par William W Wold
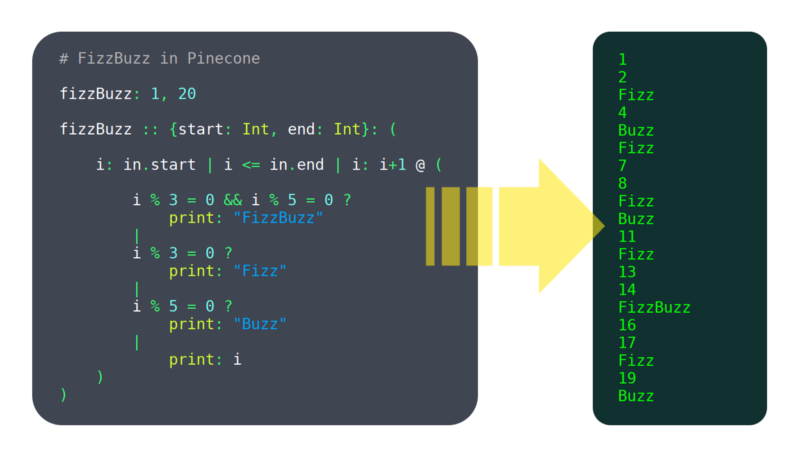
Au cours des 6 derniers mois, j’ai travaillé sur un langage de programmation appelé Pinecone. Je ne l’appellerais pas encore mature, mais il a déjà suffisamment de fonctionnalités pour être utilisable, telles que:
- variables
- fonctions
- structures définies par l’utilisateur
Si cela vous intéresse, consultez la page de destination de Pinecone ou son dépôt GitHub.
Je ne suis pas un expert. Quand j’ai commencé ce projet, je n’avais aucune idée de ce que je faisais, et je ne le fais toujours pas.J’ai suivi aucun cours sur la création de langues, j’ai lu un peu à ce sujet en ligne et je n’ai pas suivi beaucoup des conseils qui m’ont été donnés.
Et pourtant, j’ai encore fait un langage complètement nouveau. Et ça marche. Donc je dois faire quelque chose de bien.
Dans ce post, je vais plonger sous le capot et vous montrer le pipeline Pinecone (et d’autres langages de programmation) utilisé pour transformer le code source en magie.
Je vais également aborder certains des compromis que j’ai faits, et pourquoi j’ai pris les décisions que j’ai prises.
Ce n’est en aucun cas un tutoriel complet sur l’écriture d’un langage de programmation, mais c’est un bon point de départ si vous êtes curieux de développement du langage.
Mise en route
« Je n’ai absolument aucune idée d’où je commencerais” est quelque chose que j’entends beaucoup quand je dis aux autres développeurs que j’écris un langage. Dans le cas où c’est votre réaction, je vais maintenant passer en revue certaines décisions initiales qui sont prises et les étapes qui sont prises lors du démarrage d’une nouvelle langue.
Compilé vs interprété
Il existe deux principaux types de langages : compilé et interprété:
- Un compilateur calcule tout ce qu’un programme va faire, le transforme en « code machine” (un format que l’ordinateur peut exécuter très rapidement), puis l’enregistre pour l’exécuter plus tard.
- Un interpréteur parcourt le code source ligne par ligne, découvrant ce qu’il fait au fur et à mesure.
Techniquement, n’importe quelle langue peut être compilée ou interprétée, mais l’une ou l’autre a généralement plus de sens pour une langue spécifique. Généralement, l’interprétation a tendance à être plus flexible, tandis que la compilation a tendance à avoir des performances plus élevées. Mais cela ne fait que gratter la surface d’un sujet très complexe.
J’apprécie beaucoup les performances, et j’ai vu un manque de langages de programmation à la fois performants et axés sur la simplicité, alors je suis allé avec compilé pour Pinecone.
C’était une décision importante à prendre dès le début, car beaucoup de décisions de conception de langage en sont affectées (par exemple, le typage statique est un grand avantage pour les langages compilés, mais pas tellement pour ceux interprétés).
Malgré le fait que Pinecone a été conçu avec la compilation à l’esprit, il dispose d’un interpréteur entièrement fonctionnel qui était le seul moyen de l’exécuter pendant un certain temps. Il y a un certain nombre de raisons à cela, que je vous expliquerai plus tard.
