di William W Wold
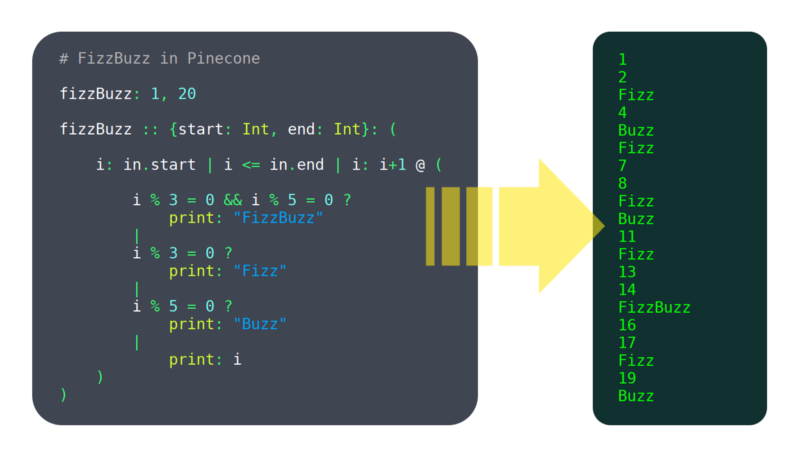
Negli ultimi 6 mesi, ho lavorato su un linguaggio di programmazione chiamato Pinecone. Non lo chiamerei ancora maturo, ma ha già abbastanza funzioni che funzionano per essere utilizzabili, come ad esempio:
- variabili
- funzioni
- strutture definite dall’utente
Se sei interessato, controlla la pagina di destinazione di Pinecone o il suo repository GitHub.
Non sono un esperto. Quando ho iniziato questo progetto, non avevo idea di quello che stavo facendo, e ancora non lo faccio. Ho preso zero lezioni sulla creazione di lingue, ho letto solo un po ‘ su di esso online, e non ho seguito gran parte dei consigli che mi sono stati dati.
Eppure, ho ancora fatto un linguaggio completamente nuovo. E funziona. Quindi devo fare qualcosa di giusto.
In questo post, mi immergerò sotto il cofano e vi mostrerò la pipeline Pigna (e altri linguaggi di programmazione) utilizzare per trasformare il codice sorgente in magia.
Toccherò anche alcuni dei compromessi che ho fatto e perché ho preso le decisioni che ho fatto.
Questo non è affatto un tutorial completo sulla scrittura di un linguaggio di programmazione, ma è un buon punto di partenza se sei curioso dello sviluppo del linguaggio.
Guida introduttiva
“Non ho assolutamente idea di dove vorrei iniziare” è qualcosa che sento molto quando dico ad altri sviluppatori che sto scrivendo una lingua. Nel caso in cui questa sia la tua reazione, ora passerò attraverso alcune decisioni iniziali che vengono prese e passi che vengono presi quando si inizia una nuova lingua.
Compilato vs interpretato
Esistono due tipi principali di linguaggi: compilato e interpretato:
- Un compilatore capisce tutto ciò che un programma farà, lo trasforma in “codice macchina” (un formato che il computer può eseguire molto velocemente), quindi lo salva per essere eseguito in seguito.
- Un interprete passa attraverso il codice sorgente riga per riga, capendo cosa sta facendo mentre va.
Tecnicamente qualsiasi linguaggio potrebbe essere compilato o interpretato, ma l’uno o l’altro di solito ha più senso per un linguaggio specifico. Generalmente, l’interpretazione tende ad essere più flessibile, mentre la compilazione tende ad avere prestazioni più elevate. Ma questo è solo graffiare la superficie di un argomento molto complesso.
Apprezzo molto le prestazioni e ho visto una mancanza di linguaggi di programmazione che sono sia ad alte prestazioni che orientati alla semplicità, quindi sono andato con compiled for Pinecone.
Questa è stata una decisione importante da prendere presto, perché molte decisioni di progettazione del linguaggio sono influenzate da esso (ad esempio, la tipizzazione statica è un grande vantaggio per i linguaggi compilati, ma non tanto per quelli interpretati).
Nonostante il fatto che Pinecone sia stato progettato pensando alla compilazione, ha un interprete completamente funzionale che era l’unico modo per eseguirlo per un po’. Ci sono una serie di ragioni per questo, che spiegherò più avanti.
