Ciao e benvenuti a una Guida Illustrata per la Lunga Memoria a Breve Termine (LSTM) e Gated Ricorrenti Unità (GRU). Sono Michael, e sono un ingegnere di apprendimento automatico nello spazio assistente vocale AI.
In questo post, inizieremo con l’intuizione alla base di LSTM e GRU. Poi spiegherò i meccanismi interni che consentono a LSTM e GRU di funzionare così bene. Se vuoi capire cosa sta succedendo sotto il cofano per queste due reti, allora questo post è per te.
È anche possibile guardare la versione video di questo post su youtube, se si preferisce.
Le reti neurali ricorrenti soffrono di memoria a breve termine. Se una sequenza è abbastanza lunga, avranno difficoltà a trasportare informazioni dai passaggi temporali precedenti a quelli successivi. Quindi, se si sta tentando di elaborare un paragrafo di testo per fare previsioni, RNN può lasciare fuori informazioni importanti fin dall’inizio.
Durante la propagazione posteriore, le reti neurali ricorrenti soffrono del problema del gradiente di fuga. Gradienti sono valori utilizzati per aggiornare un peso reti neurali. Il problema del gradiente di fuga è quando il gradiente si restringe mentre si propaga nel tempo. Se un valore di gradiente diventa estremamente piccolo, non contribuisce troppo all’apprendimento.

Così in reti neurali ricorrenti, i livelli che ottenere un piccolo gradiente di aggiornamento si interrompe di apprendimento. Quelli sono di solito gli strati precedenti. Quindi, poiché questi strati non imparano, gli RNN possono dimenticare ciò che hanno visto in sequenze più lunghe, avendo così una memoria a breve termine. Se vuoi saperne di più sulla meccanica delle reti neurali ricorrenti in generale, puoi leggere il mio post precedente qui.
LSTM e GRU come soluzione
LSTM e GRU sono stati creati come soluzione alla memoria a breve termine. Hanno meccanismi interni chiamati cancelli che possono regolare il flusso di informazioni.

Queste porte possono imparare che i dati in una sequenza è importante tenere o buttare via. In questo modo, può passare informazioni rilevanti lungo la lunga catena di sequenze per fare previsioni. Quasi tutti i risultati all’avanguardia basati su reti neurali ricorrenti sono raggiunti con queste due reti. LSTM e GRU possono essere trovati nel riconoscimento vocale, sintesi vocale, e la generazione di testo. Puoi anche usarli per generare didascalie per i video.
Ok, quindi alla fine di questo post dovresti avere una solida comprensione del perché LSTM e GRU sono bravi a elaborare lunghe sequenze. Mi avvicinerò a questo con spiegazioni e illustrazioni intuitive ed eviterò il più possibile la matematica.
Intuizione
Ok, iniziamo con un esperimento mentale. Diciamo che stai guardando le recensioni online per determinare se vuoi comprare cereali Life (non chiedermi perché). Prima leggerai la recensione e poi determinerai se qualcuno ha pensato che fosse buono o se fosse cattivo.

Quando leggi la recensione, il tuo cervello inconsciamente si ricorda solo le parole chiave importanti. Raccogli parole come ” incredibile “e” colazione perfettamente bilanciata”. Non ti importa molto di parole come” questo”,” dato”,” tutto”,” dovrebbe”, ecc. Se un amico ti chiede il giorno dopo cosa ha detto la recensione, probabilmente non lo ricorderesti parola per parola. Si potrebbe ricordare i punti principali anche se come “sarà sicuramente l’acquisto di nuovo”. Se sei molto simile a me, le altre parole svaniranno dalla memoria.

E che è essenzialmente ciò che una LSTM o GRU fa. Si può imparare a mantenere solo le informazioni rilevanti per fare previsioni, e dimenticare i dati non rilevanti. In questo caso, le parole che hai ricordato ti hanno fatto giudicare che era buono.
Revisione delle reti neurali ricorrenti
Per capire come LSTM o GRU raggiunge questo, esaminiamo la rete neurale ricorrente. Un RNN funziona in questo modo; Le prime parole vengono trasformate in vettori leggibili dalla macchina. Quindi l’RNN elabora la sequenza di vettori uno per uno.