Choisir une langue
Je sais que c’est un peu méta, mais un langage de programmation est lui-même un programme, et donc vous devez l’écrire dans une langue. J’ai choisi C++ en raison de ses performances et de son grand ensemble de fonctionnalités. De plus, j’aime vraiment travailler en C ++.
Si vous écrivez un langage interprété, il est très logique de l’écrire dans un langage compilé (comme C, C ++ ou Swift) car les performances perdues dans la langue de votre interprète et de l’interprète qui interprète votre interprète s’aggraveront.
Si vous prévoyez de compiler, un langage plus lent (comme Python ou JavaScript) est plus acceptable. Le temps de compilation peut être mauvais, mais à mon avis, ce n’est pas aussi grave que le mauvais temps d’exécution.
Conception de haut niveau
Un langage de programmation est généralement structuré comme un pipeline. Autrement dit, il comporte plusieurs étapes. Chaque étape a des données formatées d’une manière spécifique et bien définie. Il a également des fonctions pour transformer les données de chaque étape à la suivante.
La première étape est une chaîne contenant l’intégralité du fichier source d’entrée. La dernière étape est quelque chose qui peut être exécuté. Tout cela deviendra clair au fur et à mesure que nous traverserons le pipeline de pomme de pin étape par étape.
Lexing

La première étape dans la plupart des langages de programmation est le lexing, ou la création de jetons. « Lex » est l’abréviation de l’analyse lexicale, un mot très sophistiqué pour diviser un tas de texte en jetons. Le mot « tokenizer » a beaucoup plus de sens, mais « lexer » est tellement amusant à dire que je l’utilise quand même.
Jetons
Un jeton est une petite unité d’un langage. Un jeton peut être un nom de variable ou de fonction (ALIAS un identifiant), un opérateur ou un nombre.
Tâche du Lexer
Le lexer est censé prendre une chaîne contenant un fichier entier d’une valeur de code source et cracher une liste contenant chaque jeton.
Les étapes futures du pipeline ne renverront pas au code source d’origine, le lexer doit donc produire toutes les informations dont ils ont besoin. La raison de ce format de pipeline relativement strict est que le lexer peut effectuer des tâches telles que la suppression de commentaires ou la détection si quelque chose est un nombre ou un identifiant. Vous voulez garder cette logique verrouillée dans le lexer, à la fois pour ne pas avoir à penser à ces règles lors de l’écriture du reste de la langue, et pour pouvoir changer ce type de syntaxe en un seul endroit.
Flex
Le jour où j’ai commencé la langue, la première chose que j’ai écrite était un simple lexer. Peu de temps après, j’ai commencé à apprendre des outils qui rendraient le lexing plus simple et moins bogué.
L’outil prédominant est Flex, un programme qui génère des lexers. Vous lui donnez un fichier qui a une syntaxe spéciale pour décrire la grammaire de la langue. À partir de cela, il génère un programme C qui extrait une chaîne et produit la sortie souhaitée.
Ma décision
J’ai choisi de conserver le lexer que j’ai écrit pour le moment. En fin de compte, je n’ai pas vu d’avantages significatifs de l’utilisation de Flex, du moins pas assez pour justifier l’ajout d’une dépendance et la complexité du processus de construction.
Mon lexer ne fait que quelques centaines de lignes et me pose rarement des problèmes. Rouler mon propre lexer me donne également plus de flexibilité, comme la possibilité d’ajouter un opérateur à la langue sans modifier plusieurs fichiers.
Analyse

La deuxième étape du pipeline est l’analyseur. L’analyseur transforme une liste de jetons en un arbre de nœuds. Un arbre utilisé pour stocker ce type de données est connu sous le nom d’arbre syntaxique abstrait ou AST. Au moins dans Pinecone, l’AST n’a aucune information sur les types ou quels identifiants sont lesquels. Il s’agit simplement de jetons structurés.
Fonctions de l’analyseur
L’analyseur ajoute une structure à la liste ordonnée de jetons que le lexer produit. Pour mettre fin aux ambiguïtés, l’analyseur doit prendre en compte les parenthèses et l’ordre des opérations. L’analyse simple des opérateurs n’est pas terriblement difficile, mais à mesure que de plus en plus de constructions de langage sont ajoutées, l’analyse peut devenir très complexe.
Bison
Encore une fois, il y avait une décision à prendre impliquant une bibliothèque tierce. La bibliothèque d’analyse principale est Bison. Bison fonctionne beaucoup comme Flex. Vous écrivez un fichier dans un format personnalisé qui stocke les informations de grammaire, puis Bison l’utilise pour générer un programme C qui effectuera votre analyse. Je n’ai pas choisi d’utiliser le Bison.