Scegliendo una lingua
So che è un po ‘ meta, ma un linguaggio di programmazione è esso stesso un programma, e quindi è necessario scriverlo in una lingua. Ho scelto C++ per le sue prestazioni e l’ampio set di funzionalità. Inoltre, in realtà mi piace lavorare in C++.
Se stai scrivendo un linguaggio interpretato, ha molto senso scriverlo in uno compilato (come C, C++ o Swift) perché le prestazioni perse nella lingua del tuo interprete e l’interprete che sta interpretando il tuo interprete si aggraveranno.
Se si prevede di compilare, un linguaggio più lento (come Python o JavaScript) è più accettabile. Il tempo di compilazione potrebbe essere negativo, ma a mio parere non è un grosso problema come il cattivo tempo di esecuzione.
High Level Design
Un linguaggio di programmazione è generalmente strutturato come una pipeline. Cioè, ha diverse fasi. Ogni fase ha dati formattati in un modo specifico e ben definito. Ha anche funzioni per trasformare i dati da ogni fase a quella successiva.
Il primo stadio è una stringa contenente l’intero file sorgente di input. La fase finale è qualcosa che può essere eseguito. Tutto questo diventerà chiaro mentre attraversiamo la pipeline di Pigna passo dopo passo.
Lexing

Il primo passo nella maggior parte dei linguaggi di programmazione è il lexing, o la tokenizzazione. ‘Lex’ è l’abbreviazione di analisi lessicale, una parola molto elegante per dividere un gruppo di testo in token. La parola ‘tokenizer ‘ha molto più senso, ma’ lexer ‘ è così divertente da dire che lo uso comunque.
Token
Un token è una piccola unità di una lingua. Un token potrebbe essere un nome di variabile o funzione (OVVERO un identificatore), un operatore o un numero.
Compito del Lexer
Il lexer dovrebbe prendere una stringa contenente un intero file di codice sorgente e sputare una lista contenente ogni token.
Le fasi future della pipeline non faranno riferimento al codice sorgente originale, quindi il lexer deve produrre tutte le informazioni necessarie a loro. Il motivo di questo formato di pipeline relativamente rigoroso è che il lexer può eseguire attività come la rimozione di commenti o il rilevamento se qualcosa è un numero o un identificatore. Vuoi mantenere quella logica bloccata all’interno del lexer, entrambi in modo da non dover pensare a queste regole quando scrivi il resto della lingua, e quindi puoi cambiare questo tipo di sintassi tutto in un unico posto.
Flex
Il giorno in cui ho iniziato la lingua, la prima cosa che ho scritto è stato un semplice lexer. Poco dopo, ho iniziato a conoscere strumenti che presumibilmente renderebbero il lexing più semplice e meno buggy.
Lo strumento predominante è Flex, un programma che genera lexer. Gli dai un file che ha una sintassi speciale per descrivere la grammatica della lingua. Da ciò genera un programma C che lex una stringa e produce l’output desiderato.
La mia decisione
Ho optato per mantenere il lexer che ho scritto per il momento. Alla fine, non ho visto vantaggi significativi nell’utilizzo di Flex, almeno non abbastanza da giustificare l’aggiunta di una dipendenza e complicare il processo di compilazione.
Il mio lexer è lungo solo poche centinaia di righe e raramente mi dà problemi. Rolling my own lexer mi dà anche una maggiore flessibilità, come la possibilità di aggiungere un operatore alla lingua senza modificare più file.
Analisi

Il secondo stadio della pipeline è il parser. Il parser trasforma un elenco di token in un albero di nodi. Un albero utilizzato per memorizzare questo tipo di dati è noto come albero di sintassi astratto o AST. Almeno in Pigna, l’AST non ha alcuna informazione sui tipi o quali identificatori sono quali. Si tratta semplicemente di token strutturati.
Funzioni di parser
Il parser aggiunge struttura all’elenco ordinato di token prodotti dal lexer. Per interrompere le ambiguità, il parser deve tenere conto delle parentesi e dell’ordine delle operazioni. Semplicemente l’analisi degli operatori non è terribilmente difficile, ma man mano che vengono aggiunti più costrutti del linguaggio, l’analisi può diventare molto complessa.
