
Lancez votre projet avec mon nouveau livre Statistiques pour l’apprentissage automatique, y compris des tutoriels étape par étape et les fichiers de code source Python pour tous les exemples.
Commençons.
- Mise à jour juin /2019: Niveau de signification corrigé en fraction des écarts types.
- Mise à jour avril / 2020: Correction d’une faute de frappe dans le tracé de l’intervalle de prédiction.

Intervalles de prédiction pour l’Apprentissage automatique
Photo de Jim Bendon, certains droits réservés.
Présentation du tutoriel
Ce tutoriel est divisé en 5 parties:
- Qu’Est-ce Qui Ne Va Pas Avec une Estimation Ponctuelle?
- Qu’est-ce qu’un Intervalle de Prédiction?
- Comment Calculer un Intervalle de Prédiction
- Intervalle de Prédiction pour la Régression linéaire
- Exemple travaillé
Besoin d’aide avec les statistiques pour l’Apprentissage automatique?
Suivez mon cours intensif gratuit de 7 jours par e-mail maintenant (avec un exemple de code).
Cliquez pour vous inscrire et obtenez également une version PDF Ebook gratuite du cours.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict(X)
|
Où yhat est le résultat estimé ou la prédiction faite par le modèle entraîné pour les données d’entrée données X.
Il s’agit d’une prédiction ponctuelle.
Par définition, il s’agit d’une estimation ou d’une approximation et contient une certaine incertitude.
L’incertitude provient des erreurs dans le modèle lui-même et du bruit dans les données d’entrée. Le modèle est une approximation de la relation entre les variables d’entrée et les variables de sortie.
Compte tenu du processus utilisé pour choisir et régler le modèle, ce sera la meilleure approximation faite compte tenu des informations disponibles, mais cela fera toujours des erreurs. Les données du domaine masqueront naturellement la relation sous-jacente et inconnue entre les variables d’entrée et de sortie. Cela constituera un défi pour l’ajustement du modèle, et il sera également difficile pour un modèle d’ajustement de faire des prédictions.
Compte tenu de ces deux principales sources d’erreur, leur prédiction ponctuelle à partir d’un modèle prédictif est insuffisante pour décrire l’incertitude réelle de la prédiction.
Qu’est-ce qu’un Intervalle de Prédiction?
Un intervalle de prédiction est une quantification de l’incertitude sur une prédiction.
Il fournit une limite supérieure et inférieure probabiliste sur l’estimation d’une variable de résultat.
Un intervalle de prédiction pour une seule observation future est un intervalle qui, avec un degré de confiance spécifié, contiendra une observation future sélectionnée aléatoirement à partir d’une distribution.
— Page 27, Intervalles statistiques: Un guide pour les praticiens et les chercheurs, 2017.
Les intervalles de prédiction sont les plus couramment utilisés pour faire des prédictions ou des prévisions avec un modèle de régression, où une quantité est prédite.
Un exemple de présentation d’un intervalle de prédiction est le suivant:
Étant donné une prédiction de ‘y’ donnée par ‘x’, il y a une probabilité de 95% que la plage ‘a’ à ‘b’ couvre le résultat vrai.
L’intervalle de prédiction entoure la prédiction faite par le modèle et, espérons-le, couvre la plage du résultat réel.
Le diagramme ci-dessous aide à comprendre visuellement la relation entre la prédiction, l’intervalle de prédiction et le résultat réel.