Pourquoi la personnalisation Est meilleure
Avec le lexer, la décision d’utiliser mon propre code était assez évidente. Un lexer est un programme si trivial que ne pas écrire le mien était presque aussi idiot que de ne pas écrire mon propre « pavé gauche ».
Avec l’analyseur, c’est une autre affaire. Mon analyseur de pomme de pin mesure actuellement 750 lignes, et j’en ai écrit trois parce que les deux premiers étaient des déchets.
À l’origine, j’ai pris ma décision pour un certain nombre de raisons, et bien que cela ne se soit pas complètement déroulé, la plupart d’entre elles sont vraies. Les principaux sont les suivants:
- Minimiser la commutation de contexte dans le flux de travail: la commutation de contexte entre C ++ et Pinecone est assez mauvaise sans jeter dans la grammaire de Bison grammaire
- Gardez la construction simple: chaque fois que la grammaire change, Bison doit être exécuté avant la construction. Cela peut être automatisé, mais cela devient une douleur lors de la commutation entre les systèmes de construction.
- J’aime construire de la merde cool: je n’ai pas fait de pomme de pin parce que je pensais que ce serait facile, alors pourquoi déléguer un rôle central alors que je pouvais le faire moi-même? Un analyseur personnalisé n’est peut-être pas trivial, mais c’est tout à fait faisable.
Au début, je ne savais pas complètement si j’allais sur une voie viable, mais j’ai eu confiance en ce que Walter Bright (développeur d’une première version de C++ et créateur du langage D) avait à dire sur le sujet:
« Un peu plus controversé, je ne me gênerais pas pour perdre du temps avec des générateurs de lexer ou d’analyseur et d’autres soi-disant « compilateurs compilateurs. » C’est une perte de temps. L’écriture d’un lexer et d’un analyseur représente un pourcentage infime du travail d’écriture d’un compilateur. L’utilisation d’un générateur prendra à peu près autant de temps que l’écriture à la main, et cela vous mariera au générateur (ce qui compte lors du portage du compilateur sur une nouvelle plate-forme). Et les générateurs ont aussi la fâcheuse réputation d’émettre des messages d’erreur moches.”
Arbre d’action
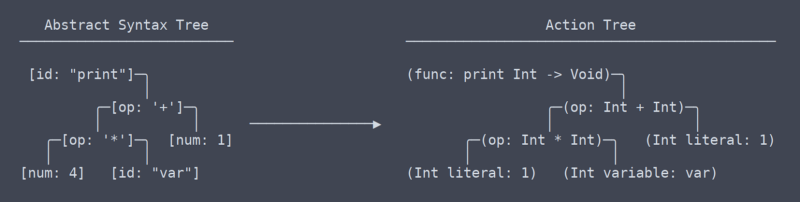
Nous avons maintenant quitté la zone des termes communs, universels, ou du moins je ne sais pas quels sont les termes plus. D’après ma compréhension, ce que j’appelle « l’arbre d’action » s’apparente le plus à l’IR de LLVM (représentation intermédiaire).
Il existe une différence subtile mais très significative entre l’arbre d’action et l’arbre de syntaxe abstraite. Il m’a fallu un certain temps pour comprendre qu’il devrait même y avoir une différence entre eux (ce qui a contribué à la nécessité de réécrire l’analyseur).
Arbre d’action vs AST
En termes simples, l’arbre d’action est l’AST avec le contexte. Ce contexte est une information telle que le type qu’une fonction renvoie ou que deux endroits dans lesquels une variable est utilisée utilisent en fait la même variable. Parce qu’il a besoin de comprendre et de se souvenir de tout ce contexte, le code qui génère l’arborescence des actions a besoin de nombreuses tables de recherche d’espaces de noms et d’autres objets.
Exécuter l’arbre d’action
Une fois que nous avons l’arbre d’action, l’exécution du code est facile. Chaque nœud d’action a une fonction ‘execute’ qui prend une entrée, fait tout ce que l’action doit faire (y compris éventuellement appeler une sous-action) et renvoie la sortie de l’action. C’est l’interprète en action.
Options de compilation
« Mais attendez! »Je vous entends dire : » la pomme de pin n’est-elle pas censée être compilée? » Oui, ça l’est. Mais la compilation est plus difficile que l’interprétation. Il y a quelques approches possibles.
