Informazioni sulla versione: il codice per questa pagina è stato testato in Stata 12.
La regressione di Poisson viene utilizzata per modellare le variabili di conteggio.
Si prega di notare: Lo scopo di questa pagina è quello di mostrare come utilizzare vari comandi di analisi dei dati. Non copre tutti gli aspetti del processo di ricerca che i ricercatori dovrebbero fare. In particolare, non riguarda la pulizia e il controllo dei dati, la verifica delle ipotesi, la diagnostica del modello o le potenziali analisi di follow-up.
Esempi di regressione di Poisson
Esempio 1. Il numero di persone uccise da mulo o cavallo calci nell’esercito prussiano all’anno.Ladislaus Bortkiewicz ha raccolto dati da 20 volumi diPreussischen Statistik. Questi dati sono stati raccolti su 10 corpi dell’esercito prussiano alla fine del 1800 nel corso di 20 anni.
Esempio 2. Il numero di persone in fila di fronte a voi al negozio di alimentari. I predittori possono includere il numero di articoli attualmente offerti a un prezzo speciale scontato e se un evento speciale (ad esempio, una vacanza, un grande evento sportivo) è di tre o meno giorni di distanza.
Esempio 3. Il numero di premi guadagnati dagli studenti di una scuola superiore. I predittori del numero di premi ottenuti includono il tipo di programma in cui lo studente è stato iscritto (ad esempio, professionale, generale o accademico) e il punteggio sul loro esame finale in matematica.
Descrizione dei dati
A scopo illustrativo, abbiamo simulato un set di dati per esempio 3 sopra. In questo esempio, num_awards è la variabile di risultato e indica il numero di premi guadagnati dagli studenti di una scuola superiore in un anno, la matematica è una variabile predittiva continua e rappresenta i punteggi degli studenti sul loro esame finale di matematica, e prog è una variabile predittiva categoriale con tre livelli che indicano il tipo di programma in cui gli studenti
Iniziamo con il caricamento dei dati e guardando alcune statistiche descrittive.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
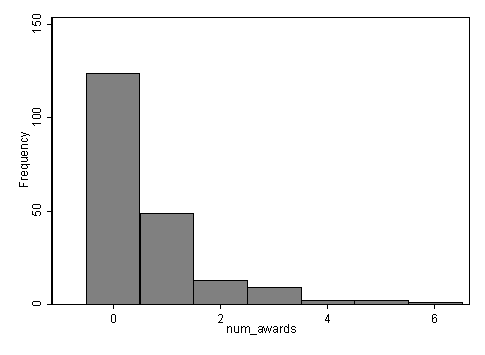
Ogni variabile ha 200 osservazioni valide e le loro distribuzioni sembrano abbastanza ragionevoli. In questo particolare la media incondizionata e la varianza della nostra variabile di risultato non sono estremamente diverse.
Continuiamo con la nostra descrizione delle variabili in questo set di dati. La tabella seguente mostra il numero medio di premi per tipo di programma e sembra suggerire che il tipo di programma è un buon candidato per predire il numero di premi, la nostra variabile di risultato, perché il valore medio del risultato sembra variare in base al prog.
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
metodi di Analisi si potrebbe prendere in considerazione
Di seguito è riportato un elenco di alcuni metodi di analisi che può essere rilevato. Alcuni dei metodi elencati sono abbastanza ragionevoli, mentre altri sono caduti in disgrazia o hanno limitazioni.
- Regressione di Poisson – La regressione di Poisson viene spesso utilizzata per la modellazione dei dati di conteggio. La regressione di Poisson ha una serie di estensioni utili per i modelli di conteggio.
- Regressione binomiale negativa – La regressione binomiale negativa può essere utilizzata per dati di conteggio eccessivamente dispersi, ovvero quando la varianza condizionale supera la media condizionale. Può essere considerato come una generalizzazione della regressione di Poisson poiché ha la stessa struttura media della regressione di Poisson e ha un parametro aggiuntivo per modellare la sovra-dispersione. Se la distribuzione condizionale della variabile di risultato è eccessivamente dispersa, è probabile che gli intervalli di confidenza per la regressione binomiale negativa siano più stretti rispetto a quelli di una regressione di Poisson.
- Modello di regressione zero-gonfiato-I modelli Zero-gonfiati tentano di tenere conto degli zeri in eccesso. In altre parole, si pensa che esistano due tipi di zeri nei dati, “zeri veri” e “zeri in eccesso”. I modelli gonfiati a zero stimano due equazioni contemporaneamente, una per il modello di conteggio e una per gli zeri in eccesso.