Bison
Ancora una volta, c’è stata una decisione da prendere coinvolgendo una libreria di terze parti. La libreria di analisi predominante è Bison. Bison funziona molto come Flex. Scrivi un file in un formato personalizzato che memorizza le informazioni grammaticali, quindi Bison lo usa per generare un programma C che eseguirà l’analisi. Non ho scelto di usare il Bisonte.
Perché Custom è meglio
Con il lexer, la decisione di usare il mio codice era abbastanza ovvia. Un lexer è un programma così banale che non scrivere il mio sembrava quasi sciocco come non scrivere il mio ‘left-pad’.
Con il parser, è una questione diversa. Il mio parser Pigna è attualmente lungo 750 righe, e ne ho scritte tre perché le prime due erano spazzatura.
Originariamente ho preso la mia decisione per una serie di motivi, e mentre non è andato completamente liscio, la maggior parte di loro è vera. I principali sono i seguenti:
- Minimizza il cambio di contesto nel flusso di lavoro: il cambio di contesto tra C++ e Pinecone è abbastanza grave senza inserire la grammatica di Bison grammatica
- Mantieni la compilazione semplice: ogni volta che la grammatica cambia Bison deve essere eseguito prima della compilazione. Questo può essere automatizzato, ma diventa un dolore quando si passa tra i sistemi di costruzione.
- Mi piace costruire merda fresca: non ho fatto Pigna perché pensavo che sarebbe stato facile, quindi perché dovrei delegare un ruolo centrale quando potrei farlo da solo? Un parser personalizzato potrebbe non essere banale, ma è completamente fattibile.
All’inizio non ero completamente sicuro se stavo percorrendo un percorso praticabile, ma mi è stata data fiducia da ciò che Walter Bright (uno sviluppatore su una prima versione di C++ e il creatore del linguaggio D) aveva da dire sull’argomento:
“Un po’ più controverso, non mi preoccuperei di perdere tempo con i generatori lexer o parser e altri cosiddetti “compilatori compilatori.”Sono una perdita di tempo. Scrivere un lexer e un parser è una piccola percentuale del lavoro di scrittura di un compilatore. L’utilizzo di un generatore richiederà circa tanto tempo quanto scriverne uno a mano, e ti sposerà con il generatore (che è importante quando si porta il compilatore su una nuova piattaforma). E i generatori hanno anche la sfortunata reputazione di emettere messaggi di errore schifosi.”
Action Tree
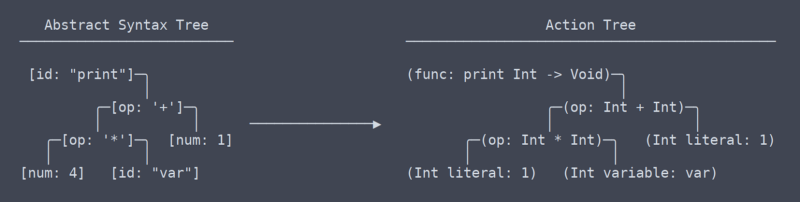
Ora abbiamo lasciato l’area dei termini comuni e universali, o almeno non lo so quali sono i termini sono più. Dalla mia comprensione, quello che chiamo l ‘ “albero delle azioni” è più simile all’IR di LLVM (rappresentazione intermedia).
C’è una differenza sottile ma molto significativa tra l’albero delle azioni e l’albero della sintassi astratta. Mi ci è voluto un po ‘ per capire che ci dovrebbe essere anche una differenza tra loro (che ha contribuito alla necessità di riscrivere il parser).
Action Tree vs AST
In parole povere, l’albero delle azioni è l’AST con il contesto. Quel contesto è informazioni come il tipo restituito da una funzione o che due punti in cui viene utilizzata una variabile stanno effettivamente utilizzando la stessa variabile. Poiché ha bisogno di capire e ricordare tutto questo contesto, il codice che genera l’albero delle azioni ha bisogno di molte tabelle di ricerca dello spazio dei nomi e altri thingamabobs.
Eseguire l’albero delle azioni
Una volta che abbiamo l’albero delle azioni, eseguire il codice è facile. Ogni nodo di azione ha una funzione ‘execute’ che prende un input, fa tutto ciò che l’azione dovrebbe (inclusa eventualmente la chiamata sub action) e restituisce l’output dell’azione. Questo è l’interprete in azione.