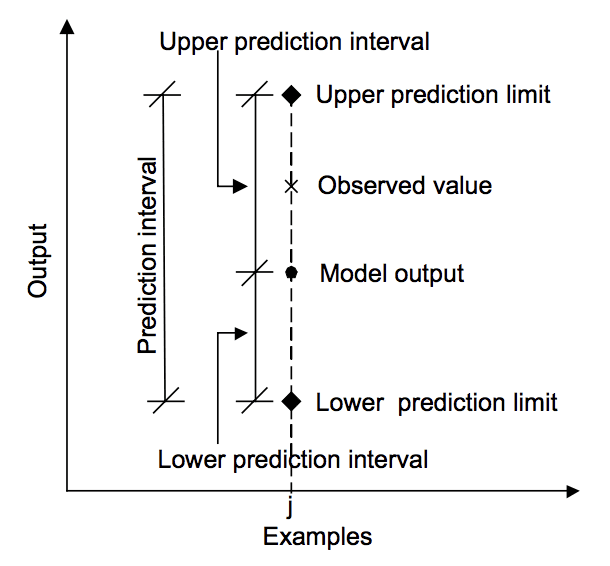
Relation entre la prédiction, la valeur réelle et l’intervalle de prédiction.
Tiré de « Machine learning approaches for estimation of prediction interval for the model output », 2006.
Un intervalle de prédiction est différent d’un intervalle de confiance.
Un intervalle de confiance quantifie l’incertitude sur une variable de population estimée, telle que la moyenne ou l’écart type. Alors qu’un intervalle de prédiction quantifie l’incertitude sur une seule observation estimée à partir de la population.
En modélisation prédictive, un intervalle de confiance peut être utilisé pour quantifier l’incertitude de la compétence estimée d’un modèle, tandis qu’un intervalle de prédiction peut être utilisé pour quantifier l’incertitude d’une prévision unique.
Un intervalle de prédiction est souvent plus grand que l’intervalle de confiance car il doit prendre en compte l’intervalle de confiance et la variance de la variable de sortie prévue.
Les intervalles de prédiction seront toujours plus larges que les intervalles de confiance car ils tiennent compte de l’incertitude associée à e, l’erreur irréductible.
— – Page 103, Une introduction à l’Apprentissage statistique: avec des applications dans R, 2013.
Comment calculer un intervalle de prédiction
Un intervalle de prédiction est calculé comme une combinaison de la variance estimée du modèle et de la variance de la variable de résultat.
Les intervalles de prédiction sont faciles à décrire, mais difficiles à calculer en pratique.
Dans des cas simples comme la régression linéaire, nous pouvons estimer directement l’intervalle de prédiction.
Dans le cas d’algorithmes de régression non linéaire, tels que les réseaux de neurones artificiels, c’est beaucoup plus difficile et nécessite le choix et la mise en œuvre de techniques spécialisées. Des techniques générales telles que la méthode de rééchantillonnage bootstrap peuvent être utilisées, mais leur calcul est coûteux.
L’article « A Comprehensive Review of Neural Network-based Prediction Intervalles and New Advances » fournit une étude raisonnablement récente des intervalles de prédiction pour les modèles non linéaires dans le contexte des réseaux de neurones. La liste suivante résume quelques méthodes qui peuvent être utilisées pour l’incertitude de prédiction pour les modèles d’apprentissage automatique non linéaires :
- La méthode Delta, du domaine de la régression non linéaire.
- La méthode bayésienne, à partir de la modélisation et des statistiques bayésiennes.
- La Méthode d’estimation de la Variance moyenne, utilisant des statistiques estimées.
- La méthode Bootstrap, utilisant le rééchantillonnage des données et développant un ensemble de modèles.
Nous pouvons rendre concret le calcul d’un intervalle de prédiction avec un exemple travaillé dans la section suivante.
Intervalle de prédiction pour la régression linéaire
Une régression linéaire est un modèle qui décrit la combinaison linéaire d’entrées pour calculer les variables de sortie.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
On ne connaît pas les vraies valeurs des coefficients b0 et b1. Nous ne connaissons pas non plus les paramètres réels de la population tels que la moyenne et l’écart type pour x ou y. Tous ces éléments doivent être estimés, ce qui introduit une incertitude dans l’utilisation du modèle afin de faire des prédictions.
Nous pouvons faire certaines hypothèses, telles que les distributions de x et y et les erreurs de prédiction faites par le modèle, appelées résidus, sont gaussiennes.