Durante l’elaborazione, passa il precedente stato nascosto il passaggio successivo della sequenza. Lo stato nascosto agisce come la memoria reti neurali. Contiene informazioni sui dati precedenti che la rete ha visto prima.

vediamo una cella del RNN per vedere come si sarebbe calcolare stato nascosto. Innanzitutto, l’input e lo stato nascosto precedente sono combinati per formare un vettore. Quel vettore ora ha informazioni sull’input corrente e sugli input precedenti. Il vettore passa attraverso l’attivazione tanh e l’output è il nuovo stato nascosto o la memoria della rete.

Tanh di attivazione
Il tanh attivazione è usato per aiutare a regolare i valori che scorre attraverso la rete. La funzione tanh squishes valori per essere sempre tra -1 e 1.

Quando i vettori sono che scorre attraverso una rete neurale, subisce molte trasformazioni a causa di varie operazioni matematiche. Quindi immagina un valore che continua ad essere moltiplicato per diciamo 3. Puoi vedere come alcuni valori possono esplodere e diventare astronomici, facendo sembrare insignificanti altri valori.

Una funzione tanh assicura che i valori di rimanere tra -1 e 1, quindi regolare l’output della rete neurale. Puoi vedere come gli stessi valori dall’alto rimangono tra i limiti consentiti dalla funzione tanh.

in Modo che un RNN. Ha pochissime operazioni internamente ma funziona abbastanza bene date le giuste circostanze (come brevi sequenze). RNN utilizza molte meno risorse computazionali rispetto alle varianti evolute, LSTM e GRU.
LSTM
Un LSTM ha un flusso di controllo simile a una rete neurale ricorrente. Elabora i dati che trasmettono informazioni mentre si propagano in avanti. Le differenze sono le operazioni all’interno delle celle di LSTM.

Queste operazioni vengono utilizzati per consentire la LSTM per mantenere o dimenticate informazioni. Ora guardando queste operazioni può ottenere un po ‘ opprimente quindi andremo oltre questo passo dopo passo.
Concetto di base
Il concetto di base di LSTM sono lo stato della cella, ed è varie porte. Lo stato della cella agisce come un’autostrada di trasporto che trasferisce le informazioni relative lungo la catena di sequenza. Puoi pensarlo come la “memoria” della rete. Lo stato della cella, in teoria, può trasportare informazioni rilevanti durante l’elaborazione della sequenza. Quindi, anche le informazioni dai passaggi temporali precedenti possono rendere il modo di passaggi temporali successivi, riducendo gli effetti della memoria a breve termine. Mentre lo stato della cella continua il suo viaggio, le informazioni vengono aggiunte o rimosse allo stato della cella tramite le porte. Le porte sono diverse reti neurali che decidono quali informazioni sono consentite sullo stato della cella. Le porte possono imparare quali informazioni sono rilevanti per mantenere o dimenticare durante l’allenamento.
Sigmoid
Gates contiene attivazioni sigmoid. Un’attivazione sigmoidea è simile all’attivazione tanh. Invece di squishing valori tra -1 e 1, squishes valori tra 0 e 1. Questo è utile per aggiornare o dimenticare i dati perché qualsiasi numero moltiplicato per 0 è 0, causando la scomparsa dei valori o la “dimenticanza”.”Qualsiasi numero moltiplicato per 1 è lo stesso valore, quindi quel valore rimane lo stesso o è “mantenuto.”La rete può imparare quali dati non sono importanti, quindi possono essere dimenticati o quali dati sono importanti da conservare.

Cerchiamo di scavare un po ‘ più in profondità ciò che le varie porte stanno facendo, che ne dite? Quindi abbiamo tre porte diverse che regolano il flusso di informazioni in una cella LSTM. Un dimenticare cancello, cancello di ingresso, e cancello di uscita.
Forget gate
Per prima cosa, abbiamo il forget gate. Questo cancello decide quali informazioni dovrebbero essere gettate via o conservate. Le informazioni dallo stato nascosto precedente e le informazioni dall’ingresso corrente vengono passate attraverso la funzione sigmoid. I valori escono tra 0 e 1. Più vicino a 0 significa dimenticare e più vicino a 1 significa mantenere.

