Cos’è l’apprendimento di rinforzo?
L’apprendimento per rinforzo è definito come un metodo di apprendimento automatico che riguarda il modo in cui gli agenti software dovrebbero intraprendere azioni in un ambiente. L’apprendimento di rinforzo è una parte del metodo di apprendimento profondo che ti aiuta a massimizzare una parte della ricompensa cumulativa.
Questo metodo di apprendimento della rete neurale ti aiuta a imparare come raggiungere un obiettivo complesso o massimizzare una dimensione specifica in molti passaggi.
In Reinforcement Learning tutorial, si impara:
- Che cosa è l’apprendimento per rinforzo?
- Termini importanti usati nel metodo di apprendimento di rinforzo profondo
- Come funziona l’apprendimento di rinforzo?
- Rinforzo Algoritmi di Apprendimento
- Caratteristiche di Apprendimento di Rinforzo
- Tipi di Rinforzo di Apprendimento
- Modelli di Apprendimento di Rinforzo
- il Rafforzamento dell’Apprendimento vs Apprendimento Supervisionato
- Applicazioni di Rinforzo di Apprendimento
- Perché utilizzare il Rafforzamento dell’Apprendimento?
- Quando non usare l’apprendimento di rinforzo?
- Sfide di Apprendimento di Rinforzo
i termini più Importanti utilizzati nel Profondo di Rinforzo del metodo di Apprendimento
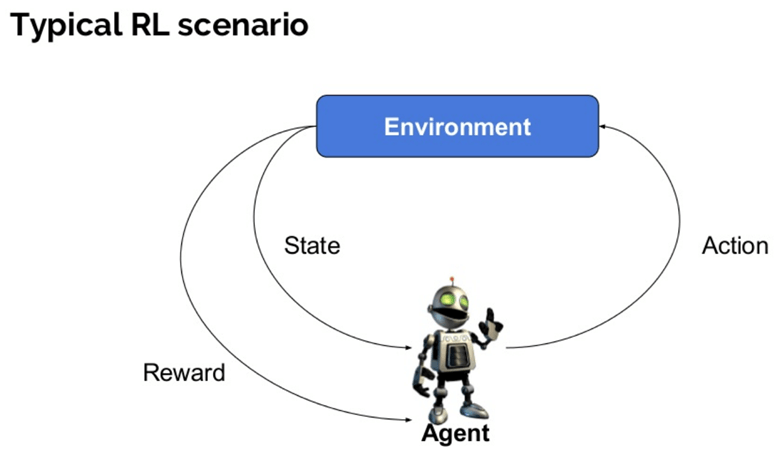
Qui ci sono alcuni importanti termini utilizzati in Rinforzo AI:
- Agente: si tratta di un assunto entità che compie azioni in un ambiente per ottenere qualche ricompensa.
- Ambiente (e): Uno scenario che un agente deve affrontare.
- Ricompensa (R): Un ritorno immediato dato a un agente quando lui o lei esegue un’azione o un compito specifico.
- Stato (i): Lo stato si riferisce alla situazione attuale restituita dall’ambiente.
- Politica (?): È una strategia che si applica dall’agente per decidere l’azione successiva in base allo stato attuale.
- Valore (V): È previsto un rendimento a lungo termine con sconto, rispetto al premio a breve termine.
- Funzione valore: specifica il valore di uno stato che è l’importo totale della ricompensa. È un agente che dovrebbe essere previsto a partire da quello stato.
- Modello dell’ambiente: imita il comportamento dell’ambiente. Ti aiuta a fare inferenze da fare e anche a determinare come si comporterà l’ambiente.
- Metodi basati su modelli: è un metodo per risolvere i problemi di apprendimento per rinforzo che utilizzano metodi basati su modelli.
- Valore Q o valore azione (Q): il valore Q è abbastanza simile al valore. L’unica differenza tra i due è che prende un parametro aggiuntivo come azione corrente.
Come funziona l’apprendimento per rinforzo?
Vediamo qualche semplice esempio che ti aiuta ad illustrare il meccanismo di apprendimento per rinforzo.
Considera lo scenario di insegnare nuovi trucchi al tuo gatto
- Poiché cat non capisce l’inglese o qualsiasi altra lingua umana, non possiamo dirle direttamente cosa fare. Invece, seguiamo una strategia diversa.
