Le funzioni di attivazione sono la parte più cruciale di qualsiasi rete neurale in deep learning. Nell’apprendimento profondo, compiti molto complicati sono la classificazione delle immagini, la trasformazione del linguaggio, il rilevamento di oggetti, ecc. Quindi, senza di esso, questi compiti sono estremamente complessi da gestire.
In poche parole, una rete neurale è una tecnica molto potente nell’apprendimento automatico che imita fondamentalmente come un cervello capisce, come? Il cervello riceve gli stimoli, come input, dall’ambiente, lo elabora e quindi produce l’output di conseguenza.
Introduzione
Le funzioni di attivazione della rete neurale, in generale, sono la componente più significativa dell’apprendimento profondo, sono fondamentalmente utilizzate per determinare l’output dei modelli di apprendimento profondo, la sua accuratezza e l’efficienza delle prestazioni del modello di allenamento che può progettare o dividere una rete neurale su vasta scala.
Le funzioni di attivazione hanno lasciato notevoli effetti sulla capacità delle reti neurali di convergere e velocità di convergenza, non vuoi come? Continuiamo con un’introduzione alla funzione di attivazione, tipi di funzioni di attivazione & la loro importanza e limitazioni attraverso questo blog.
Qual è la funzione di attivazione?
Funzione di attivazione definisce l’uscita di ingresso o insieme di ingressi o in altri termini definisce nodo dell’uscita del nodo che è dato in ingressi. Fondamentalmente decidono di disattivare i neuroni o attivarli per ottenere l’output desiderato. Esegue anche una trasformazione non lineare sull’input per ottenere risultati migliori su una rete neurale complessa.
La funzione di attivazione aiuta anche a normalizzare l’output di qualsiasi input nell’intervallo compreso tra 1 e -1. La funzione di attivazione deve essere efficiente e dovrebbe ridurre il tempo di calcolo perché la rete neurale a volte si è allenata su milioni di punti dati.
La funzione di attivazione decide fondamentalmente in qualsiasi rete neurale che dato input o ricezione di informazioni è rilevante o è irrilevante. Facciamo un esempio per capire meglio cos’è un neurone e come la funzione di attivazione limiti il valore di output a un certo limite.
Il neurone è fondamentalmente una media ponderata di input, quindi questa somma viene passata attraverso una funzione di attivazione per ottenere un output.
Y = ∑ (pesi*input + bias)
Qui Y può essere qualsiasi cosa per un neurone tra intervallo-infinito a +infinito. Quindi, dobbiamo vincolare il nostro output per ottenere la previsione desiderata o risultati generalizzati.
Y = Funzione di attivazione(∑ (pesi*input + bias))
Quindi, passiamo quel neurone alla funzione di attivazione ai valori di output associati.
Perché abbiamo bisogno di funzioni di attivazione?
Senza funzione di attivazione, il peso e il bias avrebbero solo una trasformazione lineare, o la rete neurale è solo un modello di regressione lineare, un’equazione lineare è polinomiale di un solo grado che è semplice da risolvere ma limitato in termini di capacità di risolvere problemi complessi o polinomi di grado superiore.
Ma di fronte a ciò, l’aggiunta della funzione di attivazione alla rete neurale esegue la trasformazione non lineare in input e la rende in grado di risolvere problemi complessi come le traduzioni linguistiche e le classificazioni delle immagini.
In aggiunta a ciò, le funzioni di attivazione sono differenziabili grazie alle quali possono facilmente implementare back propagations, strategia ottimizzata durante l’esecuzione di backpropagations per misurare le funzioni di perdita del gradiente nelle reti neurali.
Tipi di Funzioni di Attivazione
Il più famoso funzioni di attivazione sono riportati di seguito,
-
Binario passo
-
Lineare
-
ReLU
-
LeakyReLU
-
Sigma
-
Tanh
-
Softmax
1. Funzione di attivazione passo binario
Questa funzione di attivazione molto semplice e viene in mente ogni volta se proviamo a bound output. È fondamentalmente un classificatore di base di soglia, in questo, decidiamo un valore di soglia per decidere l’output che il neurone dovrebbe essere attivato o disattivato.
