Non è possibile utilizzare facilmente le variabili categoriali come predittori nella regressione lineare: è necessario suddividerle in variabili dicotomiche note come variabili fittizie.
Il modo ideale per creare questi è il nostro strumento di variabili fittizie. Se non si desidera utilizzare questo strumento, allora questo tutorial mostra il modo giusto per farlo manualmente.
- Esempio I – Numerica Variabile
- Esempio II – Variabile Numerica con Adiacente Interi
- Esempio III – Variabile Stringa con la Conversione
- Esempio: IV – Variabile Stringa senza Conversione
Esempio di File di Dati
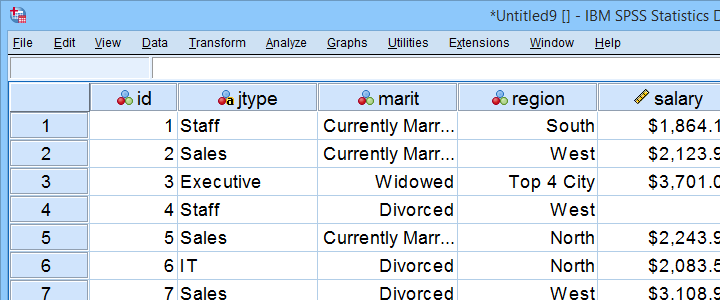
Questo tutorial utilizza personale.sav tutto. Parte di questo file di dati è mostrato di seguito.
Esempio I – Qualsiasi variabile numerica
Creiamo prima variabili fittizie per marit, abbreviazione di stato civile. Il nostro primo passo è eseguire una tabella di frequenze di base confrequenze marit.La tabella seguente mostra la tabella risultante.
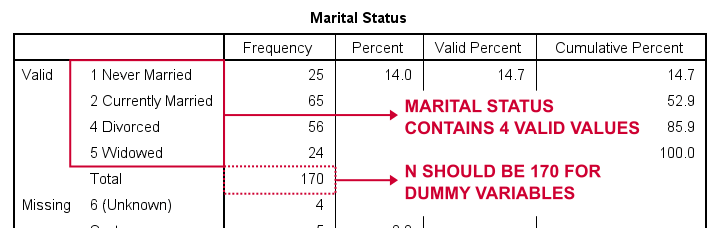
Quindi, come suddividere lo stato civile in variabili fittizie? Prima di tutto, abbiamo sempre omettere una categoria, la categoria di riferimento. Puoi scegliere qualsiasi categoria come categoria di riferimento.
Quindi per questo esempio, scegliamo 5 (Vedovo). Ciò implica che creeremo 3 variabili fittizie che rappresentano le categorie 1, 2 e 4 (si noti che 3 non si verifica in questa variabile).
La sintassi seguente mostra come creare ed etichettare le nostre 3 variabili fittizie. Facciamolo.
calcola marit_1 = (marit = 1).
calcola marit_2 = (marit = 2).
calcola marit_4 = (marit = 4).
*Applica etichette variabili a variabili fittizie.
etichette variabili
marit_1 ‘Stato civile = Mai sposato’
marit_2 ‘Stato civile = Attualmente sposato’
marit_4 ‘Stato civile = Divorziato’.
*Controllo rapido prima variabile fittizia
frequenze marit_1.
Risultati
Prima di tutto, si noti che abbiamo creato 3 variabili fittizie ben etichettate nel nostro set di dati attivo.
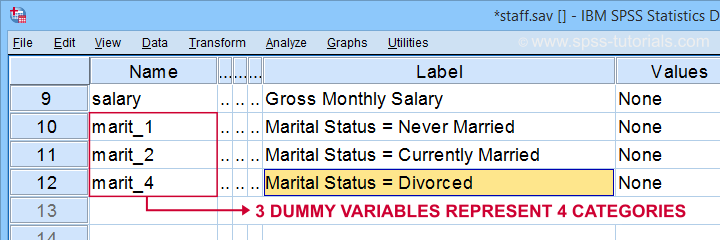
La tabella seguente mostra la distribuzione di frequenza per la nostra prima variabile dummy.

Si noti che la nostra variabile fittizia contiene 3 valori distinti:
- gli intervistati il cui stato civile non è “mai sposato” punteggio 0;
- gli intervistati il cui stato civile è “mai sposato” punteggio 1;
- gli intervistati il cui stato civile è
Ora possiamo controllare i risultati in modo più approfondito eseguendo crosstabs marit da marit_1 a marit_4.In questo modo vengono create 3 tabelle di contingenza, la prima delle quali è mostrata di seguito.
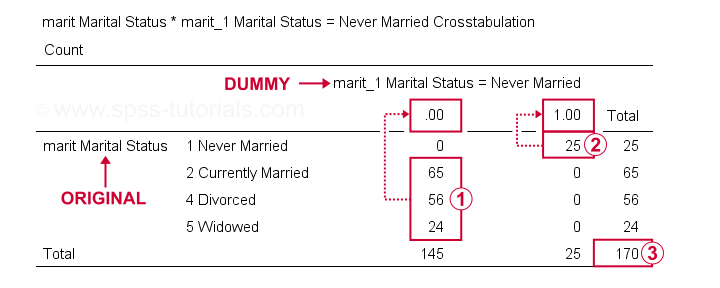
Sulla nostra variabile fittizia,
 gli intervistati che hanno altri stati coniugali rispetto a “non si sono mai sposati” tutti i punteggi 0;
gli intervistati che hanno altri stati coniugali rispetto a “non si sono mai sposati” tutti i punteggi 0; gli intervistati che “non si sono mai sposati” tutti i punteggi 1;
gli intervistati che “non si sono mai sposati” tutti i punteggi 1;
 abbiamo una dimensione del campione di N = 170 (questa tabella include solo i rispondenti senza valori mancanti su entrambe le variabili).
abbiamo una dimensione del campione di N = 170 (questa tabella include solo i rispondenti senza valori mancanti su entrambe le variabili).