- Emuliamo una situazione e il gatto cerca di rispondere in molti modi diversi. Se la risposta del gatto è il modo desiderato, le daremo il pesce.
- Ora ogni volta che il gatto è esposto alla stessa situazione, il gatto esegue un’azione simile con ancora più entusiasmo in attesa di ottenere più ricompensa(cibo).
- È come imparare che il gatto ottiene da “cosa fare” da esperienze positive.
- Allo stesso tempo, il gatto impara anche cosa non fare di fronte a esperienze negative.
Spiegazione sull’esempio:
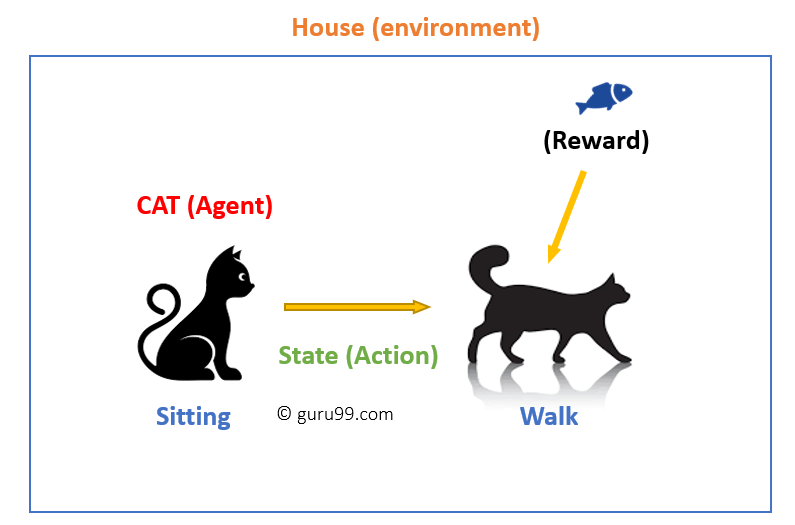
In questo caso,
- il Tuo gatto è un agente che è esposta per l’ambiente. In questo caso, è casa tua. Un esempio di uno stato potrebbe essere il vostro gatto seduto, e si utilizza una parola specifica per gatto a camminare.
- Il nostro agente reagisce eseguendo una transizione di azione da uno “stato” a un altro “stato”.”
- Ad esempio, il tuo gatto passa da seduto a camminare.
- La reazione di un agente è un’azione, e la politica è un metodo di selezione di un’azione dato uno stato in attesa di risultati migliori.
- Dopo la transizione, possono ottenere una ricompensa o una penalità in cambio.
Reinforcement Learning Algorithms
Esistono tre approcci per implementare un algoritmo di Reinforcement Learning.
Basato sul valore:
In un metodo di apprendimento di rinforzo basato sul valore, si dovrebbe cercare di massimizzare una funzione di valore V(s). In questo metodo, l’agente si aspetta un ritorno a lungo termine degli stati attuali nell’ambito della politica ?.
Basato su criteri:
In un metodo RL basato su criteri, si tenta di elaborare una politica tale che l’azione eseguita in ogni stato consente di ottenere la massima ricompensa in futuro.
Due tipi di metodi basati su policy sono:
- Deterministico: per qualsiasi stato, la stessa azione viene prodotta dalla policy ?.
- Stocastico: Ogni azione ha una certa probabilità, che è determinata dalla seguente equazione.Politica stocastica:
n{a\s) = P\A, = a\S, =S]
Basato sul modello:
In questo metodo di apprendimento di rinforzo, è necessario creare un modello virtuale per ogni ambiente. L’agente impara ad esibirsi in quell’ambiente specifico.
Caratteristiche di Apprendimento di Rinforzo
Ecco le caratteristiche importanti di rinforzo di apprendimento
- non C’è nessun supervisore, solo un numero reale, o ricompensa di segnale
- Sequenziale decisionale
- il Tempo gioca un ruolo fondamentale nel Rafforzamento problemi
- Feedback è sempre in ritardo, non istantanea
- Agente di azioni di determinare il i dati che riceve
Tipi di Rinforzo di Apprendimento
Due tipi di rinforzo e di metodi di apprendimento sono:
Positivo:
È definito come un evento, che si verifica a causa di un comportamento specifico. Aumenta la forza e la frequenza del comportamento e influisce positivamente sull’azione intrapresa dall’agente.