f(x) = 1 if x > 0 else 0 if x < 0
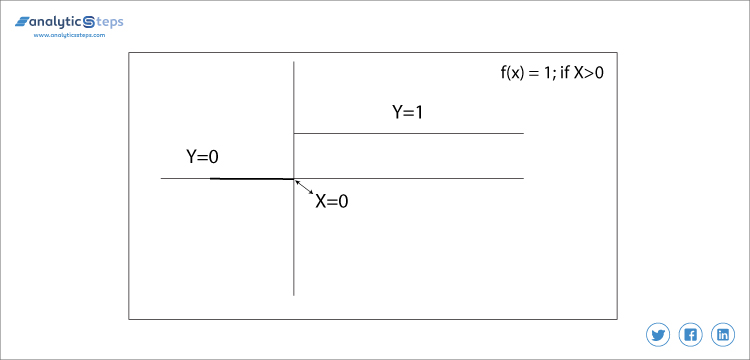
Binary step function
In questo, decidiamo il valore di soglia a 0. E ‘ molto semplice e utile per classificare i problemi binari o classificatore.
2. Funzione di attivazione lineare
È una semplice funzione di attivazione lineare in cui la nostra funzione è direttamente proporzionale alla somma ponderata di neuroni o input. Le funzioni di attivazione lineare sono migliori nel dare una vasta gamma di attivazioni e una linea di pendenza positiva può aumentare la velocità di cottura all’aumentare della velocità di ingresso.
In binario, un neurone sta sparando o no. Se conosci la discesa del gradiente nell’apprendimento profondo, noterai che in questa funzione la derivata è costante.
Y = mZ
Dove la derivata rispetto a Z è costante m. Anche il gradiente di significato è costante e non ha nulla a che fare con Z. In questo, se le modifiche apportate in backpropagation saranno costanti e non dipendenti da Z quindi questo non sarà buono per l’apprendimento.
In questo, il nostro secondo livello è l’output di una funzione lineare dell’input dei livelli precedenti. Aspetta un minuto, cosa abbiamo imparato in questo che se confrontiamo tutti i livelli e rimuoviamo tutti i livelli tranne il primo e l’ultimo, possiamo anche ottenere solo un output che è una funzione lineare del primo livello.
3. ReLU (unità lineare rettificata) Funzione di attivazione
Unità lineare rettificata o ReLU è la funzione di attivazione più utilizzata in questo momento che varia da 0 a infinito, Tutti i valori negativi vengono convertiti in zero e questo tasso di conversione è così veloce che né può mappare né adattarsi correttamente ai dati che crea un problema, ma dove c’è un problema
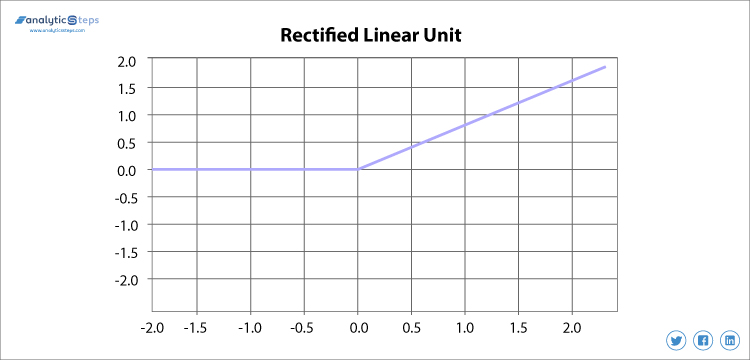
Funzione di attivazione unità lineare rettificata
Usiamo Leaky ReLU funzione invece di ReLU per evitare questo unfitting, in Leaky ReLU gamma è ampliato che migliora le prestazioni.
Funzione di attivazione RELU Leaky
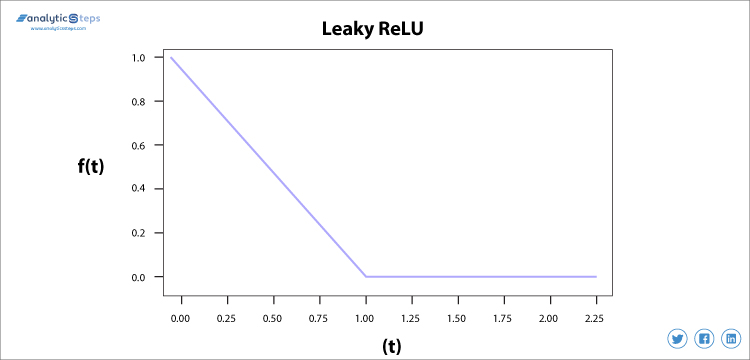
che Perde ReLU Funzione di Attivazione
Abbiamo bisogno di Leaky ReLU funzione di attivazione per risolvere il ‘Morire ReLU’ problema, come discusso in ReLU, osserviamo che tutti i valori di input negativi si trasformano in zero molto rapidamente e, nel caso di Leaky ReLU non facciamo tutti negativi ingressi a zero, ma a un valore vicino a zero, il che risolve il problema principale della ReLU funzione di attivazione.