L’intervalle de prédiction autour de yhat peut être calculé comme suit:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
Nous ne savons pas dans la pratique. Nous pouvons calculer une estimation impartiale de l’écart-type prédit comme suit (tirée des approches d’apprentissage automatique pour l’estimation de l’intervalle de prédiction pour la sortie du modèle):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
Exemple travaillé
Concrétisons le cas des intervalles de prédiction de régression linéaire avec un exemple travaillé.
Tout d’abord, définissons un simple jeu de données à deux variables où la variable de sortie (y) dépend de la variable d’entrée (x) avec un bruit gaussien.
L’exemple ci-dessous définit l’ensemble de données que nous utiliserons pour cet exemple.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# générer des variables associées
à partir de l’importation numpy moyenne
à partir de l’importation numpy std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
Un tracé de l’ensemble de données est ensuite créé.
Nous pouvons voir la relation linéaire claire entre les variables avec la propagation des points mettant en évidence le bruit ou l’erreur aléatoire dans la relation.
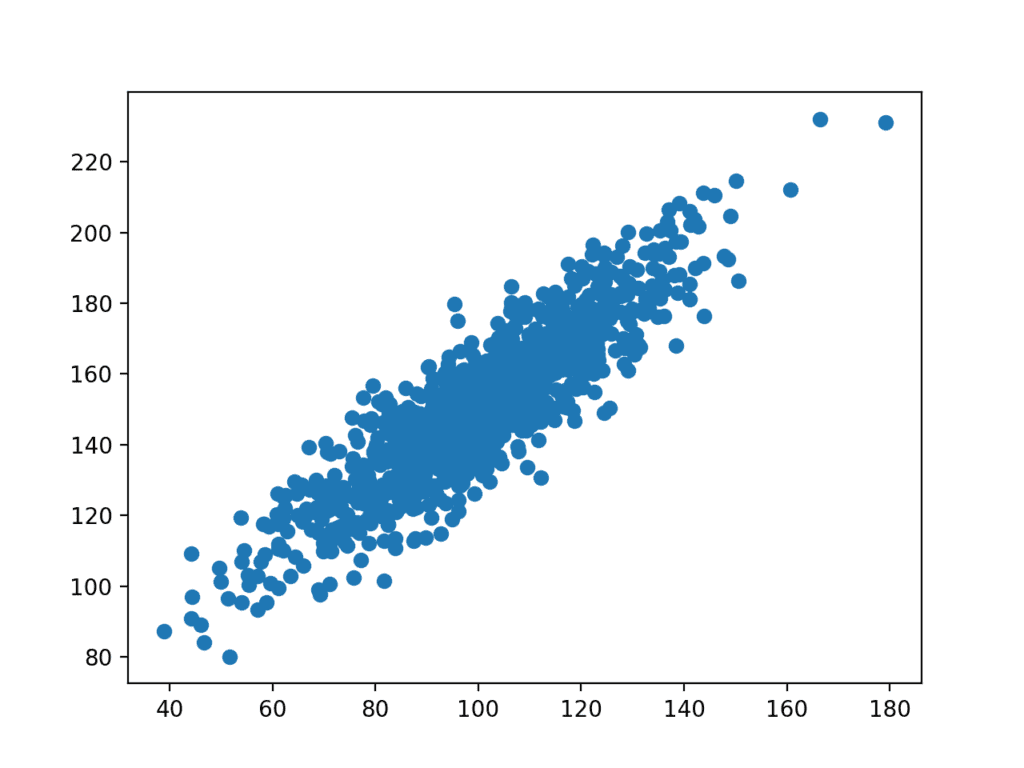
Diagramme de dispersion des Variables liées
Ensuite, nous pouvons développer une régression linéaire simple qui, compte tenu de la variable d’entrée x, permettra de prédire la variable y. Nous pouvons utiliser la fonction linregress() SciPy pour ajuster le modèle et renvoyer les coefficients b0 et b1 pour le modèle.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# modèle de régression non linéaire simple
de numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‘b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
b0=1.011, b1=49.117
|
Les coefficients sont ensuite utilisés avec les entrées de l’ensemble de données pour faire une prédiction. Les entrées résultantes et les valeurs y prédites sont tracées sous la forme d’une ligne au-dessus du nuage de points de l’ensemble de données.