Porta di ingresso
Per aggiornare lo stato della cellula, abbiamo la porta di ingresso. Innanzitutto, passiamo lo stato nascosto precedente e l’ingresso corrente in una funzione sigmoidea. Questo decide quali valori verranno aggiornati trasformando i valori in 0 e 1. 0 significa non importante e 1 significa importante. Si passa anche lo stato nascosto e l’ingresso corrente nella funzione tanh per squish valori tra -1 e 1 per aiutare a regolare la rete. Quindi moltiplichi l’output tanh con l’output sigmoid. L’output sigmoid deciderà quali informazioni è importante mantenere dall’output tanh.

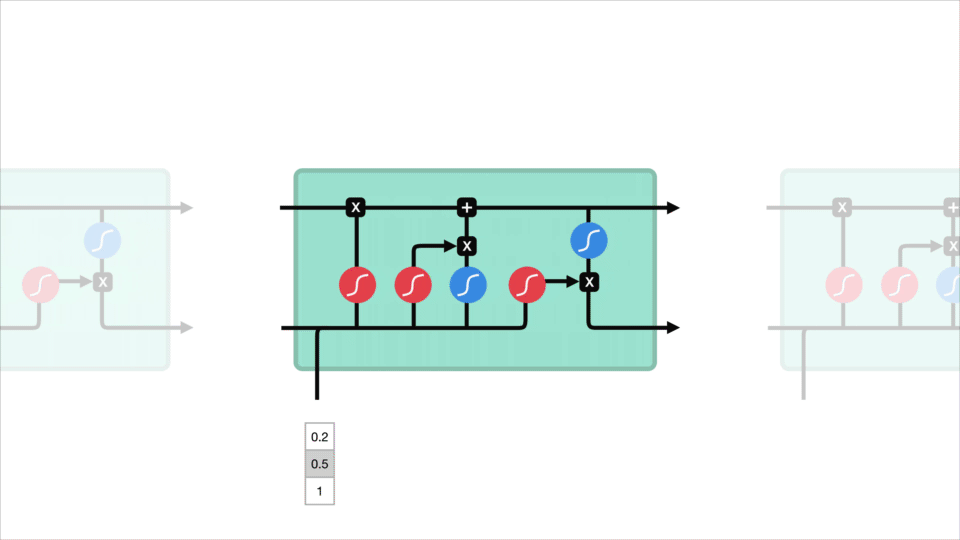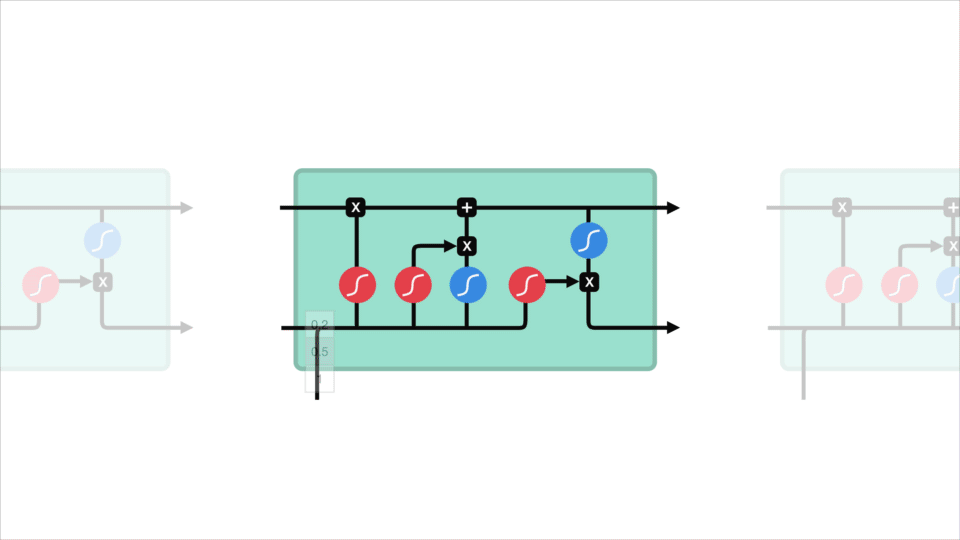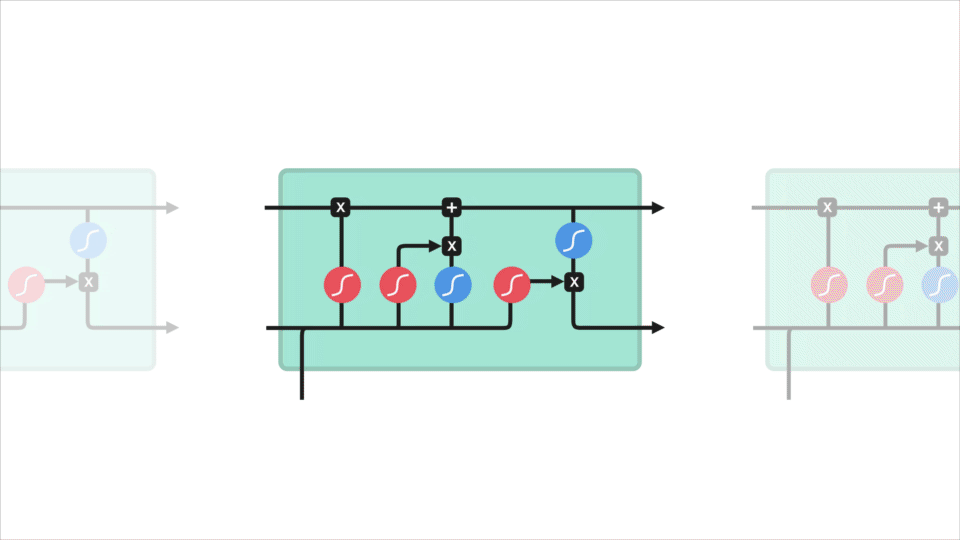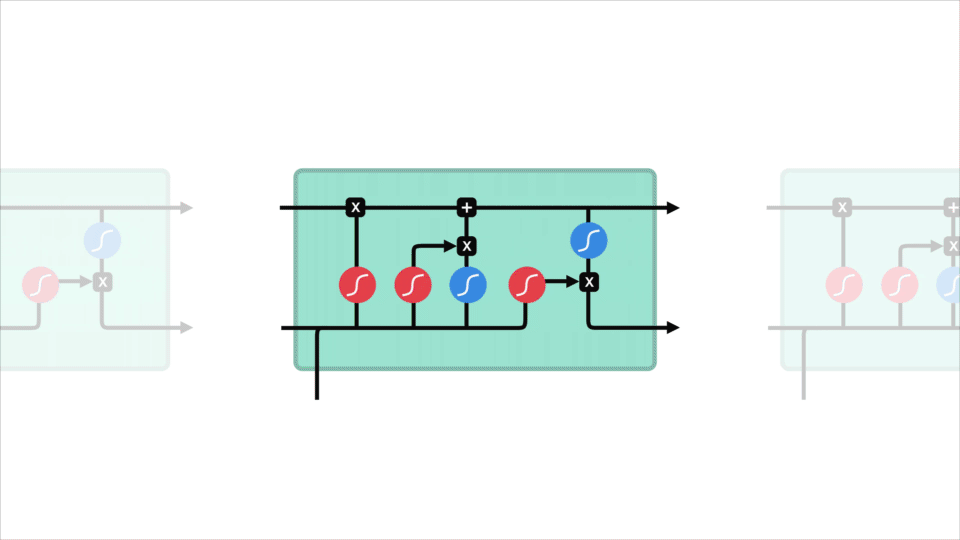
Cella di Stato
Ora si deve disporre di informazioni sufficienti per calcolare lo stato della cellula. Innanzitutto, lo stato della cella viene moltiplicato per il vettore di dimenticanza. Questo ha la possibilità di eliminare i valori nello stato della cella se viene moltiplicato per valori vicini a 0. Quindi prendiamo l’output dal gate di input e facciamo un’aggiunta puntuale che aggiorna lo stato della cella a nuovi valori che la rete neurale trova rilevanti. Questo ci dà il nostro nuovo stato cellulare.