Questo tipo di rinforzo ti aiuta a massimizzare le prestazioni e sostenere il cambiamento per un periodo più esteso. Tuttavia, troppo rinforzo può portare a un eccesso di ottimizzazione dello stato, che può influenzare i risultati.
Negativo:
Il rinforzo negativo è definito come rafforzamento del comportamento che si verifica a causa di una condizione negativa che dovrebbe essere interrotta o evitata. Ti aiuta a definire il livello minimo di prestazioni. Tuttavia, lo svantaggio di questo metodo è che fornisce abbastanza per soddisfare il comportamento minimo.
Modelli di apprendimento del rinforzo
Ci sono due importanti modelli di apprendimento nell’apprendimento per rinforzo:
- Processo decisionale Markov
- Q learning
Processo decisionale Markov
I seguenti parametri vengono utilizzati per ottenere una soluzione:
- Set di azioni – A
- Set di stati-S
- Ricompensa – R
- Politica – n
- Valore – V
L’approccio matematico per mappare una soluzione nell’apprendimento per rinforzo è recon come processo decisionale di Markov o (MDP).
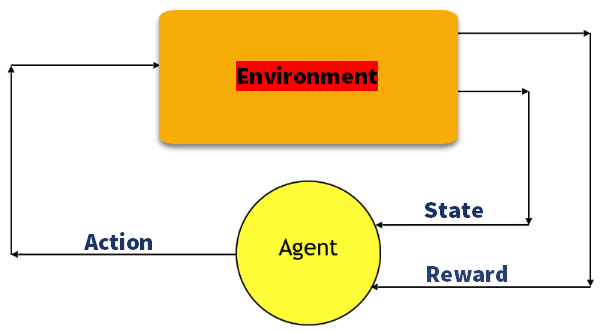
Q-Learning
Q learning è un metodo basato sul valore di fornire informazioni per informare l’azione che un agente deve intraprendere.
Comprendiamo questo metodo con il seguente esempio:
- Ci sono cinque stanze in un edificio che sono collegate da porte.
- Ogni camera è numerata da 0 a 4
- esterno di un edificio può essere una grande area esterna (5)
- Porte numero 1 e 4 all’interno dell’edificio da camera 5
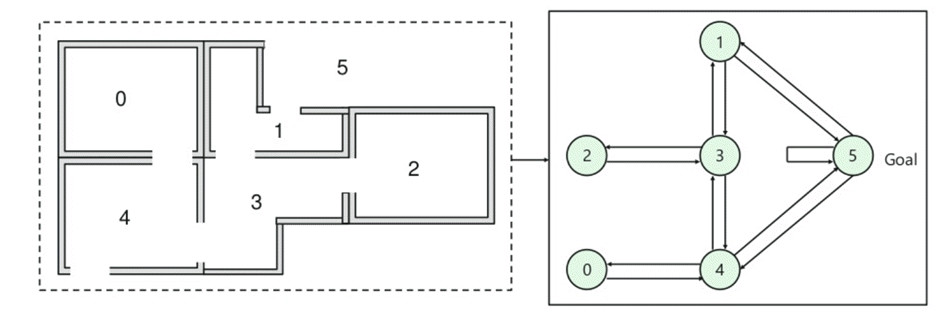
Avanti, è necessario associare una ricompensa al valore a ogni porta:
- Porte che conducono direttamente all’obiettivo di avere una ricompensa di 100
- Porte che non è direttamente collegato con il target sala da zero ricompensa
- Come porte sono a due vie, e le due frecce sono assegnati per ogni camera
- Ogni freccia nell’immagine qui sopra contiene un istante ricompensa valore
Spiegazione:
In questa immagine, è possibile visualizzare che è stato
Agente di movimento da una stanza all’altra rappresenta un’azione
al di sotto della data di immagine, è stato descritto come un nodo, mentre le frecce indicano l’azione.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Apprendimento supervisionato
| Parametri | Apprendimento per rinforzo | Apprendimento supervisionato |
| Stile decisionale | l’apprendimento per rinforzo ti aiuta a prendere le tue decisioni in sequenza. | In questo metodo, viene presa una decisione sull’input dato all’inizio. |
| Funziona su | Funziona sull’interazione con l’ambiente. | Funziona su esempi o dati di esempio. |
| Dipendenza dalla decisione | Nel metodo RL la decisione di apprendimento dipende. Pertanto, dovresti dare etichette a tutte le decisioni dipendenti. | Ha supervisionato l’apprendimento delle decisioni che sono indipendenti l’una dall’altra, quindi vengono fornite etichette per ogni decisione. |
| Più adatto | Supporta e funziona meglio in AI, dove l’interazione umana è prevalente. | È principalmente gestito con un sistema software interattivo o applicazioni. |
| Esempio | Gioco di scacchi | Object recognition |
Applicazioni di Reinforcement Learning
Ecco le applicazioni di Reinforcement Learning:
- Robotica per l’automazione industriale.