- Regressione OLS – Le variabili di risultato del conteggio vengono talvolta trasformate in log e analizzate utilizzando la regressione OLS. Molti problemi sorgono con questo approccio, tra cui la perdita di dati a causa di valori indefiniti generati prendendo il log di zero (che non è definito) e stime distorte.
Regressione di Poisson
Di seguito usiamo il comando poisson per stimare un modello di regressione di Poisson. Il prog i. before indica che è una variabile di fattore (cioè, variabile categoriale), e che dovrebbe essere incluso nel modello come una serie di variabili di indicatore.
Usiamo l’opzione vce(robusta) per ottenere errori standard robusti per le stime dei parametri come raccomandato da Cameron e Trivedi (2009) per controllare la lieve violazione delle ipotesi sottostanti.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
Il test chi-quadrato a due gradi di libertà indica che prog, preso insieme, è un predittore statisticamente significativo di num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
Per aiutare a valutare l’adattamento del modello, il comando estat gof può essere utilizzato per ottenere il test del chi-quadrato di bontà di adattamento. Questo non è un test dei coefficienti del modello (che abbiamo visto nelle informazioni dell’intestazione), ma un test del modulo del modello: il modulo del modello di poisson si adatta ai nostri dati?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
Concludiamo che il modello si adatta ragionevolmente bene perché il test del chi-quadrato di bontà di adattamento non è statisticamente significativo. Se il test fosse stato statisticamente significativo, indicherebbe che i dati non si adattano bene al modello. In quella situazione, possiamo provare a determinare se ci sono variabili predittive omesse, se la nostra ipotesi di linearità è valida e/o se c’è un problema di eccessiva dispersione.
A volte, potremmo voler presentare i risultati di regressione come rapporti di frequenza degli incidenti, possiamo usare l’opzione theirr. Questi valori IRR sono uguali ai nostri coefficienti dall’output sopra esponenziato.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
L’output sopra indica che il tasso di incidenti per 2.prog è 2,96 volte il tasso di incidenti per il gruppo di riferimento (1.prog). Allo stesso modo, il tasso di incidenti per 3.prog è 1,45 volte il tasso di incidenti per il gruppo di riferimento che mantiene costanti le altre variabili. La variazione percentuale del tasso di incidenti di num_awards è un aumento del 7% per ogni aumento di unità in matematica.
Richiama la forma della nostra equazione del modello:
log(num_awards) = Intercept + b1(prog=2) + b2(prog=3) + b3math.
Questo significa:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercetta) * exp(b1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
I coefficienti di avere un effetto additivo nel log(y) scala e il TIR hanno un effetto moltiplicativo y scala.
Per ulteriori informazioni sulle varie metriche in cui possono essere presentati i risultati e l’interpretazione di tali, vedere Modelli di regressione per variabili dipendenti categoriche usando Stata, Seconda edizione di J. Scott Long e Jeremy Freese (2006).
Per capire meglio il modello, possiamo usare il comando margini. Di seguito usiamo il comando margini per calcolare i conteggi previsti ad ogni livello diprog, tenendo tutte le altre variabili (in questo esempio, matematica) nel modello ai loro valori medi.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
Nell’output sopra, vediamo che il numero previsto di eventi per il livello 1 di prog è di circa .21, tenendo la matematica alla sua media. Il numero previsto di eventi per il livello 2 di prog è superiore a .62, e il numero previsto di eventi per il livello 3 di prog è di circa .31. Si noti che il conteggio previsto del livello 2 di prog è (.6249446/.211411) = 2,96 volte superiore al conteggio previsto per il livello 1 di prog. Questo corrisponde a quello che abbiamo visto nella tabella di output IRR.
Di seguito otterremo i conteggi previsti per valori di matematica che vanno da 35 a 75 con incrementi di 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
La tabella sopra mostra che con il prog ai suoi valori osservati e la matematica tenuta a 35 per tutte le osservazioni, il conteggio medio previsto (o il numero medio di premi) è di circa .13; quando math = 75, il conteggio medio previsto è di circa 2,17. Se confrontiamo i conteggi previsti in math = 35 e math = 45, possiamo vedere che il rapporto è (.2644714/.1311326) = 2.017. Questo corrisponde all’IRR di 1.0727 per un cambio di 10 unità: 1.0727^10 = 2.017.