Uscita
infine, l’uscita. Il gate di output decide quale dovrebbe essere il prossimo stato nascosto. Ricorda che lo stato nascosto contiene informazioni sugli input precedenti. Lo stato nascosto viene utilizzato anche per le previsioni. Innanzitutto, passiamo lo stato nascosto precedente e l’ingresso corrente in una funzione sigmoidea. Quindi passiamo lo stato della cella appena modificato alla funzione tanh. Moltiplichiamo l’output tanh con l’output sigmoid per decidere quali informazioni dovrebbe portare lo stato nascosto. L’output è lo stato nascosto. Il nuovo stato della cella e il nuovo nascosto vengono quindi riportati al passaggio successivo.

Per rivedere, il Dimenticare cancello decide ciò che è rilevante per mantenere i precedenti passaggi. Il gate di input decide quali informazioni sono rilevanti da aggiungere dal passaggio corrente. Il gate di output determina quale dovrebbe essere il prossimo stato nascosto.
Code Demo
Per quelli di voi che capiscono meglio vedendo il codice, ecco un esempio usando lo pseudo codice python.

1. Innanzitutto, lo stato nascosto precedente e l’input corrente vengono concatenati. La chiameremo combine.
2. Combina get inserito nel livello dimentica. Questo livello rimuove i dati non rilevanti.
4. Un livello candidato viene creato utilizzando combina. Il candidato contiene i possibili valori da aggiungere allo stato della cella.
3. Combina anche i get inseriti nel livello di input. Questo livello decide quali dati del candidato devono essere aggiunti al nuovo stato della cella.
5. Dopo aver calcolato il livello dimentica, il livello candidato e il livello di input, lo stato della cella viene calcolato utilizzando tali vettori e lo stato della cella precedente.
6. L’output viene quindi calcolato.
7. Moltiplicando in modo puntuale l’output e il nuovo stato della cella ci dà il nuovo stato nascosto.
Questo è tutto! Il flusso di controllo di una rete LSTM sono alcune operazioni del tensore e un ciclo for. È possibile utilizzare gli stati nascosti per le previsioni. Combinando tutti questi meccanismi, un LSTM può scegliere quali informazioni sono rilevanti da ricordare o dimenticare durante l’elaborazione della sequenza.
GRU
Quindi ora sappiamo come funziona un LSTM, diamo un’occhiata brevemente al GRU. Il GRU è la nuova generazione di reti neurali ricorrenti ed è abbastanza simile a un LSTM. GRU si è sbarazzata dello stato della cella e ha usato lo stato nascosto per trasferire informazioni. Ha anche solo due porte, un cancello di reset e un cancello di aggiornamento.

Aggiornamento Gate
L’aggiornamento porta simile a dimenticare, e la porta di ingresso di un LSTM. Decide quali informazioni buttare via e quali nuove informazioni aggiungere.
Reset Gate
Il reset gate è un altro gate viene utilizzato per decidere quante informazioni passate dimenticare.
E questo è un GRU. GRU ha meno operazioni del tensore; pertanto, sono un po ‘ più veloci da addestrare poi LSTM. Non c’è un chiaro vincitore quale sia meglio. I ricercatori e gli ingegneri di solito cercano entrambi di determinare quale funziona meglio per il loro caso d’uso.
Quindi è così
Per riassumere, gli RNN sono buoni per l’elaborazione dei dati di sequenza per le previsioni ma soffrono di memoria a breve termine. LSTM e GRU sono stati creati come un metodo per mitigare la memoria a breve termine utilizzando meccanismi chiamati gates. Le porte sono solo reti neurali che regolano il flusso di informazioni che scorre attraverso la catena di sequenza. LSTM e GRU sono utilizzati in applicazioni di apprendimento profondo state of the art come il riconoscimento vocale, sintesi vocale, comprensione del linguaggio naturale, ecc.
Se sei interessato ad approfondire, ecco i link di alcune fantastiche risorse che possono darti una prospettiva diversa nella comprensione di LSTM e GRU. Questo post è stato fortemente ispirato da loro.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/