Nous pouvons clairement voir que le modèle a appris la relation sous-jacente dans l’ensemble de données.
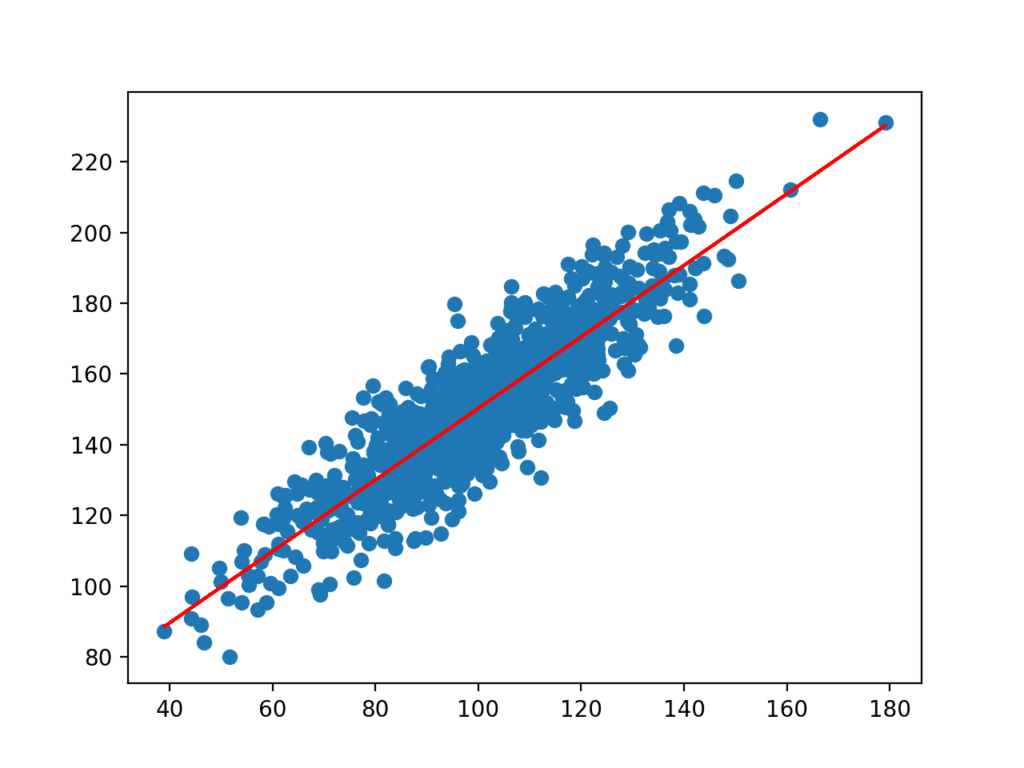
Nuage de points de l’Ensemble de Données avec Ligne pour le Modèle de Régression Linéaire Simple
Nous sommes maintenant prêts à faire une prédiction avec notre modèle de régression linéaire simple et à ajouter un intervalle de prédiction.
Nous adapterons le modèle comme avant. Cette fois, nous prendrons un échantillon de l’ensemble de données pour démontrer l’intervalle de prédiction. Nous utiliserons l’entrée pour faire une prédiction, calculer l’intervalle de prédiction pour la prédiction et comparer la prédiction et l’intervalle à la valeur attendue connue.