Il comando fitstat scritto dall’utente (così come i comandi estat di Stata) può essere utilizzato per ottenere informazioni aggiuntive che possono essere utili se si desidera confrontare i modelli. È possibile digitare search fitstat per scaricare questo programma (vedere Come posso usare il comando di ricerca per cercare programmi e ottenere ulteriore aiuto? per ulteriori informazioni sull’utilizzo di ricerca).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
È possibile tracciare il numero previsto di eventi con i comandi seguenti. Il grafico indica che il maggior numero di premi sono previsti per quelli nel programma accademico (prog = 2), specialmente se lo studente ha un punteggio matematico alto. Il numero più basso di premi previsti è per gli studenti del programma generale (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
Cose da considerare
- Se overdispersion sembra essere un problema, si dovrebbe innanzitutto verificare se il nostro modello è opportunamente specificato, come da variabili omesse e forme funzionali. Ad esempio, se omettessimo la variabile predittiva progin nell’esempio sopra, il nostro modello sembrerebbe avere un problema con l’eccessiva dispersione. In altre parole, un modello specificato in modo errato potrebbe presentare un sintomo come un problema di dispersione eccessiva.
- Supponendo che il modello sia specificato correttamente, è possibile verificare la presenza di sovradispersione. Esistono diversi modi per farlo, incluso il test del rapporto di verosimiglianza del parametro alfa di sovra-dispersione eseguendo lo stesso modello di regressione usando la distribuzione binomiale negativa (nbreg).
- Una causa comune di eccessiva dispersione è l’eccesso di zeri, che a loro volta sono generati da un ulteriore processo di generazione di dati. In questa situazione, dovrebbe essere considerato il modello gonfiato a zero.
- Se il processo di generazione dei dati non consente alcun 0 (ad esempio il numero di giorni trascorsi in ospedale), un modello troncato a zero potrebbe essere più appropriato.
- I dati di conteggio hanno spesso una variabile di esposizione, che indica il numero di volte in cui l’evento potrebbe essere accaduto. Questa variabile dovrebbe essere incorporata in un modello di Poisson con l’uso dell’opzione exp ().
- La variabile di risultato in una regressione di Poisson non può avere numeri negativi e l’esposizione non può avere 0s.
- In Stata, un modello di Poisson può essere stimato tramite il comando glm con il collegamento log e la famiglia di Poisson.
- È necessario utilizzare il comando glm per ottenere i residui per verificare altre ipotesi del modello di Poisson (vedere Cameron e Trivedi (1998) e Dupont (2002) per ulteriori informazioni).
- Esistono molte diverse misure di pseudo-R-quadrato. Tutti cercano di fornire informazioni simili a quelle fornite da R-squared nella regressione OLS, anche se nessuno di essi può essere interpretato esattamente come viene interpretato R-squared nella regressione OLS. Per una discussione su vari pseudo-R-quadrati, vedi Long e Freese (2006) o la nostra pagina delle FAQ Cosa sono gli pseudo R-quadrati?.
- La regressione di Poisson è stimata tramite la stima della massima verosimiglianza. Di solito richiede una grande dimensione del campione.
Vedi anche
- Output annotato per il comando poisson
- Stata FAQ: Come posso usare countfit nella scelta di un modello di conteggio?
- Stata online manual
- poisson
- Stata FAQs
- Come vengono calcolati gli errori standard e gli intervalli di confidenza per i rapporti di incidenza-tasso (IRR) da poisson e nbreg?
- Cameron, A. C. e Trivedi, P. K. (2009). Microeconometria usando Stata. College Station, TX: Stata Press.
- Cameron, A. C. e Trivedi, P. K. (1998). Analisi di regressione dei dati di conteggio. New York: Cambridge Press.
- Cameron, AC Advances in Count Data Regression Talk for the Applied Statistics Workshop, 28 marzo 2009.http://cameron.econ.ucdavis.edu/racd/count.html.
- Dupont, WD (2002). Modellazione Statistica per ricercatori biomedici: una semplice introduzione all’analisi di dati complessi. New York: Cambridge Press.
- Lungo, J. S. (1997). Modelli di regressione per variabili dipendenti categoriche e limitate.Thousand Oaks, CA: Sage Publications.
- Lungo, J. S. e Freese, J. (2006). Modelli di regressione per variabili dipendenti categoriali utilizzando Stata, Seconda edizione. College Station, TX: Stata Press.