Funzione di Attivazione Sigmoidale
La funzione di attivazione sigmoidale è usato soprattutto come fa il suo compito con grande efficienza, fondamentalmente, è un approccio probabilistico, verso il processo decisionale e varia da 0 a 1, quindi, quando dobbiamo prendere una decisione o di prevedere un’uscita usiamo questa funzione di attivazione a causa della gamma è il minimo, pertanto, la previsione sarebbe più accurato.
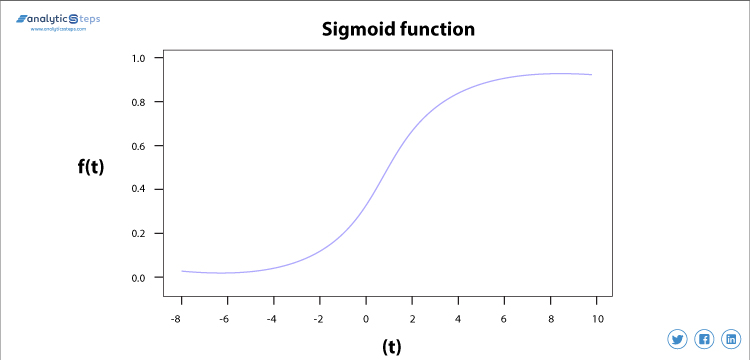
funzione di Attivazione Sigmoidale
L’equazione per la funzione sigmoidea è
f(x) = 1/(1+e(-x) )
La funzione sigmoidea causa di un problema principalmente definito come fuga gradiente problema si verifica perché noi la conversione del segnale in ingresso tra l’intervallo da 0 a 1, e quindi della loro derivati diventare molto più piccoli che non soddisfacenti uscita. Per risolvere questo problema viene utilizzata un’altra funzione di attivazione come ReLU dove non abbiamo un piccolo problema derivato.
Funzione di attivazione tangente iperbolica(Tanh)
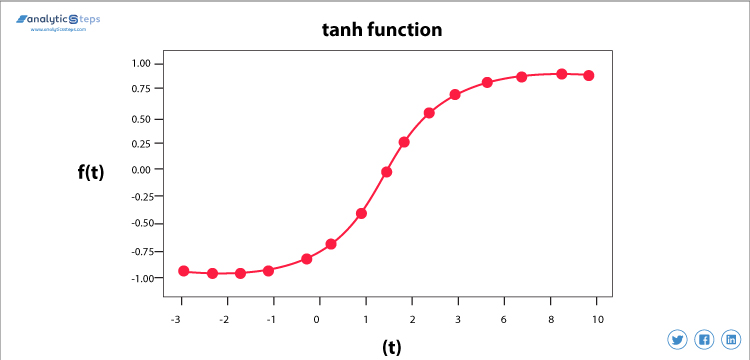
Tanh Activation function
Questa funzione di attivazione è leggermente migliore della funzione sigmoid, come la funzione sigmoid è anche usata per prevedere o distinguere tra due classi ma mappa l’input negativo solo in quantità negativa e varia tra -1 e 1.
Funzione di attivazione Softmax
Softmax viene utilizzato principalmente all’ultimo livello i.e livello di output per il processo decisionale come funziona l’attivazione di sigmoid, il softmax fondamentalmente dà valore alla variabile di input in base al loro peso e la somma di questi pesi è alla fine uno.
Softmax on Binary Classification
Per la classificazione binaria, sia sigmoid, sia softmax, sono ugualmente accessibili, ma in caso di problemi di classificazione multi-classe generalmente usiamo softmax e cross-entropy insieme ad esso.
Conclusione
Le funzioni di attivazione sono quelle funzioni significative che eseguono una trasformazione non lineare all’input e lo rendono abile a comprendere ed eseguire compiti più complessi. Abbiamo discusso 7 funzioni di attivazione utilizzate principalmente con la loro limitazione (se presente), queste funzioni di attivazione sono utilizzate per lo stesso scopo ma in condizioni diverse.