Opzionalmente, un controllo finale molto approfondito consiste nel confrontare i risultati di ANOVA per la variabile originale con i risultati di regressione usando le nostre variabili fittizie. La sintassi seguente fa proprio questo, usando lo stipendio mensile come variabile dipendente.
regressione
/stipendio dipendente
/metodo inserisci marit_1 a marit_4.
*ANOVA minima usando la variabile originale.
oneway stipendio da marit .
Si noti che entrambe le analisi risultano in tabelle ANOVA identiche. Discuteremo ANOVA contro la regressione variabile fittizia in modo più approfondito in un tutorial futuro.
Esempio II – Variabile numerica con interi adiacenti
Ora creeremo variabili fittizie per la regione. Ancora una volta, iniziamo ispezionando una tabella di frequenza minima che creeremo eseguendo la regione delle frequenze.Ciò si traduce nella tabella seguente.
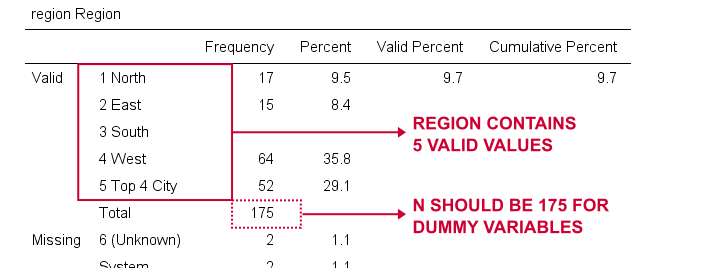
Sceglieremo 1 (“Nord”) come categoria di riferimento. Creeremo quindi variabili fittizie per le categorie da 2 a 5. Poiché questi sono interi adiacenti, possiamo accelerare le cose usando DO REPEAT come mostrato di seguito.
ripetere #vals = 2 a 5 / # vars = region_2 a region_5.
recode region (#vals = 1)(lo thru hi = 0) in #vars.
terminare la stampa di ripetizione.
*Applica etichette variabili a nuove variabili.
etichette variabili
region_2 ‘Region = East’
region_3 ‘Region = South’
region_4 ‘Region = West’
region_5 ‘Region = Top 4 City’.
*Controllo rapido.
tabelle incrociate regione per region_2 a region_5.
Un’attenta ispezione delle tabelle risultanti conferma che tutti i risultati sono corretti.
Esempio III – Variabile stringa con conversione
Purtroppo, i nostri primi 2 metodi non funzionano per variabili stringa come jtype-abbreviazione di “tipo di lavoro”). La soluzione più semplice è convertirla in una variabile numerica come discusso in SPSS Converti stringa in variabile numerica. La sintassi seguente utilizza l’AUTORECODE per completare il lavoro.
autorecode jtype
/in njtype.
*Controllare il risultato.
frequenze njtype.
*Imposta valori mancanti.
valori mancanti njtype (1,2).
*Ricontrollare il risultato.
frequenze njtype.
Risultato

Poiché njtype-abbreviazione di “numeric job type”- è una variabile numerica, ora possiamo usare il metodo I o il metodo II per suddividerlo in variabili dummy.
Esempio IV – Variabile stringa senza conversione
Convertire le variabili stringa in quelle numeriche è facile creare variabili fittizie per loro. Senza questa conversione, il processo è ingombrante perché SPSS non gestisce correttamente i valori mancanti per le variabili stringa. Tuttavia, la sintassi seguente ottiene il lavoro fatto correttamente.
frequenze jtype.
*Possibilità ‘(Sconosciuto) ‘ in ‘NA’.
ricodifica jtype (‘(Sconosciuto)’ = ‘NA’).
*Imposta i valori mancanti dell’utente.
valori mancanti jtype ( ” ,’NA’).
*Reispect frequenze.
frequenze jtype.
*Creare variabili fittizie per la variabile stringa.
se(non manca(jtype)) jtype_1 = (jtype = ‘IT’).
se(non manca(jtype)) jtype_2 = (jtype = ‘Gestione’).
se(non manca(jtype)) jtype_3 = (jtype = ‘Vendite’).
se(non manca(jtype)) jtype_4 = (jtype = ‘Staff’).
*Applica etichette variabili a variabili fittizie.
etichette variabili
jtype_1 ‘Job type = IT’
jtype_2 ‘Job type = Management’
jtype_3 ‘Job type = Sales’
jtype_4 ‘Job type = Staff’.
*Controllare i risultati.
tabelle incrociate jtype da jtype_1 a jtype_4.
Note finali
Creare variabili fittizie per variabili numeriche può essere fatto velocemente e facilmente. L’impostazione di etichette variabili corrette, tuttavia, richiede sempre un po ‘ di lavoro. Le variabili stringa richiedono alcuni passaggi aggiuntivi ma sono anche abbastanza fattibili.
Tuttavia, l’opzione più semplice è il nostro strumento SPSS Create Dummy Variables in quanto si prende cura di tutto.