- Pianificazione della strategia aziendale
- Apprendimento automatico e elaborazione dati
- Ti aiuta a creare sistemi di formazione che forniscono istruzioni e materiali personalizzati in base alle esigenze degli studenti.
- Controllo aereo e controllo del movimento del robot
Perché usare l’apprendimento per rinforzo?
Ecco i motivi principali per utilizzare l’apprendimento di rinforzo:
- Ti aiuta a trovare quale situazione ha bisogno di un’azione
- Ti aiuta a scoprire quale azione produce la ricompensa più alta nel periodo più lungo.
- Reinforcement Learning fornisce anche l’agente di apprendimento con una funzione di ricompensa.
- Permette anche di capire il metodo migliore per ottenere grandi ricompense.
Quando non usare l’apprendimento per rinforzo?
Non è possibile applicare il modello di apprendimento di rinforzo è tutta la situazione. Qui ci sono alcune condizioni in cui non si dovrebbe usare il modello di apprendimento di rinforzo.
- Quando si dispone di dati sufficienti per risolvere il problema con un metodo di apprendimento supervisionato
- È necessario ricordare che l’apprendimento per rinforzo è computing-pesante e che richiede tempo. in particolare quando lo spazio di azione è grande.
Sfide di Reinforcement Learning
Ecco le principali sfide che dovrai affrontare mentre guadagni di rinforzo:
- Feature/reward design che dovrebbe essere molto coinvolto
- I parametri possono influenzare la velocità di apprendimento.
- Gli ambienti realistici possono avere osservabilità parziale.
- Troppo rinforzo può portare ad un sovraccarico di stati che possono diminuire i risultati.
- Gli ambienti realistici possono essere non stazionari.
Sommario:
- L’apprendimento per rinforzo è un metodo di apprendimento automatico
- Ti aiuta a scoprire quale azione produce la ricompensa più alta nel periodo più lungo.
- Tre metodi per l’apprendimento di rinforzo sono 1) Value-based 2) Policy-based e Model based learning.
- Agent, State, Reward, Environment, Value function Model of the environment, Model based method, sono alcuni termini importanti utilizzati nel metodo di apprendimento RL
- L’esempio di apprendimento per rinforzo è il tuo gatto è un agente che è esposto all’ambiente.
- La più grande caratteristica di questo metodo è che non c’è nessuna autorità di vigilanza, solo un numero reale, o ricompensa di segnale
- Due tipi di rinforzo di apprendimento sono: 1) Positivo 2) Negativo
- Due ampiamente utilizzato il modello di apprendimento sono: 1) il Processo di Decisione di Markov 2) Q di apprendimento
- il Rafforzamento dell’Apprendimento metodo funziona su interagendo con l’ambiente, mentre l’apprendimento supervisionato metodo funziona, dato il campione di dati o di esempio.
- Applicazione o metodi di apprendimento di rinforzo sono: Robotica per l’automazione industriale e la pianificazione della strategia aziendale
- Non si dovrebbe usare questo metodo quando si hanno abbastanza dati per risolvere il problema
- La sfida più grande di questo metodo è che i parametri possono influenzare la velocità di apprendimento