Opzioni di compilazione
” Ma aspetta!”Ti sento dire”, Pigna non dovrebbe essere compilata?”Sì, lo è. Ma compilare è più difficile che interpretare. Ci sono alcuni approcci possibili.
Costruisci il mio compilatore
All’inizio mi sembrava una buona idea. Mi piace fare le cose da solo, e ho cercato una scusa per diventare bravo in assemblea.
Sfortunatamente, scrivere un compilatore portatile non è facile come scrivere del codice macchina per ogni elemento del linguaggio. A causa del numero di architetture e sistemi operativi, non è pratico per qualsiasi individuo scrivere un backend compilatore multipiattaforma.
Anche i team dietro Swift, Rust e Clang non vogliono preoccuparsi di tutto da soli, quindi invece usano tutti LL
LLVM
LLVM è una raccolta di strumenti del compilatore. È fondamentalmente una libreria che trasformerà la tua lingua in un binario eseguibile compilato. Sembrava la scelta perfetta, così ho saltato a destra in. Purtroppo non ho controllato quanto fosse profonda l’acqua e sono immediatamente annegato.
LLVM, pur non essendo un linguaggio assembly rigido, è una gigantesca libreria complessa. Non è impossibile da usare, e hanno buoni tutorial, ma ho capito che avrei dovuto fare pratica prima di essere pronto a implementare completamente un compilatore Pigna con esso.
Transpiling
Volevo una sorta di pigna compilata e la volevo veloce, quindi mi sono rivolto a un metodo che sapevo di poter fare lavoro: transpiling.
Ho scritto una pigna al transpiler C++ e ho aggiunto la possibilità di compilare automaticamente la sorgente di output con GCC. Questo attualmente funziona per quasi tutti i programmi Pigna (anche se ci sono alcuni casi limite che lo rompono). Non è una soluzione particolarmente portatile o scalabile, ma funziona per il momento.
Future
Supponendo che continui a sviluppare Pinecone, prima o poi otterrà il supporto per la compilazione di LLVM. Sospetto che non sia mater quanto lavoro su di esso, il transpiler non sarà mai completamente stabile e i benefici di LLVM sono numerosi. È solo una questione di quando ho il tempo di fare alcuni progetti di esempio in LLVM e ottenere il blocco di esso.
Fino ad allora, l’interprete è ottimo per programmi banali e il transpiling in C++ funziona per la maggior parte delle cose che richiedono più prestazioni.
Conclusione
Spero di aver reso i linguaggi di programmazione un po ‘ meno misteriosi per te. Se si vuole fare uno da soli, lo consiglio vivamente. Ci sono un sacco di dettagli di implementazione da capire, ma il contorno qui dovrebbe essere sufficiente per farti andare avanti.
Ecco il mio consiglio di alto livello per iniziare (ricorda, non so davvero cosa sto facendo, quindi prendilo con un pizzico di sale):
- In caso di dubbio, vai interpretato. I linguaggi interpretati sono generalmente più facili da progettare, costruire e imparare. Non ti sto scoraggiando dal scriverne uno compilato se sai che è quello che vuoi fare, ma se sei sul recinto, andrei interpretato.
- Quando si tratta di lexer e parser, fai quello che vuoi. Ci sono argomenti validi a favore e contro la scrittura del proprio. Alla fine, se pensi al tuo design e implementi tutto in modo sensato, non ha molta importanza.
- Impara dalla pipeline con cui ho finito. Un sacco di tentativi ed errori sono andati a progettare la pipeline che ho ora. Ho tentato di eliminare ASTs, ASTs che si trasformano in azioni alberi sul posto, e altre idee terribili. Questa pipeline funziona, quindi non cambiarla a meno che tu non abbia una buona idea.
- Se non hai il tempo o la motivazione per implementare un linguaggio generico complesso, prova a implementare un linguaggio esoterico come Brainfuck. Questi interpreti possono essere brevi come poche centinaia di righe.
Ho pochissimi rimpianti quando si tratta di sviluppo Pigna. Ho fatto una serie di scelte sbagliate lungo la strada, ma ho riscritto la maggior parte del codice influenzato da tali errori.
In questo momento, Pinecone è in uno stato abbastanza buono da funzionare bene e può essere facilmente migliorato. Scrivere Pigna è stata un’esperienza estremamente educativa e piacevole per me, ed è solo l’inizio.