Tout d’abord, définissons les valeurs d’entrée, de prédiction et attendues.
|
1
2
3
|
x_in= x
y_out = y
yhat_out= yhat
|
Ensuite, nous pouvons estimer la courbure standard dans la direction de prédiction.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.stats import linregress
from matplotlib import pyplot
# générateur de nombres aléatoires de graines
seed(1)
# préparez les données
x= 20 * randn(1000) +100
y = x +(10 * randn(1000) +50)
# ajustez le modèle de régression non linéaire
b1, b0, r_value, p_value, std_err = linregress(x, y)
# marquez les prédictions
yhat =b0 +b1 *x
# définissez une nouvelle entrée, une nouvelle valeur attendue et une nouvelle prédiction
x_in = x
y_out =y
yhat_out = yhat
# estimation stdev de yhat
sum_errs = arraysum((y-yhat) **2)
stdev= sqrt(1/(len(y)-2) *sum_errs)
# calculer l’intervalle de prédiction
interval= 1.96 * stdev
print(‘Intervalle de prédiction: %.3f’% interval)
lower, upper = yhat_out-interval, yhat_out +interval
print (‘95%% de probabilité que la valeur réelle soit comprise entre %.3f et %.3f’%(inférieur, supérieur))
print(‘Valeur vraie: %.3f’%y_out)
# tracer l’ensemble de données et la prédiction avec intervalle
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’red’)
pyplot.la barre d’erreur (x_in, yhat_out, yerr = intervalle, color=’black’, fmt=’o’)
pyplot.show()
|
L’exécution de l’exemple estime l’écart type yhat, puis calcule l’intervalle de prédiction.
Une fois calculé, l’intervalle de prédiction est présenté à l’utilisateur pour la variable d’entrée donnée. Parce que nous avons inventé cet exemple, nous connaissons le vrai résultat, que nous affichons également. Nous pouvons voir que dans ce cas, l’intervalle de prédiction de 95% couvre la vraie valeur attendue.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
Un graphique est également créé montrant l’ensemble de données brutes sous forme de nuage de points, les prédictions pour l’ensemble de données sous forme de ligne rouge et la prédiction et l’intervalle de prédiction sous forme de point et de ligne noirs respectivement.
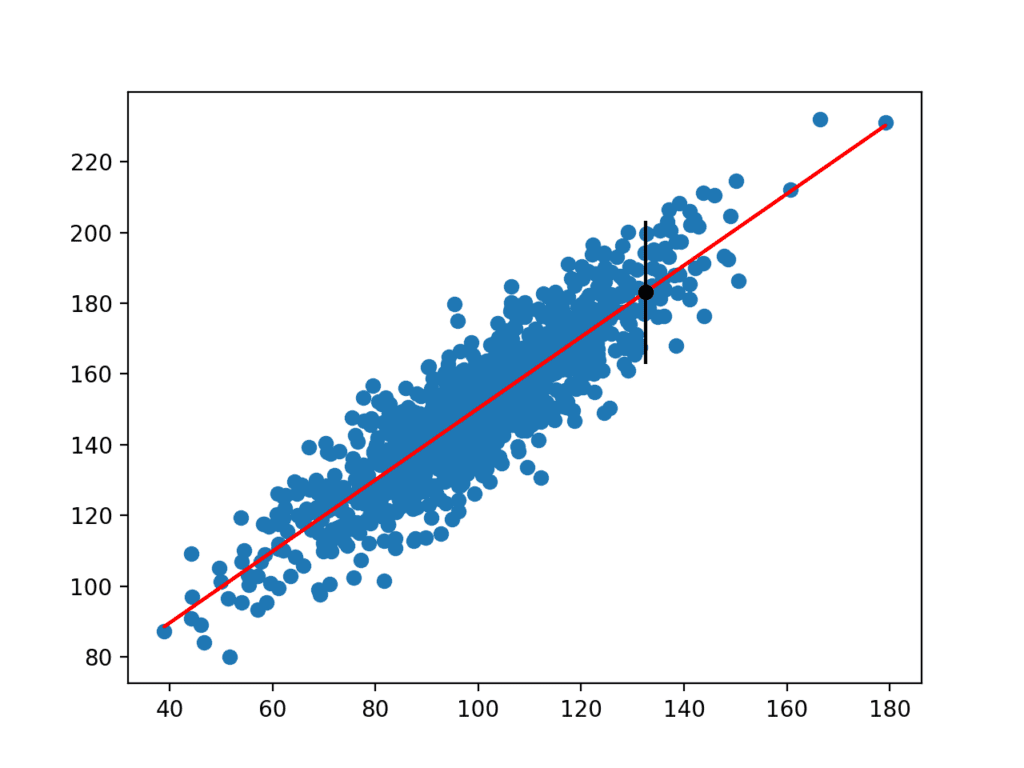
Nuage de points d’un Ensemble de Données Avec un Modèle Linéaire et un Intervalle de Prédiction
Extensions
Cette section énumère quelques idées pour étendre le tutoriel que vous voudrez peut-être explorer.