Construire mon propre Compilateur
Cela m’a semblé une bonne idée au début. J’adore faire des choses moi-même, et j’avais envie d’une excuse pour être bon à l’assemblage.
Malheureusement, écrire un compilateur portable n’est pas aussi facile que d’écrire du code machine pour chaque élément de langage. En raison du nombre d’architectures et de systèmes d’exploitation, il n’est pas pratique pour un individu d’écrire un backend de compilateur multiplateforme.
Même les équipes derrière Swift, Rust et Clang ne veulent pas se soucier de tout cela seules, alors elles utilisent toutes…
LLVM
LLVM est une collection d’outils de compilation. C’est essentiellement une bibliothèque qui transformera votre langue en un binaire exécutable compilé. Cela semblait être le choix parfait, alors j’ai sauté dedans. Malheureusement, je n’ai pas vérifié la profondeur de l’eau et je me suis immédiatement noyé.
LLVM, bien que n’étant pas un langage d’assemblage dur, est une gigantesque bibliothèque complexe. Ce n’est pas impossible à utiliser, et ils ont de bons tutoriels, mais j’ai réalisé que je devrais m’entraîner avant d’être prêt à implémenter pleinement un compilateur Pinecone avec.
Transpilage
Je voulais une sorte de pomme de pin compilée et je la voulais rapide, alors je me suis tourné vers une méthode que je savais pouvoir faire fonctionner: transpiler.
J’ai écrit une pomme de pin sur un transpileur C++ et ajouté la possibilité de compiler automatiquement la source de sortie avec GCC. Cela fonctionne actuellement pour presque tous les programmes de pomme de pin (bien qu’il y ait quelques cas de bord qui le cassent). Ce n’est pas une solution particulièrement portable ou évolutive, mais cela fonctionne pour le moment.
Futur
En supposant que je continue à développer Pinecone, Il obtiendra un support de compilation LLVM tôt ou tard. Je ne soupçonne pas combien je travaille dessus, le transpileur ne sera jamais complètement stable et les avantages de LLVM sont nombreux. C’est juste une question de quand j’ai le temps de faire des exemples de projets dans LLVM et de m’en rendre compte.
Jusque-là, l’interpréteur est idéal pour les programmes triviaux et la transpilation C++ fonctionne pour la plupart des choses qui nécessitent plus de performances.
Conclusion
J’espère avoir rendu les langages de programmation un peu moins mystérieux pour vous. Si vous voulez en faire un vous-même, je le recommande fortement. Il y a une tonne de détails de mise en œuvre à comprendre, mais le plan ici devrait suffire pour vous aider à démarrer.
Voici mes conseils de haut niveau pour commencer (rappelez-vous, je ne sais pas vraiment ce que je fais, alors prenez-le avec un grain de sel):
- En cas de doute, allez interprété. Les langues interprétées sont généralement plus faciles à concevoir, à construire et à apprendre. Je ne vous décourage pas d’en écrire un compilé si vous savez que c’est ce que vous voulez faire, mais si vous êtes sur la clôture, j’irais interpréter.
- Quand il s’agit de lexers et d’analyseurs, faites ce que vous voulez. Il existe des arguments valables pour et contre l’écriture des vôtres. En fin de compte, si vous réfléchissez à votre conception et que vous mettez tout en œuvre de manière sensée, cela n’a pas vraiment d’importance.
- Apprenez du pipeline avec lequel je me suis retrouvé. Beaucoup d’essais et d’erreurs ont été effectués dans la conception du pipeline que j’ai maintenant. J’ai essayé d’éliminer les AST, les AST qui se transforment en arbres d’actions en place, et d’autres idées terribles. Ce pipeline fonctionne, alors ne le changez pas à moins d’avoir une très bonne idée.
- Si vous n’avez pas le temps ou la motivation d’implémenter un langage complexe à usage général, essayez d’implémenter un langage ésotérique tel que Brainfuck. Ces interprètes peuvent être aussi courts que quelques centaines de lignes.
J’ai très peu de regrets en ce qui concerne le développement de la pomme de pin. J’ai fait un certain nombre de mauvais choix en cours de route, mais j’ai réécrit la plupart du code affecté par de telles erreurs.
À l’heure actuelle, la pomme de pin est dans un état suffisamment bon pour qu’elle fonctionne bien et puisse être facilement améliorée. Écrire de la pomme de pin a été une expérience extrêmement éducative et agréable pour moi, et cela ne fait que commencer.