- Résumez la différence entre les intervalles de tolérance, de confiance et de prédiction.
- Développez un modèle de régression linéaire pour un ensemble de données d’apprentissage automatique standard et calculez des intervalles de prédiction pour un petit ensemble de tests.
- Décrivez en détail le fonctionnement d’une méthode d’intervalle de prédiction non linéaire.
Si vous explorez l’une de ces extensions, j’aimerais le savoir.
Pour en savoir plus
Cette section fournit plus de ressources sur le sujet si vous cherchez à aller plus loin.
Articles
- Comment Rapporter les Performances du Classificateur avec des Intervalles de Confiance
- Comment Calculer Des Intervalles de Confiance Bootstrap Pour les Résultats d’Apprentissage Automatique en Python
- Comprendre l’Incertitude des Prévisions de Séries Chronologiques En Utilisant des Intervalles de Confiance avec Python
- Estimer le Nombre de Répétitions d’Expériences pour les Algorithmes d’Apprentissage Automatique Stochastiques
Livres
- Comprendre Les Nouvelles Statistiques : Tailles d’Effets, Intervalles de Confiance et Méta-Analyse , 2017.
- Intervalles statistiques: Un guide pour les praticiens et les chercheurs, 2017.
- Une introduction à l’Apprentissage statistique: avec des applications dans R, 2013.
- Introduction aux Nouvelles statistiques: Estimation, Science Ouverte et au-delà, 2016.
- Prévisions: principes et pratiques, 2013.
Articles
- Une comparaison de certaines estimations d’erreurs pour les modèles de réseaux neuronaux, 1995.
- Approches d’apprentissage automatique pour l’estimation de l’intervalle de prédiction pour la sortie du modèle, 2006.
- A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances, 2010.
API
- scipy.statistique.linregress() API
- matplotlib.pyplot.j’ai besoin d’une API scatter()
- matplotlib.pyplot.errorbar() API
Articles
- Intervalle de prédiction sur Wikipedia
- Intervalle de prédiction Bootstrap sur Validation croisée
Résumé
Dans ce tutoriel, vous avez découvert l’intervalle de prédiction et comment le calculer pour un modèle de régression linéaire simple.
Plus précisément, vous avez appris:
- Qu’un intervalle de prédiction quantifie l’incertitude d’une prédiction ponctuelle unique.
- Les intervalles de prédiction peuvent être estimés analytiquement pour des modèles simples, mais sont plus difficiles pour les modèles d’apprentissage automatique non linéaires.
- Comment calculer l’intervalle de prédiction pour un modèle de régression linéaire simple.
Avez-vous des questions?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.
Maîtrisez les statistiques pour l’apprentissage automatique !

Développer une compréhension fonctionnelle des statistiques
…en écrivant des lignes de code en python
Découvrez comment dans mon nouvel Ebook:
Méthodes statistiques pour l’apprentissage automatique
Il fournit des tutoriels d’auto-apprentissage sur des sujets tels que:
Tests d’hypothèse, Corrélation, Statistiques non paramétriques, Rééchantillonnage, et bien plus encore…
Découvrez comment Transformer les Données en Connaissances
Ignorez les universitaires. Juste des résultats.
Voir ce qu’il y a à l’intérieur